 1
Motivation und Einführung
1
Motivation und EinführungDer Begriff des e-Business als Abkürzung des englischsprachigen electronic Business
hat sich inzwischen als Subsumption aller für ein Unternehmen wertschöpfenden Aktivitäten im Internet eingebürgert.
Die Sinngebung greift damit weiter als der historisch
ältere Begriff
e-Commerce,
welcher ursprünglich ausschließlich
Verkaufsaktivitäten bezeichnete. Inzwischen werden beide
Terme jedoch nahezu synonym verwendet. Teilweise findet sich für
den Teilbereich des internetgestützten Verkaufs von Waren und
Dienstleistungen an Endkunden auch die Bezeichnung e-tailing
(für electronic retailing) welcher jedoch nur
einen Teilaspekt des e-Commercebegriffes abzudecken
vermag.
 | Definition 1: e-Business |
Electronic Business ist die Gesamtheit aller
unternehmerischen Aktivitäten im Internet.
|
![]()
Gemäß dieser allgemeinen Definition werden sämtliche
auf das Unternehmensziel gerichtete nach außen wirkende Aktivitäten als
e-Business eingeordnet.
Gleichzeitig ergibt sich aus der Abstützung auf der Realisierungstechnik des Internets auch
eine interne Sichtweise, sobald diese Technik
innerhalb des Unternehmens zum Einsatz kommt.
Die Darstellung der Abbildung 1
unternimmt den Versuch der Einordnung der sich ergebenen
Anwendungsdimensionen des e-Businessbegriffs.

Die naheliegendste Form des e-Business ist der
Geschäftsverkehr mit dem (End-)Kunden, als dem typischen
Konsumenten der durch ein Unternehmen zur Verfügung
gestellten Güter und Dienstleistungen. Dieser Teilbereich
wird mit dem Begriff Business-to-Customer
(B2C) belegt.
In diese e-Businessvariante fallen alle Interaktionen
zwischen Kunde und Unternehmen während des gesamten
Lebenszyklus des angebotenen Produkts, angefangen von
verkaufsfördernden Maßnahmen (Marketing) über den
Verkaufs- bzw. Dienstleistungserbringungsakt selbst bis
hin zur Abwicklung der Wartung, soweit nach Art des
angebotenen Gutes elektronisch überhaupt möglich.
Entgegengesetzt zum durch ein Unternehmen produzierten ausgehenden Güter- und
Dienstleistungsstrom verläuft die Beschaffung von
nicht-menschlichen Produktionsfaktoren wie Roh-, Hilfs-
und Betriebsstoffen sowie die
Interunternehmenskommunikation. Dieser Teilbereich wird
mit dem Begriff
Business-to-Business (B2B)
belegt.
In diese e-Businessvariante fallen die zwischen
Unternehmungen ablaufenden elektronischen Kommunikationen.
Die Spannbreite reicht hierbei von der kostenfrei nutzbaren statischen
Präsentation des Güter- und Dienstleistungsangebots im Stile eines Katalogs über
spezialisierte Marktplätze mit Angebots- und
Nachfragefunktionalitäten bis hin zu
Informationsdienstleistungen welche Zugriff auf die
datenhaltenden Systeme des Geschäftspartners gewähren.
Die umfassende Betrachtung der zuvor ausgeklammerten
Kommunikation mit potentiellen und bestehenden
Mitarbeitern konstituiert die dritte Klasse der
e-Businessanwendungen, welche auf die
unternehmensinterne Kommunikation mit den Mitarbeitern
fokussieren. Dieser Teilbereich wird mit dem Begriff
Business-to-Employee
(B2E) belegt.
Dieser Sparte werden alle elektronischen
Informationsangebote an den Mitarbeiter, wie Auskunft über
den aktuellen Gleitzeitstand, Adressstamm- sowie
Gehaltsdaten, zugeordnet.
Orthogonal zu den drei Anwendungsdimensionen
verdient die ebenfalls in Abbildung 1 dargestellte Realisierungstechnik
Betrachtung.
Hierunter fallen gemäß Definition 1 alle sog. Internettechniken.
Dieser, in der Praxis nicht klar definiert und trennscharf gebrauchte Begriff umfaßt sowohl die Internetbasistechniken zur Datendarstellung und -übertragung als auch verschiedene Techniken zur Realisierung von Anwendungen, die über das Internet angesprochen und benutzt werden können.
Im wesentlichen zielen die eingesetzten Techniken auf die Lösung spezifischer Problemstellungen. Tabelle 1 stellt die im Rahmen der Vorlesung behandelten Techniken nebst den durch sie betrachteten Problemgebieten und einer Kurzcharakteristik zusammen.
 | Tabelle 1: Techniken: Einordnung und Kurzcharakterisierung | |||||||||||||||||||||||||||||||||||||||||||||
|
![]()
Abbildung 2 ordnet die zuvor eingeführten Techniken in ein Architekturmodell für e-Business Applikationen ein.

Das Architekturmodell zeigt die im Rahmen der Vorlesung behandelten Techniken als Bestandteil
einer hypothetischen Architektur. Sie zeigt die bevorzugten Einsatzbereiche der Einzeltechniken und gibt damit bereits einen Ausblick auf die gegenwärtig in der Praxis etablierte Pragmatik.
Besonders deutlich wird dies anhand der dargestellten Positionierung des Remote-Method-Invocation-Mechanismus. Zwar kann dieser grundsätzlich auch zur systemübergreifenden Kommunikation herangezogen werden. Jedoch wird RMI aktuell vorwiegend für die Realisierung systeminterner Kommunikationsbeziehungen, beispielsweise innerhalb J2EE-basierter Applikationsserver, herangezogen. Dies liegt in zwei Grundfaktoren begründet. Zum einen ist nur ein Teil der verfügbaren e-Business-Systeme unter Nutzung der Programmiersprache Java realisiert, worauf die RMI-Anwendbarkeit faktisch beschränkt ist. Zum anderen ist der RMI inhärent zugrundeliegende Zugriff auf binäre Applikationsschnittstellen unter Sicherheitsrestriktionen als problematisch anzusehen.
2
Datendarstellung und -zugriffIm Grunde besitzt die Geschichte der eXtensible Markup Language zwei Anfänge. Einerseits stellt XML die evolutionäre Fortentwicklung existierender generischer Auszeichungssprachen dar; andererseits sind die Hintergründe der Sprache XML so eng mit dem Aufkommen des World Wide Webs (WWW) verwoben, daß die Geschichte auch hier ihren Anfang nehmen könnte...
Der chronologischen Ordnung folgend sei zunächst die Entwicklung aus der Idee des Hypertext aufgerissen.
Die ersten Ideen zum Konzept des Hypertexts, als Plan zur Überwindung der Beschränkungen und Unzulänglichkeiten des klassischen textbasierten Publikationsmediums Papier, datieren zurück bis in die 1950er Jahre. Sie postulieren neben der nichtsequentiellen Organisation des Mediums auch zentrale Begriffe wie Knoten, Link, Anker und Netz. Ziel dieser Überlegungen war es, den auszudrückenden Inhalt von editorieller- und Präsentationsinformation wie Seitenzahlen, Fußnoten, Paginierung usw. zu trennen. Durch die nichtlineare Organisation soll es dem Leser freigestellt werden, auf welchen Pfaden er sich durch das Dokument bewegt.
Zur Realisierung dieser Bemühungen wird das Dokument mit weiteren Informationen angereichert, die jedoch für den Leser unsichtbar bleiben. Dieser Gedanke reicht zurück bis in die Anfänge des Buchdrucks. Dort sind formatierungsorientierte Auszeichnungssymbole, etwa für Fettdruck oder Unterstreichung, seit jeher bekannt. Vor dem Aufkommen der what you see is what you get Textverarbeitungssysteme waren diese bildlichen Symbole die einzige Möglichkeit zur Kommunikation präsentationsorientierter Information an den Schriftsetzer und Drucker.
Jedem Schüler ist bereits ein weiteres Beispiel einer editoriellen Auszeichnungssprache bekannt: Die graphischen Korrekturzeichen der Deutschlehrer. Auch sie liefern Informationen über den Inhalt, die nicht Bestandteil des Dokuments sind.
Voraussetzung für die angestrebte Flexibilisierung der Struktur eines Textes ist eine -- wie auch immer geartete -- technische Unterstützung. Seit den 60er Jahren wurden hierfür die aufkommenden elektronischen Rechenanlagen herangezogen. Eine der ersten Aktivitäten hierzu ist das von Ted Nelson initiierte (inzwischen legendäre) Xanadu-Projekt.
Zunächst erforderte die maschinelle Verarbeitung die Überarbeitung des Auszeichnungssymbolvorrates. Dies wurde notwendig, da eingesetzte Technik keine Unterstützung der alt-hergebrachten graphischen Auszeichungssymbole bot.
In einem ersten Entwicklungsschritt wurden daher die vormalig bildhaften Zeichen durch textuelle Pendants ersetzt und verallgemeinert. Beispielsweise: Überschrift zur inhaltlichen Kennzeichnung einer entsprechenden Textzeile.
Mit diesem Schritt erfolgte auch der Übergang zur formatierungsunabhängigen Auszeichnung, die bewußt auf die Beschreibung des späteren visuellen Aussehens der Information zugunsten einer neutralen deskriptiven Beschreibung der Semantik verzichtete.
In den 60er und 70er Jahren werden verschiedene Weiterentwicklungen der generischen Auszeichnungssprachen betrieben; u.a. bei der IBM durch das Team um Goldfarb, Mosher und Loire. Sie stellen 1969 unter dem Namen Generalized Markup Language einen Sprachvorschlag zusammen, der in der Folgezeit durch IBM kommerziell vermarktet wird.
Aus den GML-Aktivitäten bei IBM entwickelt sich die internationale Standardisierungsbewegung der Standard GML (SGML).
Durch sie wird eine Sprache festgelegt, welche die Definition eigener Sprachen erlaubt; daher auch der Begriff Metasprache. SGML bietet somit keinen feststehenden problemspezifischen Sprachumfang an, sondern eine Menge verschiedenster struktureller Konstrukte zur Formulierung von Dokumentgrammatiken.
In der Praxis wird der Einsatz einer mit Hilfe von SGML definierten Sprache oftmals plakativ zum Einsatz von SGML verkürzt, obwohl diese Begrifflichkeit lediglich den Erstellungsprozeß der Grammatik bezeichnet.
Mittels SGML definiert Tim Berners-Lee Mitte der 80er Jahre eine eigene Sprache zur vereinfachten Formulierung von Dokumenten, die er HyperText Markup Language (HTML) nennt. Hauptbeweggrund seiner Aktivitäten ist der Versuch den Dokumentenaustausch am Europäischen Kernforschungszentrum CERN rechnergestützt zu vereinfachen.
Die Eingangs erwähnten zentralen Hypertextkonzepte finden sich bereits in seinem ersten Sprachvorschlag wieder. Zur technischen Realisierung der Verknüpfung zwischen den Dokumenten mittels Ankern und Links definiert er den Uniform Resource Locator (URL), eine global eindeutige Adresse für beliebige Inhalte.
Seine Aktivitäten in Genf bilden die Keimzelle des Web.
In der Folgezeit, insbesondere im Zuge der Kommerzialisierung des Word Wide Web, entstehen verschiedene Revisionen der ursprünglichen HTML. Einige der Erweiterungen werden durch die beiden großen Web Browser Hersteller Microsoft und Netscape proprietär vorgenommen, um ihre Position am Markt zu stärken.
In der Konsequenz entstehen während des oft apostrophierten browser war teilweise inkompatible HTML-Dialekte. (Man denke nur an die Tags: marquee (nur Microsoft Internet Explorer) oder layer (nur Netscape Navigator))
Darüberhinaus entwickelt sich HTML zunehmend von einer Präsentations-orientierten Auszeichnungssprache zu einer semantischen. Dies bedeutet: während HTML in der ersten Grundform zunächst überwiegend Elemente bot, durch die die Präsentation der Inhalte am Bildschirm festgelegt wurde (Beispiele: b für Fettdruck, u für Unterstreichungen oder i für Kursivschreibung), wurden später zunehmend semantische Elemente eingeführt. Durch sie wird die Bedeutung der ausgezeichneten Information ausgedrückt (Beispiele hierfür: acronym zur Kennzeichnung von Abkürzungen, address für Adressen oder strong zur besonderen Betonung einer Textpassage).
So wünschenswert die sukzessive Umgestaltung der HTML an die veränderten Bedürfnisse war, so aussichtslos waren die Bemühungen dennoch. Während bei den Präsentations-orientierten Elementen zunehmend Vollständigkeit hinsichtlich der Anwenderwünsche erzielt werden konnte, offenbaren sich die bisher erfolgten semantischen Erweiterungen als permanent inadäquat.
Letztlich war der Versuch, durch Standardisierung, semantische Erweiterungen in HTML einzubringen in doppelter Hinsicht zum Scheitern verurteilt:
1. birgt der Ansatz die Gefahr, die Elementmenge in unbekannte Größen zu erweitern
2. muß die Semantik jedes Tags definiert, abgestimmt und verabschiedet werden.
Aus diesen Gründen wurde seitens des W3C nach einer tragfähigeren Lösung gesucht. Unter Rückgriff auf die HTML-Wurzeln (als Anwendung der Metasprache SGML) wurde das Projekt SGML for the Web initiiert.
Der letztendlich verabschiedete Vorschlag zur eXtensible Markup Language (XML) bildet konzeptionell eine Untermenge der Sprachmöglichkeiten von SGML. Konsequenterweise ist jedes XML-Dokument auch ein gültiges SGML-Dokument.
Die Abweichung zu SGML wird besonders aus den Entwicklungszielen für XML deutlich:
XML stellt jedoch keine echte semantische Auszeichnungssprache dar, da durch die Metasprache lediglich eine Möglichkeit zur Formulierung eigener Syntax gegeben ist. Die Bedeutung der Elemente bleibt jedoch unberücksichtigt, und kann mittels XML nicht ausgedrückt werden.
| Tabelle 2: Einige chronologische Eckdaten | |||||||||||||||||||||||||||||||||||||||||||||||
|
![]()
Zum Abschluß dieser Einführung seinen die zehn Punkte zusammengestellt und kommentiert, die durch das World Wide Web Consortium als plakative Kurzcharakterisierung von XML veröffentlicht wurden:
 | Web-Referenzen 1: Vertiefende Informationen |
Artikel in der Online-Ausgabe des Economist über Ted Nelson -- The Babbage of the web COT1800 Public Networks, Lecture 8, Standard Generalised Markup Language Brief History of Document Markup XML, Element Types, DTDs, and All That Clark, J.: Comparison of SGML and XML |
![]()
| Web-Referenzen 2: Weiterführende Links |
![]()
| Definition 2: XML-Sprache |
Eine Anwendung der Extensible Markup Language.
Ein Vokabular, das aus Symbolen und der ihnen zugewiesenen Bedeutung (Semantik) gebildet wird, ergänzt um Regeln
(grammatikalische Struktur und Gültigkeitsregeln für den Inhalt (z.B. Datentypen))
zur Kombination der Vokabularelemente. Anwendungen einer so neu geschaffenen XML-Sprache L werden als XML-Dokumente, auch: L-Dokumente, bezeichnet. |
![]()
Die grundlegende XML-Syntax ist in der namensgebenden W3C-Recommendation der Extensible Markup Language definiert. Die Semantik der Metasprache wird hingegen durch den W3C-Standard des XML Information Set festgelegt.
Diese Spezifikationen beinhalten die grundlegenden Definitionen hinsichtlich Terminologie und Beziehung der verschiedenen möglichen Elemente eines XML-Dokuments. Im vorliegenden Teilkapitel werden beide Sprachaspekte grundlegend eingeführt und ein erstes Verständnis der XML vermittelt. Dabei wird in Form von Ausblicken auf nachfolgende Abschnitte der Bogen zu Grammatikdefinitionssprachen und weiterführenden Konzepten wie Namensräumen gespannt.
Zum leichteren Verständnis sind die aus der offiziellen Spezifikationen entnommenen formalen
Grammatikdefinitionen der EBNF-Notation durch
vereinfachte graphische Strukturdarstellungen ergänzt.
| Definition 3: XML Dokument |
Ein XML-Dokument ist ein Datenstrom (der nicht zwingend als Datei vorliegen muß), welcher den Strukturierungsprinzipien der eXtensible Markup Language genügt. |
![]()
| Definition 4: XML Information Set |
Die Spezifikation des XML Information Sets definiert die Semantik der Metasprache XML, d.h. ihre zentralen Begriffe. Gleichzeitig setzt es diese Begriffe in Beziehung und definiert so syntaxunabhängig die Struktur eines XML-Dokumentes. |
![]()
Ausgehend von der Allgemeinheit der Aussage aus Definition 1 folgt, daß der Infoset neben seinem theoretischen Wert als Semantikdefinition zur XML auch zur Formulierung der Datenstrukturen, welche innerhalb eines XML-Prozessors vorliegen müssen, um beliebige XML-Dokumente verarbeiten zu können, herangezogen werden kann.
Daher läßt sich ein XML-Prozessor definieren als:
| Definition 5: XML-Prozessor |
Ein XML-Prozessor ist eine maschinelle Komponente (typischerweise: Software), die zum Lesen, Speichern und Verarbeiten eines XML-Dokuments eingesetzt wird. Er erlaubt Zugriff auf den Inhalt und die Struktur des XML-Dokuments. |
![]()
Die XML-Spezifikation faßt den XML-Prozessorbegriff etwas enger und beschränkt ihn lediglich auf Software-Module, die XML-Dokumente lesend verarbeiten. Konzeptionell spricht jedoch nichts gegen eine Umsetzung in Hardware, beispielsweise im Kontext eingebetter Systeme etc.
(In XML-Spezifikation nachschlagen)
Ferner nimmt die XML-Spezifikation an, ein Prozessor operiere nicht eigenständig, sondern im integrierten Zusammenspiel mit einer Applikation.
 | Beispiel 1: Ein erstes XML-Dokument |
Download des Beispiels |
![]()
Das Beispiel zeigt ein erstes einfaches XML-Dokument, welches bereits die häufigst verwendeten Sprachelemente der XML versammelt.
Jedem XML-Dokument entspricht genau ein Information Set, der alle Informationselemente des Dokuments in Form einer Baumstruktur beinhaltet. Die nachfolgende Abbildung zeigt den Information Set des Beispiels in der Notation eines UML-Klassendiagramms. Dabei sind die einzelnen Knoten des Information Sets als Objekte (Klassensymbole mit unterstrichenem Klassennamen) und die Eigenschaften der Knoten als Attributwerte dargestellt.

Jedes Information Set besteht genau aus einem Document Information Item. Dieses stellt den äußeren Rahmen des XML-Dokuments dar. Es beinhaltet dokumentbezogene Informationen, wie die verwendete XML-Version und das gewählte Codierungsschema innerhalb des Unicode-Systems.
Das Document Information Item enthält daher u.a. die Informationen des XML-Dokumentprologs in der erste Zeile jedes Dokuments. Das durch die öffnende Winkelklammer und ein Fragezeichen eingeleitete Konstrukt ist in der ersten Zeile des Beispiels 1 dargestellt. Innerhalb des Prologs findet sich die Zeichenkette xml, sowie die Bezeichner version und encoding. Beiden ist ein durch doppelte Hochkommata umschlossener Wert nachgestellt, 1.0 für version, bzw. ISO-8859-15 für encoding.
Beendet wird der Prolog wiederum durch ein Fragezeichen und die schließende Winkelklammer. Wird auf die Angabe des optionalen Prologs im Dokument verzichtet, so sind die daraus ableitbaren Angaben im Document Information Item nicht gesetzt.
Als weitere Eigenschaften verfügt jedes Document Information Item über eine geordnete Liste von Kindknoten. Darin ist genau ein Element Information Item enthalten, welches den Startknoten des XML-Dokuments verkörpert. Wegen seiner hervorgehobenen Bedeutung als Wurzel des Dokumentbaumes wird dieser Knoten auch als Document Element bezeichnet.
Zusätzlich kann die Liste Elemente vom Typ Processing Instruction Information Item enthalten. Sie dienen der Darstellung von Verarbeitungsanweisungen, die durch den XML-Prozessor interpretiert werden.
Im Kopfbereich vor Document Element plazierte XML-Kommentare werden durch Comment Information Items innerhalb der children-Liste dargestellt.
Zusammengefaßt enthält das Document Information Item folgende Informationen:
Element Information Item, welches in der Rolle des Document Items fungiert. Ferner je ein Element des Typs Processing Instruction Information Item für jede Processing Instruction die außerhalb des Wurzelements definiert ist und jeweils ein Comment Information Item zu jedem definierten Kommentar.Element Information Item, das auf den Wurzelknoten des Dokuments verweist.Wie auch im Beispieldokument, bildet die erste Zeile den sog. Prolog eines jeden XML-Dokuments
(In XML-Spezifikation nachschlagen)
. Die Angabe der Version ist zwingend und derzeit auf die Konstante 1.0 fixiert. Die aktuelle XML-Spezifikation sieht als gültige Belegung der Versionsangabe ausschließlich die Zeichenkette 1.0 vor. Zukünftigen Weiterentwicklungen ist es jedoch freigestellt auch andere Revisionskennungen zu vergeben.encoding leitet das zweite Namen-Wert-Paar ein. Die Deklaration ist innerhalb des Prologs optional, und kann daher auch unterbleiben. Die Zeichenkette der Encodingdeklaration benennt das Codierungsschema, welches für das so gekennzeichnete Dokument verwendet wurde. Es definiert den Satz der innerhalb des Dokumentes zugelassenen Zeichen fest.
Gemäß Produktion 22 der XML-Syntaxdefinition ist der gesamte Prolog optional.
Die Encoding-Deklaration hat folgendes Aussehen (In XML-Spezifikation nachschlagen) :
[80] EncodingDecl ::= S 'encoding' Eq ('"' EncName '"' | "'" EncName "'" ) [81] EncName ::= [A-Za-z] ([A-Za-z0-9._] | '-')* [3] S ::= (#x20 | #x9 | #xD | #xA)+ [25] Eq ::= S? '=' S?
Die Festlegung der Produktion 80, sowie die der Produktion 23, stellt heraus, daß sich die Encodingdeklaration nicht auf die Prologzeile selbst auswirkt. Hier sind die beiden Zeichenketten xml und encoding in der Codierung UTF-8 oder UTF-16 Vorschrift.
Als Belegungen des Encoding Namens (EncName) sind beliebige Zeichensätze zugelassen. Der XML-Standard empfiehlt jedoch lediglich auf die durch die Internet Assigned Numbers Authority verwalteten zurückzugreifen (Dokument: Official Names for Character Sets)
(In XML-Spezifikation nachschlagen)
.
Die häufigsten praktisch eingesetzten Deklarationen sind die der ISO-8859 (extended ASCII)-Familie, sowie die der Unicode- und ISO-10646-Standards.
Die verschiedenen Abschnitte der ISO-8859 Familie werden als ISO-8851-n ausgedrückt, wobei n die Nummer des Abschnittes des zugehörigen ISO-Dokuments referenziert. Ferner können die durch JIS X-0208-1997 normierten asiatischen Zeichensätze als ISO-2022-JP, Shift_JIS und EUC-JP dargestellt werden.

Unicode stellt einen Industriestandard (entwickelt u.a. durch Apple, HP, IBM, Microsoft und SUN) zur Darstellung verschiedenster Alphabete und graphischer Zeichen dar. Sein zunächst durch 16-Bit codierter Zeichenvorrat bot Raum für 65536 unterschiedliche Symbole.
Die seit 1991 laufenden Unicodebemühungen münden in die ISO-Norm zur Erweiterung des klassischen ASCII-Codes (ISO 646) als ISO-10646 Universal Multiple-Octet Coded Character Set (UCS). Seit 1996 sind beide Standards synchronisiert und werden abgestimmt vorangetrieben.
UCS definiert zwei aufeinander aufbauende Codierungen: UCS-2 (16 Bit Umfang) und UCS-4 (32 Bit). Der bisherige Unicode-Standard ist voll kompatibel zu UCS-2 und durch diesen darstellbar.
| Tabelle 3: Verschiedene Codierungen des Zeichens "A" | |||||||||||||||||||||||||||||||||||||||
|
![]()
Die Zeilenumbrüche wurden in allen Fällen durch die Kombination von Wagenrücklauf und Zeilenvorschub ausgedrückt.
Die Tabelle stellt einige Codierungen zur Darstellung des Zeichens A zusammen.
Auffallend ist der große Platzbedarf der UCS-2 und -4 Codierungen. Insbesondere bei den „klassischen“ ASCII-Symbolen werden hier (u.U. sehr viele) führende Nullbits erzeugt, die in der Konsequenz zu einer deutlichen Vergrößerung der Beispieldatei führen.
Daher wurde mit dem UCS Transformation Format (UTF) eine kompaktere Darstellung zum jeweiligen UCS-Set eingeführt. UTF-8 verwendet standardmäßig die ersten acht Bit zur Darstellung der bekannten ASCII-Zeichen
Anmerkung: Inzwischen existiert auch eine „UTF-32“ genannte 32-Bit Ausprägung, diese ist jedoch identisch zu UCS-4, mit Ausnahme daß durch UTF-32 „nur“ 221-Zeichen dargestellt werden können.
Die Dateigröße ist daher für das betrachtete Beispiel in dieser Darstellungsweise unverändert zu der des UCS-4-Encodings.
Der Größenunterschied zwischen der UTF-7 codierten Datei und der Latin-1 encodierten erklärt sich aus der Darstellung des Umlautes sowie des +-Zeichens, die beide nicht nicht im klassischen 7-Bit ASCII-Code enthalten ist. So wird Ü im Wort Übungsbetrieb des Beispieldokumentes durch die die Bytefolge 2B 41 4E 77 2D dargestellt, während alle übrigen Zeichen durch ein einzelnes Byte ausgedrückt werden können.
UTF-8 ist in der Lage sämtliche Standard-ASCII-Zeichen durch jeweils genau ein Byte auszudrücken, wiederum für den Umlaut muß auf die 16-Bit-Darstellung des UCS-2 zurückgegriffen werden. Daher erhöht sich hier die Dateigröße um ein Byte.
Erwartungsgemäß beträgt der Umfang des UCS-2 codierten Dokuments exakt das Doppelte des 8-Bit Äquivalents der Latin-1-Darstellung.
Dasselbe gilt für die UTF-16-Variante, die für das vorliegende Beispiel unterschiedslos zu UCS-4 verläuft, da keinerlei Zeichen aus UCS-4 im Dokument auftreten.
Die nachfolgende Tabelle stellt beispielhaft die Anwendung der UTF-8-Codierung zusammen:
| Tabelle 4: UTF-8 Codierung | |||||||||||||
|
![]()
Diese Mimik zeigt den Nachteil des UTF-n-Encodings deutlich: Die Darstellung nicht n-Bit darstellbarer Zeichen benötigt u.U. mehr Bitstellen als im Standard UCS-Code.
So wird beispielsweise das Zeichen mit der größtmöglichen Position (7FFFFFFF) in UTF durch sechs Byte encodiert, während UCS dieselbe Information mit den verfügbaren 32-Bit ausdrücken kann. Andererseits „verschwendet“ die UCS-Darstellung für die niederwertigen Zeichen Bitstellen durch die führenden Nullen.
In der Praxis gilt es daher für das zu wählende Encoding einen möglichst guten Kompromiß zu finden: Im allgemeinen stellt das UTF-8-Encoding einen solchen dar, soweit überwiegend ASCII-Zeichen, und nur vereinzelt Sonderzeichen (hierzu zählen auch die deutschen Umlaute) eingesetzt werden.
Bei überwiegender Verwendung nicht in acht-Bit ASCII darstellbarer Zeichen (z.B. arabischer, chinesischer, etc.) erhöht die dann aufwendigere UTF-8-Codierung die Datenmenge.
So umfaßt die UTF-16-Darstellung des unten abgebildeten Beispieldokuments, welche in diesem Anwendungsfall identisch zu UCS-2 ist, 966 Bytes, während UTF-8 1299 Byte benötigt.

Achtung: Bereits durch die Unterstützung der beiden ISO-Zeichendarstellungen UTF-8 und UTF-16 ist die Konformität zum XML-Standard erfüllt! XML-Prozessorimplementierungen wird nicht abverlangt darüberhinausgehend weitere Darstellungen umzusetzen. (In XML-Spezifikation nachschlagen)
Wie bereits eingangs angemerkt, erklärt die XML-Spezifikation die Encodingdeklaration sowie den gesamten Prolog-Ausdruck als optionales Element
(In XML-Spezifikation nachschlagen)
.
Als Konsequenz geht dabei (auch) die Angabe des gewählten Encodings verloren.
Daher fordert der Anhang F der XML-Spezifikation Autodetection of Character Encodings bei einem von UTF-8 oder -16 abweichendem Codierungsschema die zwingende Angabe der XML-Deklaration (<?xml ...)
(In XML-Spezifikation nachschlagen)
.
Hintergrund dieser Maßnahme ist der Versuch anhand der damit bekannten fünf Zeichen das zugrundeliegende Encoding zu ermitteln.
Diese fünf Zeichen können als stabil angenommen werden, da Produktion 23 und 80 diese explizit von einem von UTF-8 oder -16 abweichenden Encoding ausnehmen.
Für Dokumente im deutschen Sprachraum, d.h. XML-Ströme die häuptsächlich aus den um die deutschen Umlaute ergänzten Standard-ASCII-Zeichen bestehen, hat es sich in der Vergangenheit eingebürgert den Zeichensatz latin-1 (ISO-8859-1) zu verwenden, um die Mehrbytedarstellung der Umlaute und weiterer Sonderzeichen in der UTF-Codierung zu umgehen.
Jedoch enthält der latin-1-Zeichensatz nicht das unter Unicode-Zeichennummer 20AC abgelegte Eurosymbol (_) welches zur Abkürzung des Währungsbegriffes der europäischen Gemeinschaftswährung verwendet wird.
Dieses Symbol wurde in die unter Nummer 15 veröffentlichte aktualisierte Fassung der Zeichensatzfamilie 8859 aufgenommen. Daher sollte bei der Erstellung von XML-Dokumenten generell darauf geachtet werden entweder ISO-8859-15 als Codierung zu wählen oder auf die ohnehin ungleich flexiblere UTF-Codierung zurückzugreifen.
Die Darstellung der Abbildung 4 faßt die syntaktischen Elemente abgekürzt zusammen:

| Web-Referenzen 3: Weiterführende Links |
Payer, M.: UNICODE, ISO/IEC 10646, UCS, UTF Kuhn, M.: UTF-8 and Unicode FAQ SC Unipad ein kostenfreier Unicode Editor |
![]()
Jedes XML-Dokument enthält mindestens ein Element, das Document Element.
Seine, wie auch die Grenzen aller anderen Elemente, werden durch die Start- und Ende-Marke (engl. Tag) markiert. Für den Sonderfall eines leeren Elements bildet die Start- auch zugleich die Ende-Marke. Als eine Konsequenz können diese Elemente keine weiteren Kindknoten besitzen.
Die XML-Spezifikation legt den Aufbau des Start-Tags wie folgt fest (In XML-Spezifikation nachschlagen) :
[40] STag ::= '<' Name (S Attribute)* S? '>' [41] Attribute ::= Name Eq AttValue
Mittels der Tag-Namen werden die Typen eines Dokumentes definiert. Sie werden später, in Verbindung mit einem Grammatikmechanismus wie XML-Schema, zur Gültigkeitsprüfung herangezogen.
Der Aufbau der Elementnamen ist ähnlich zu den aus den Programmiersprachen bekannten Regeln. Am Beginn muß ein Buchstabe, ein Unterstrich oder der Doppelpunkt stehen. Darauf können nahezu beliebige Zeichen folgen, die über ihre Unicoderepräsentation genau definiert sind.
Leerzeichen und sog. white spaces (vgl. Produktion 3 der XML-Spezifikation) wie Tabulatoren und Zeilenvorschübe sind nicht zugelassen. Desweiteren darf ein Elementname weder Auszeichnungssymbole, wie die öffnenden und schließenden Winkelklammern, enthalten, noch mit der Zeichenkette XML beginnen. Die Zeichenfolge XML ist -- in allen Schreibweisen -- für die Standardisierung reserviert und wird ausschließlich in W3C-Dokumenten verwendet.
Durch den Namespace Standard (siehe Abschnitt 1.3) wird dem Doppelpunkt, als Trennsymbol zwischen Namensraumkürzel und Elementnamen, eine besondere semantische Bedeutung zugeschrieben. Daher sollte -- obwohl er spezifikationsgemäß ein erlaubtes Zeichen darstellt -- von seiner Verwendung in Elementnamen abgesehen werden.
Oftmals wird -- insbesondere in der Praxis -- die existierende und notwendige Unterscheidung zwischen Tag und Element nicht getroffen.
Die Tags oder Marken drücken beschreibende Information über ein Element aus. Der durch den Tag ausgedrückte Elementname liefert somit lediglich deskriptive Information über die Natur des Elements. Hierzu können Worte einer natürlichen Sprache verwendet werden, jedoch auch beliebige andere identifizierende Zeichenketten. Üblicherweise sind jedoch sprechende Tags anzutreffen.
Über den Tag-Namen hinaus kann ein Startelement auch noch Attribute enthalten (Vgl. Produktion 41). Diese sind jedoch nicht vom Typ Element und werden daher im Abschnitt Attribute Information Item betrachtet.
Der Aufbau eines Elementnamens wird durch die Produktionen 4ff definiert (In XML-Spezifikation nachschlagen) :
[4] NameChar ::= Letter | Digit | '.' | '-' | '_' | ':' | CombiningChar | Extender [5] Name ::= (Letter | '_' | ':') (NameChar)* [6] Names ::= Name (S Name)* [7] Nmtoken ::= (NameChar)+ [8] Nmtokens ::= Nmtoken (S Nmtoken)*
Im Beispiel sind Vorlesung, Titel und Hochschule („normale“) Elemente, während Pflichtfach ein leeres Element darstellt.
Die Abbildung zeigt, daß auf der semantischen Ebene des Information Sets die syntaktische Unterscheidung zwischen Elementknoten mit Kindelementen und leeren Elementen des XML-Dokuments keine Berücksichtigung findet.
Eine Sonderstellung unter den Elementen eines Dokuments nimmt der ausgezeichnete Wurzelknoten ein, er wird auch durch das Document Information Item referenziert. Unterhalb dieses Knotens spannt sich der Dokumentbaum auf. Hierfür enthält jedes Element Information Item eine geordnete Menge (children) weiterer Elementknoten.
Die durch den Elementnamen verwirklichte Typisierung spiegelt sich im Information Set durch das Attribut local name wieder.
Darüberhinaus enthält jedes Element Information Item durch die Eigenschaft namespace name die Identifikation des Namensraumes, in dem dieses Element plaziert ist.
Das Namensraumkürzel, welches zur Identifikation eines Elements herangezogen wird, findet sich in der Eigenschaft prefix.
Der local name entspricht dem -- um Namensraumkürzel und trennenden Doppelpunkt gekürzten -- wiedergegebenen Elementnamen des XML-Dokuments.
Zusätzlich wird jeder Namensraum, der syntaktisch an die Attributdefinition angelehnt ist, in ein Element der ungeordneten Menge namespace attributes abgebildet, welche (nochmals) die Namensräume eines Elements beinhaltet.
| Beispiel 2: Element mit deklariertem Namensraum |
|
![]()
Das Beispiel zeigt das leere Element aElement innerhalb des Elements aParent. Durch das Elternelement wird der Namensraum example.com deklariert und dem Kürzel myNS zugewiesen.
Gemäß den Prinzipien der Namensräume steht der auf dem Elternknoten deklarierte Namensraum auch in allen Kindknoten zur Verfügung. Daher enthält die Eigenschaft in-scope namespaces des Elements aElement auch die Namensräume der übergeordneten Elemente.
Das resultierende Element Information Item des Knotens aElement ergibt sich daher als (der Ausschnitt enthält nur die für das Beispiel relevanten Elemente):
local name = aElement namespace URI = example.com prefix = myNS
Nähere Ausführungen zur Bedeutung von Namensräumen und ihrer Verwendung finden sich im Abschnitt Namensräume.
Verweise auf die im Dokumentbaum nachfolgenden Knoten eines Elements werden in einer geordneten Liste children gesammelt. Ihre Inhalte sind sind vom Typ Element Information Item,
Character Information Item und Comment Information Item.
Anhand der beiden Informationstypen Element Information Item und Character Information Item zeigen sich bereits die beiden Strukturierungsformen eines XML-Dokuments. Einerseits die durch die starke Verwendung von Elementen- und Attributen gekennzeichnete strukturierte Darstellung, andererseits die durch „eingestreuten“ Freitext entstehende charakteristische semistrukturierte Variante.
In beiden Fällen werden die textartigen Inhalte durch Character Information Items repräsentiert.
Das Beispiel zeigt die verschiedenen Auftretensformen exemplarisch. Der Inhalt der Elemente title und organization ist rein Zeichenketten-artig; jedoch mischt vorlesung strukturierten Inhalt (in Form der genannten Elemente) und unstrukturierte Information -- repräsentiert durch den Text 2002/03.
Die XML-Spezifikation prägt für Zeichenketten-artige Inhalte, die optional durch eingestreute Elemente angereichert werden, den Begriff mixed Content.
children enthält jedoch keine Verweise auf die Attribute eines Elements. Diese sind durch die separate ungeordnete Menge attributes repräsentiert. Die Diskussion der als Attribute Information Item bezeichneten Mengenelemente findet sich im folgenden.
Die in der Abbildung dargestellte Beziehung parent verbindet jedes Element mit seinem übergeordneten. Als Ziele dieser Referenz sind ausschließlich Ausprägungen von Document Information Item oder Element Information Item zugelassen.
Diese Festlegung untermauert nochmals die strikte Baumstruktur eines XML-Dokuments. Andernfalls müßte parent als Menge definiert werden.
Das betrachtete Beispiel enthält, neben den Elementen, auch ein XML-Attribut.
Syntaktisch werden Attribute innerhalb eines Start-Tags plaziert und durch Namen-Wert-Paare ausgedrückt
(In XML-Spezifikation nachschlagen)
.
Der Information Set enthält folgende Eigenschaften zu jedem Attribut:
ID, IDREF, IDREFS, ENTITY, ENTITIES, NMTOKEN, NMTOKENS, NOTATION, CDATA, und ENUMERATION.IDREF(S), ENTITY, ENTITIES oder NOTATION typisiert), so enthält diese Eigenschaft eine Verweisliste auf alle Auftreten des Attributwertes.Im Vergleich zum Element Information Item erlaubt das Attribut keine weitere Unterstrukturierung (im XML-Sinne); insbesondere fehlen mengenwertige Eigenschaften zur Aufnahme der dann notwendigen Verweise. Stattdessen wird der gesamte Inhalt durch die Eigenschaft normalized value dargestellt.
Daher dürfen innerhalb von Attributen keine (Meta-)Symbole wie die öffnende Winkelklammer auftreten, die als Starttags (miß-)interpretiert werden könnten
(In XML-Spezifikation nachschlagen)
.
Auch die Form des Auftretens von Attributen innerhalb des definierenden Elements unterscheidet sich von der der Subelemente innerhalb eines Elements. Während Kindelemente durch die geordnete Liste children dargestellt werden, können Attribute (formalisiert in der ungeordneten Menge attributes) in beliebiger Reihenfolge angegeben werden, ohne die Dokumentsemantik zu verändern. Mehr noch, die Listenkonstruktion erlaubt das unterscheidbare mehrfache Auftreten desselben Elements. Diese Mimik ist für allgemeine Mengen, und damit für Attribute, nicht möglich.
Element vs. Attribut
Der Vergleich der Eigenschaften von Element und Attribut zeigt bereits, daß sich nicht weiter strukturierte Elemente auch durch Attribute darstellen ließen. Dies wirft innerhalb der Betrachtung der Syntax eines XML-Dokuments bereits die Frage nach der Organisation, und damit dem Entwurf, eines solchen auf.
Die bestehende XML-Spezifikation bleibt jedoch eine Anwendungs- oder Einsatzempfehlung zu dieser Fragestellung schuldig.
Aufgrund der inhärenten Einschränkungen der Attributprimitive bietet sich ihr Einsatz nur in einigen Sonderfällen an. Beispielsweise zur Darstellung deskriptiver Information über das enthaltende Element, die nicht Bestandteil der im XML-Dokument dargestellten Information ist. Hierbei kann es sich um Informationen höherer Ordnung, sog. Metainformation handeln.
Generell bieten sich Elemente immer dann an, wenn eine weitere Unterstrukturierung des Inhaltes gewünscht oder vielleicht zukünftig notwendig ist. Die Darstellungsform als Attribut würde in diesem Fall eine strukturelle Umorganisation des XML-Vokabulars erfordern, da die Spezifikation keine Unterstrukturierungsmöglichkeit für Attribute vorsieht.
Darüberhinaus gestatten Attribute keine Wiederverwendung in verschiedenen Bedeutungskontexten, da sie syntaktisch an das umgebende Element gebunden sind. Diese Einschränkung wird zwar durch die Einführung des Standards XML Schema weitgehend gemildert, jedoch nicht die zuvor genannte Mächtigkeitseinschränkung. Zusätzlich stellen Attribute die einzige Möglichkeit zur Typisierung des Inhaltes dar solange DTDs verwendet werden. Dieser Punkt
dürfte jedoch durch den wachsenden Praxiseinsatz der XML Schemata immer mehr an Bedeutung verlieren.
Die Darstellung der Abbildung 5 faßt die syntaktischen Elemente abgekürzt zusammen:

Die Betrachtung der Attribut- und Elementknotentypen im Information Set zeigt bereits die zwei grundlegenden Arten der Informationsdarstellung eines XML-Dokumentbaumes.
Die Eigenschaft normalized value des Attribute Information Items kapselt den im XML-Dokument angegebenen Inhalt direkt im Informationsknoten. Der Datentyp der Eigenschaft ist für alle Dokumenttypen fixiert angebbar, da keine weitere Unterstukturierung von Attributen erfolgen kann.
Entgegensetzt hierzu verläuft die Argumentationslinie für Elemente. Ihr Inhaltsmodell kann eine freie Mischung aus Zeichenketten-Daten und weiteren Elementen aufweisen. Die Länge der Zeichenketten ist hierbei nicht näher festgelegt. Daher können diese im minimalen Falle nur aus einem einzelnen Zeichen bestehen.
(In XML-Spezifikation nachschlagen)
.
Innerhalb des Information Sets eines Dokuments werden alle Zeichen im Rumpf eines Elements als Ausprägungen des Character Information Items dargestellt.
Jedes Character Information Item stellt das im Dokument gegebene Zeichen gemäß ISO 10646-Codierung in der Eigenschaft character code dar. Die Werte können hierbei jedoch nur in den durch die Spezifikation vorgegebenen Grenzen variieren
(In XML-Spezifikation nachschlagen)
. Darüberhinaus genügt bereits die Unterstützung der UTF-8 und -16-Darstellung zur Erfüllung der Spezifikationsanforderungen an konforme Prozessoren.
Häufig werden white-spaces (Leerzeichen, Tabulator, Zeilenvorschub, Wagenrücklauf) zur besseren visuellen Strukturierung des XML-Dokumentes eingesetzt. So enthält das Beispieldokument jeweils nach der schließenden Marke einen Zeilenvorschub. Unter Datengesichtspunkten handelt es sich hierbei jedoch um keine verwertbare Information. Die Angabe der Berücksichtigung bzw. Vernachlässigung im XML-Dokument existierender white-spaces kann in der DTD gesetzt werden. Ist keine solche Deklaration gesetzt oder existiert keine explizite Grammatik, so hat die Eigenschaft element content whitespace keinen Inhaltswert.
Der als parent-Eigenschaft realisierte Verweis auf das beherbergende Elternelement bildet den Abschluß der Eigenschaften des Character Information Items.
Im betrachteten Beispiel sind unterhalb der Elemente organization und title Character Information Element-Ausprägungen plaziert. Die Darstellung zeigt diese als Objekte (Unterhalb des organization-Knotens wurde aus Übersichtlichkeitsgründen auf die Darstellung verzichtet).
Eine Sonderrolle kommt den Zeichen zu, die auch als Metasymbole der Auszeichnungssprache dienen. Sie dürfen daher nicht in XML-Dokumenten auftreten.
Bei diesen Zeichen handelt es sich um die beiden Winkelklammern, die einfachen und doppelten Anführungszeichen sowie das Kaufmanns-Und. Um eine Fehlinterpretation zu vermeiden existieren hierfür vordefinierte Textersetzungsmuster.
Jeder spezifikationskonforme XML-Prozessor berücksichtigt diese Symbole und gibt sie in der korrekten Darstellung an die Applikation weiter; damit sind diese Fluchtsymbole (engl. escape characters) aus Applikationssicht vollkommen transparent.
| Tabelle 5: Vordefinierte Textersetzungsmuster | |||||||||||
|
![]()
| Web-Referenzen 4: Weiterführendes ... Die in XHTML v1.0 vordefinierten Entitäten |
![]()
Zur Dokumentation steht innerhalb jedes XML-Dokuments die von SGML ererbte Kommentierungssyntax zur Verfügung.
Die Spezifikation erlaubt die Anbringung von Kommentaren an zwei Stellen im XML-Dokument:
Nicht erlaubt sind demnach Kommentare in Tags, d.h. innerhalb geöffneter Winkelklammern.
Dergleichen gilt für Kommentare selbst, was geschachtelte Kommentare verbietet.
Produktion 15 der XML-Spezifikation legt die Struktur wie folgt fest:
[15] Comment ::= '<!--' ((Char - '-') | ('-' (Char - '-')))* '-->'
Als Konsequenz sind innerhalb von Kommentaren alle Zeichen, auch Metasprachensymbole, zugelassen. Somit ist das beliebige „auskommentieren“ von Dokumentteilen möglich.
Als zentrale Einschränkung dürfen (aus SGML-Kompatibilitätsgründen) keine zwei aufeinanderfolgenden Trennstriche (hyphen-minus, ISO 10646 #x2D) innerhalb eines Kommentars auftreten, da diese fehlerhafterweise als Beginn des Kommentarendes interpretiert würden.
Der gesamte Inhalt eines Kommentars wird als uninterpretierte Zeichenkette in der Eigenschaft content des Comment Information Items abgelegt.
Zusätzlich verweist jeder Kommentar über die bekannte parent-Eigenschaft auf seinen Elternknoten. Wie bereits durch die beiden Einsatzformen angedeutet, kann es sich hierbei ausschließlich um ein Document Information Item oder ein Element Information Item handeln.
| Beispiel 3: Verschiedene Kommentarstrukturen |
|
![]()
Das Beispiel zeigt verschiedene Einsätze von Kommentaren. Zunächst eine einzeilige Anmerkung, die nur verschiedene Zeichen versammelt. Im Anschluß einen mehrzeiligen Kommentar, der auch XML-Strukturen beinhaltet. Ein prozessierender Zugriff auf den Kommentarinhalt ist jedoch nicht vorgesehen, und wird durch gängige Parser und APIs zumeist nicht unterstützt.
Im Gegensatz zu den prinzipiell in beliebigem Freitext formulierbaren Kommentaren, die üblicherweise zur Kommunikation mit einem menschlichen Leser des XML-Dokuments dienen, zielt die Processing Instruction und das zugehörige Element des Information Sets auf Kommentare, welche einen maschinellen Verarbeiter des XML-Dokuments, den XML-Prozessor, betreffen.
Im Grunde genommen läuft die Anreicherung eines XML-Dokuments mit Verarbeitungsinformation der Idee einer deskriptiven Auszeichnungssprache entgegen ...
Jedoch wurde für die XML beschlossen, nicht zuletzt aus Kompatibilitätsgründen zu SGML, dieses Sprachmerkmal beizubehalten. Eine mögliche weitere Erklärung könnte das syntaktische Aussehen der XML-Deklaration innerhalb des des Dokumentprologs sein. Ihre in Produktion 23ff festgelegte Struktur stellt eine Anwendung der Processing Instruction dar, auch wenn dies innerhalb der Spezifikation nicht explizit formuliert wird.
Die Syntax einer Processing Instruction lautet:
[16] PI ::= '<?' PITarget (S (Char* - (Char* '?>' Char*)))? '?>' [17] PITarget ::= Name - (('X' | 'x') ('M' | 'm') ('L' | 'l'))
Eine Processing Instruction wird demnach immer durch eine öffnende Winkelklammer und ein folgendes Fragezeichen eingeleitet. Daran schließt sich die Benennung der Applikation an, für die diese Instruktion eingefügt wurde. Optional können weitere Zeichen -- ausgenommen der Kombination aus Fragezeichen und schließender Winkelklammer -- folgen.
Das adressierte System kann beliebig identifiziert werden, jedoch ist die Zeichenkette XML in allen Variationen ausgeschlossen.
Unbedachterweise verbietet die Spezifikation jedoch nicht die Bildung von Namen, die XML als Präfix nutzen ... Jedoch sollte von der Nutzung solcher Konstruktionen abgesehen werden, da sie zur Verwirrung der (menschlichen) Leser beitragen.
Wie Kommentare auch können Processing Instructions an beliebiger Stelle innerhalb des XML-Dokuments auftreten: Vor Beginn des Wurzelelements sowie im Rumpf jedes Elements. Nicht gestattet ist ihre Angabe in Elementnamen und Attributen.
Ergänzend sei angemerkt, daß die Angabe von Processing Instructions auch innerhalb der Document Type Definition erfolgen kann. (siehe Document Type Definition Information Item).
| Beispiel 4: Verschiedene Processing Instructions |
Download des Beispiels |
![]()
 | Übung 1: Processing Instructions |
Begründen Sie mit Hilfe der XML-Spezifikation warum Processing Instructions nicht innerhalb von Elementen und Attributen zugelassen sind. Hinweis: Es gibt mehr als eine Begründung! |
![]()
Das Processing Instruction Information Item enthält die angesprochene Zielapplikation als Namen innerhalb der Eigenschaft target.
Der weitere Inhalt der Deklaration wird uninterpretiert als Zeichenkette in die Eigenschaft content übernommen.
Neben einem Verweis auf die Basis-URI der Processing Instruction wird durch parent das Elternelement -- entweder ein Knoten des Typs Document Information Item oder Element Information Item -- referenziert.
Zur Formalisierung der Identifikation der Zielapplikation empfiehlt die XML-Spezifikation die Verwendung des Sprachmittels Notation.
Die Darstellung der Abbildung 6 faßt die syntaktischen Elemente abgekürzt zusammen:

Jedem im XML-Dokument definierten Namensraum ist ein Namespace Deklaration Information Item zugeordnet. Es enthält die notwendigen syntaktischen Details zur Identifikation des Namensraumes:
| Beispiel 5: Beispiel eines Dokuments mit Namensräumen |
|
![]()
Für das Beispiel lauten die Namensräume wie folgt:
 |
| ||||||||||||||
Eine ausführliche Betrachtung zur Verwendung von Namensräumen findet sich im entsprechenden Abschnitt.

Die Graphik der Abbildung 7 stellt alle diskutierten Elemente des Information Sets in der Übersicht mit ihren Beziehungen dar. Zur Veranschaulichung wurde eine einfache Graphenstruktur gewählt, die alle Informationseinheiten als Knoten (darstellt als Ellipsen) und alle zugelassenen Beziehungen als gerichtete Kanten zwischen diesen enthält. Zusätzlich ist an die Kanten die Art der Beziehung angetragen.
Den Ausgangspunkt der baumartigen Struktur eines XML-Dokuments bildet die im Zentrum abgebildete Primitive Document Information Item, die alle weiteren Inhalte eines Dokuments über die children-Kante als Kindknoten enthält. Ferner fällt in dieser Darstellung besonders auf, daß lediglich Element Information Items über weitere Kindknoten verfügen und so die charakteristische XML-Struktur herausbilden. Alle übrigen Primitive dienen überwiegend als Blattknoten des Baumes.

Die Graphik der Abbildung 8 setzt die durch den Infoset-Standard definierte Semantik und die darauf aufsetzenden Syntaxen in Beziehung. Der XML-Basisstandard definiert hierbei nur eine von mehreren möglichen Syntaxen zur Darstellung von Infoset-Ausprägungen. Ebenso denkbar wäre der Einsatz anderer Darstellungen gleicher Mächtigkeit wie beispielsweise der S-Expression aus LISP oder objektorientierte Umsetzungen.
![]()
Auf Basis der Definitionen des Information Sets läßt sich ein beliebiges XML-Dokument, welches den Strukturierungsprinzipien des Infosets folgt, als wohlgeformt (well-formed) charakterisieren.
| Definition 6: Wohlgeformtes XML-Dokument |
Ein textartiges Objekt, dessen Inhalt folgenden Anforderungen genügt:
siehe XML-Spezifikation |
![]()
Der Textstrom des Beispiels 6 zeigt ein nicht-wohlgeformtes XML-Dokument, welches gegen eine Reihe der in Definition 6 verstößt:
| Beispiel 6: Ein nicht wohl-geformtes XML-Dokument |
Download des Beispiels |
![]()
So findet sich in Zeile 3 ein nicht in die erforderlichen Anführungszeichen eingeschlossener Attributwert.
Der textuelle Elementinhalte des in Zeile 4 geöffneten Elements elementB enthält ein öffnendes Winkelklammersybol, welches um Fehler während des Einlesevorganges zu vermeiden durch die alternative Zeichensequenz < hätte ersetzt werden müssen. Darüberhinaus fehlt das korrekte schließende Tag zum Öffnenden.
Innerhalb des Elements elementC der Zeile 6 wird zweifach ein identisch benanntes Attribut definiert.
Im öffnenden Tag des in Zeile 7 definierten Elements elementD findet sich eine -- dort nicht zugelassene -- Processing Instruction.
Überdies überlappen sich die Elementgrenzen der Elemente elementC und elementD und zusätzlich wird der in Zeile 10 plazierte Kommentar nicht durch die erforderlichen genau zwei Bindestriche eingegrenzt.
Die XML-Namensräume wurden schon verschiedentlich erwähnt. Sie
bilden die wichtigste, und offensichtlichste Weiterentwicklung der
XML-Urspezifikation seit ihrer Veröffentlichung.
Trotz ihrer engen Beziehung zum XML-Kernstandard bildet die Recommendation
Namespaces in XML eine eigenständige Spezifikation. Aufgrund der engen syntaktischen Beziehung zum XML-Standard und der großen praktischen Bedeutung, sowie des Einflusses auf die weitere Entwicklung verschiedenster Sekundärstandards und XML-Sprachen, werden die Namensräume explizit in der Neuauflage des XML-Standards berücksichtigt. Einen Beleg hierfür bildet die Anmerkung zu Abschnitt 2.3 Common Syntactic Constructs. Dort wird von der -- laut Syntaxproduktion 5 erlaubten -- Verwendung des Doppelpunktes in Elementnamen abgeraten. Dies geschieht, um Mehrdeutigkeiten, oder schlichtweg der Verwirrung des Anwenders, vorzubeugen, da es sich beim Doppelpunkt um ein Symbol besonderer Bedeutung innerhalb der Namensraumdeklarationen handelt.
Warum Namensräume?
Die breite Entwicklung immer neuer XML-Sprachen führt zwangsläufig zu Mehrfachentwicklungen für ähnliche oder identische Problemstellungen. Technisch betrachtet äußerst sich dies -- bei natürlichsprachlicher Benennung der Elemente -- durch die Verwendung identischer Bezeichner in verschiedenen XML-Sprachen. Hierbei bilden die verschiedenen Sprachen Anwendungskontexte, innerhalb derer die Bezeichner, durch Einbezug der Anwendungssemantik, eindeutig sind; andernfalls kann unterstellt werden, daß bereits durch die Sprachentwicklung andere Benennungskonventionen gewählt worden wären.
In der Konsequenz der Verfügbarkeit verschiedenster XML-Sprachen für beliebige Anwendungsbereiche entsteht der (berechtigte) Wunsch existierende Sprachfragmente in eigene Sprachen zu integrieren, um so zeitraubenden und vielfach fehleranfälligen Mehrfachentwicklungen vorzubeugen. Jedoch tritt bei diesem Integrationsszenario die u. U. kontextabhängige Elementeindeutigkeit zu Tage.
Das Beispiel zeigt zwei Dokumente identischen Informationsumfanges, die lediglich strukturell differieren.
| Beispiel 7: Ein Rechnungsdokument |
|
![]()
| Beispiel 8: Eine alternative Rechnungsstruktur |
|
![]()

Die beiden Bäume mit Information Set-Ausprägungen zeigen die Struktur der Beispieldokumente. Dabei sind Knoten die den selben Inhalt repräsentieren mit identischen Farben unterlegt, unabhängig davon um welchen Knotentyp es sich handelt. Die Character Information Item Knoten wurden aus Übersichtlichkeitsgründen weggelassen und durch Punkte angedeutet, sie sind jedoch für die vorliegende Betrachtung nicht von Interesse.
Einige der Elemente und Attribute werden in beiden Dokumenten mit gleichen Inhalten verwendet; z.B. Name, Ort oder PLZ. Dies äußert sich in identischen Teilbäumen unterhalb der Information Set-Knoten welche diese XML-Elemente repräsentieren. Hieraus läßt sich ableiten, daß die beiden vorgestellten Sprachen an den genannten Stellen keine strukturelle Differenz aufweisen.
Dagegen unterscheiden sich die Kindknoten der Elemente Rechnung und Kunde hinsichtlich ihrer Struktureigenschaften. So folgt im ersten Beispieldokument auf das Rechnung-Element direkt der Kunde, während im zweiten XML-Dokument zunächst ein Element mit dem Namen Rechnungsanschrift erwartet wird.
Dergleichen gilt für die Kindelemente des Kunden. Im zweiten Beispieldokument wird die diesem Element untergeordnete Kundennummer durch ein Attribut (kundenNr) dargestellt. Dagegen codiert das erste Beispiel diese Information direkt in den Elementinhalt.
Solange die beiden Dokumente in unterschiedlichen Anwendungswelten (Unternehmen o. ä.) verwendet werden, ist der gewählte Ansatz nicht problematisch. Bedenklich wird er jedoch in mindestens zweierlei Hinsicht:
Zunächst bei der „Mischung“ der beiden Dokumente. Dieser Wunsch tritt bei praktischen Problemstellungen häufig auf, wenn es um die Übernahme von XML-codierten Daten in ein anderes XML-Dokument geht. In der Konsequenz folgt das entstehende Zieldokument nicht mehr den Strukturierungsregeln eines der Ausgangsdokumente; mithin entsteht eine neue Dokumentstruktur, deren Regeln nicht explizit dokumentiert sind.
Eine weitaus größere Herausforderung stellt die Zusammenfassung und Veröffentlichung von XML-Strukturen in sog. Schemabibliotheken oder Datenbanken dar. Hier werden zwar die Dokumente nicht vereinigt, jedoch offenbart sich die gleiche Anwendungsdomäne (z.B. Rechnungsverwaltung, Stücklisten, Produktstrukturen) als problematisch, da sie die XML-Strukturen in direkte Konkurrenz treten läßt. In Zeiten immer stärker werdenden ökonomischen Flexibilisierungsdruckes erweist sich dies als äußerst kontraproduktiv, im Hinblick auf eine angestrebte Standardisierung. Die offene Konkurrenz verschiedener Dialekte innerhalb einer Domäne verzögert damit oft die Entscheidung zum Einsatz eines Sprachformates.
Einen anderen interessanten Anwendungsfall stellt der ausdrückliche Wunsch nach der Einbettung fremder Sprachelemente dar. Diese Form der Wiederverwendung knüpft an das durch öffentlich verfügbare XML-Formate eröffnete Anwendungsfeld an. Da nicht in jedem Fall ein alle Anforderungen erfüllendes existierendes XML-Format ermittelt werden kann, jedoch verschiedene vorhandene Formatteile des gewünschten Umfanges abdecken, entsteht der Wunsch nach einer selektiven Weiterverwendung. Ein bekanntes Beispiel bilden Freitexte in beliebigen XML-Sprachen, welche auf Teile des (X)HTML-Sprachumfanges zurückgreifen. Gleichzeitig ist damit die Semantik der Elemente durch den zugehörigen W3C-Standard festgelegt. XHTML selbst stellt ein interessantes Anwendungsbeispiel für die gemeinsame Verwendung verschiedener XML-Sprachen in einem Dokument dar. So können Web-Seiten neben den bekannten Textstrukturen (XHTML) auch mathematische Symbole und Formeln (in der XML-Sprache MathML) und Vektorgraphiken (in der XML-Sprache SVG) enthalten.
Als Nebeneffekt der Wiederverwendung existierender XML-Sprachen verringern sich mögliche Fehlerquellen, was in der Konsequenz zur Erhöhung der Qualität der entstehenden Sprachen führt.
Zusammenfassend lassen sich die (Hinter-)Gründe der Namensraumeinführung wie folgt darstellen:
| Definition 7: Namensräume |
XML-Namensräume stellen eine XML-basierte Syntax zur Verfügung um Element- und Attributnamen eines
Vokabulars eindeutig zu identifizieren und so Bedeutungsüberschneidungen durch gleichbenannte Elemente- oder
Attribute in zu unterscheidenden Vokabularen auszuschließen.
XML-Namensräume bilden damit die notwendige Voraussetzung zur freien dezentralen Entwicklung eigener Vokabulare
ohne die Möglichkeit einer späteren Syndikatisierung zu verlieren.
|
![]()
Konzept der Namensräume:
Die Recommendation Namespaces in XML definiert die Syntax und Semantik der Namensräume. Ihr Konzept wurde rund ein Jahr nach Verabschiedung der ersten XML-Version eingeführt. Daher wurde der Kompatibilität mit bereits existierenden XML-Dokumenten große Priorität eingeräumt.
Grundidee der Namensräume ist es, die Element- und Attributnamen dergestalt zu erweitern, daß (auch nach Vereinigung beliebiger Dokumente wieder) eineindeutige Bezeichner entstehen. Dies könnte durch anwenderdefinierte Erweiterungen geschehen, sie trügen jedoch wiederum die Gefahr in sich, daß sie unbeabsichtigt mehrfach benutzt würden.
Daher scheidet der unkoordinierte Einsatz solcher Namenserweiterungen aus. Jegliche Koordination bedingt jedoch inhärent eine zentrale Vergabestelle zur Registrierung der vergebenen Namen, die über die Eindeutigkeit wacht und Mehrfachnutzungen unterbindet.
Die Einführung einer solchen Stelle hätte jedoch einen unüberschaubaren Verwaltungsaufwand bedeutet, den das W3C nicht zu leisten im Stande wäre. Man nehme nur als Vergleich das Vergabeverfahren von Einträgen des Internet Domain Name Systems (DNS), welches bereits dezentral durch die einzelnen nationalen Domain-Registrars gehandhabt wird. Der dort anzutreffende Aufwand hätte sich für XML-Namensräume potenziert, legt man pro Domainadresse mehrere Namensräume zugrunde.
Ziel des W3C war es, durch die Namensräume einen gleichermaßen mächtigen als auch leicht zu handhabenden und zu administrierenden Identifikationsmechanismus zu etablieren. Offenkundig wird diesem Anspruch nur ein (überwiegend) dezentraler, aber dennoch die Eineindeutigkeit garantierender, Ansatz gerecht.
Diesen Anforderungen genügt das aus IETF RFC 2396 bekannte Namensschema der Uniform Resource Identification (URI) (später aktualisiert in IETF RFC 2732). Es kombiniert zentrale und dezentrale Elemente in der Handhabung, und ermöglicht so -- trotz Existenz und Pflege einer zentralen Registratur -- größtmögliche Flexibilität in der Anwendung. Der bekannteste Einsatz von URI-Namen ist der im World-Wide-Web allgegenwärtige Uniform Ressource Locator (URL) (IETF RFC 1738); einer Untermenge der URI.
Die zentrale Komponente findet sich im Domainnamen verwirklicht. Er ist entweder durch die IP-Adresse (konkret: IPv4-Adresse; im Falle des RFC 2732: der IPv6-Adresse) oder deren literaler Repräsentation gegeben. Unterhalb der Domainebene kann durch deren Verwalter eine beliebige Strukturierung vorgenommen werden. Die verschiedenen Ebenen werden dabei durch ISO-10646/ASCII #x2F „/“ voneinander abgetrennt.
Wie auch bereits bei URLs notwendig, ist das Schema (URI scheme) (z.B. http) zwingend mitanzugeben.
Trotz der Möglichkeit XML-Namensräume durch URLs zu identifizieren handelt es sich dabei nicht die Bezeichnung einer Internetquelle. Die verwendete Zeichenkette dient ausschließlich Benennung der im Namensraum versammelten XML Element Information Items und Attribute Information Items.
Die Auflösung des Namensraumbezeichners durch einen XML-Prozessor ist nicht vorgesehen.
Nachfolgend ist die in definierte Syntax einer URI wiedergegeben. Sie wurde behutsam an die in der XML-Spezifikation verwendete BNF-Notation (In XML-Spezifikation nachschlagen) angepaßt, ohne jedoch die Produktionen in ihrer Struktur zu verändern.
[URI1] URI-reference ::= (absoluteURI | relativeURI)? ("#" fragment)? [URI2] absoluteURI ::= scheme ":" ( hier_part | opaque_part ) [URI3] relativeURI ::= ( net_path | abs_path | rel_path ) [ "?" query ] [URI4] hier_part ::= ( net_path | abs_path ) ("?" query)? [URI5] opaque_part ::= uric_no_slash uric? [URI6] uric_no_slash ::= unreserved | escaped | ";" | "?" | ":" | "@" | "&" | "=" | "+" | "$" | "," [URI7] net_path ::= "//" authority abs_path? [URI8] abs_path ::= "/" path_segments [URI9] rel_path ::= rel_segment abs_path? [URI10] rel_segment ::= (unreserved | escaped | ";" | "@" | "&" | "=" | "+" | "$" | "," )+ [URI11] scheme ::= alpha (alpha | digit | "+" | "-" | "." )* [URI12] authority ::= server | reg_name [URI13] reg_name ::= ( unreserved | escaped | "$" | "," | ";" | ":" | "@" | "&" | "=" | "+" )+ [URI14] server ::= ((userinfo "@")? hostport)? [URI15] userinfo ::= ( unreserved | escaped | ";" | ":" | "&" | "=" | "+" | "$" | "," )* [URI16] hostport ::= host (":" port)? [URI17] host ::= hostname | IPv4address [URI18] hostname ::= ( domainlabel "." )* toplabel (".")? [URI19] domainlabel ::= alphanum | alphanum *( alphanum | "-" ) alphanum [URI20] toplabel ::= alpha | alpha (alphanum | "-" )* alphanum [URI21] IPv4address ::= digit+ "." digit+ "." digit+ "." digit+ [URI22] port ::= digit* [URI23] path ::= (abs_path | opaque_part)? [URI24] path_segments ::= segment ("/" segment)* [URI25] segment ::= pchar* (";" param)* [URI26] param ::= pchar* [URI27] pchar ::= unreserved | escaped | ":" | "@" | "&" | "=" | "+" | "$" | "," [URI28] query ::= uric* [URI29] fragment ::= uric* [URI30] uric ::= reserved | unreserved | escaped [URI31] reserved ::= ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" | "$" | "," [URI32] unreserved ::= alphanum | mark [URI33] escaped ::= "%" hex hex [URI34] hex ::= digit | "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "d" | "e" | "f" [URI35] digit ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" [URI36] uric_no_slash ::= unreserved | escaped | ";" | "?" | ":" | "@" | "&" | "=" | "+" | "$" | ","
Die Produktionen alphanum, lowalpha sowie upalpha zur Konstruktion der alphanumerischen Namen
wurden aus Übersichtlichkeitsgründen weggelassen.
Neben einigen anderen gängigen URI-Varianten stellt das nachfolgende Beispiel einige der möglichen syntaktisch korrekten URIs zusammen, die für die späteren Betrachtungen von Interesse sind.
| Beispiel 9: Gültige URIs |
|
![]()
Vielfach wird in der Praxis die Abgrenzung der im Internet gebräuchlichen Adressierungs- und Identifikationsmechanismen nicht trennscharf vollzogen.
Darüberhinaus trat im Laufe der Entwicklung eine merkliche Bedeutungsverschiebung insbesondere zwischen der Uniform Resource Identifikation und den als WWW-Adressen genutzten Uniform Resource Locators ein.
Gegenwärtig wird die Begriffsabgrenzung wie in Abbildung 10 schematisch dargestellt vollzogen:
http://www.jeckle.de/vorlesung/xml/script.htmlhttp://www.wi.fh-furtwangen.de/mailto:mario@jeckle.deftp://example.org/aDirectory/aFilenews:comp.infosystems.wwwtel:+1-816-555-1212ldap://ldap.example.org/c=GB?objectClass?oneurn:oasis:SAML:1.0urn eine Zeichenkette welche eine Weiterklassifikation der Ressource gestattet. Hierdurch wird eine weitere Partitionierung des URN-Raumes erzielt. Diese namespace ID genannten Zeichenketten unterliegen einem globalen Registrierungszwang um ihre Eindeutigkeit zu gewährleisten. Diese Unterstrukturierungen sind in der Abbildung als ns1 bis ns3 benannt.urn:oasis:names:specification:docbook:dtd:xml:4.1.2urn:oid:1.3.6.1.2.1.27
| Web-Referenzen 5: Weiterführende Links |
![]()
![]()
Verwendung von Namensräumen:
Am naheliegendsten wäre nach der Zielsetzung der Verwendung von URIs zur eindeutigen Benennung von XML-Element- und Attributnamen, die URI direkt vor dem XML-Bezeichner zu plazieren, evtl. separiert durch ein Trennsymbol wie den Doppelpunkt „:“.
Hieraus entstünden dann, auf jeden Fall eindeutige, Element- und Attributnamen wie beispielsweise für das erste Beispieldokument dieses Kapitels (die URI http://www.example.com/sales werde zur Identifizierung verwendet):
(1)<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
(2) <http://www.example.com/sales:Rechnung>
(3) <http://www.example.com/sales:Kunde>
(4) <http://www.example.com/sales:KundenNr>4711</http://www.example.com/sales:KundenNr>
(5) <http://www.example.com/sales:Name>Max Mustermann</http://www.example.com/sales:Name>
(6) <http://www.example.com/sales:Anschrift>
(7) <http://www.example.com/sales:Straße>Musterplatz 1</http://www.example.com/sales:Straße>
(8) <http://www.example.com/sales:PLZ>12345</http://www.example.com/sales:PLZ>
(9) <http://www.example.com/sales:Ort>Musterstadt</http://www.example.com/sales:Ort>
(10) </http://www.example.com/sales:Anschrift>
(11) </http://www.example.com/sales:Kunde>
(12) <http://www.example.com/sales:Rechnungsposten>
(13) ...
(14) </http://www.example.com/sales:Rechnungsposten>
(15)</http://www.example.com/sales:Rechnung>
Bei entsprechender Nachbearbeitung des zweiten Beispieldokumentes mit einem anderen URI-identifizierten Namensraum, entstehen eindeutige Element- und Attributnamen, die nicht mehr kollidieren.
Jedoch verstößt diese Lösung gegen die in Produktion 5 der XML-Spezifikation formulierte syntaktische Einschränkung. Sie erlaubt das in URIs elementare Pfadtrennersymbol („/“) (aus den URI-Produktionen 8, 24 und 31) nicht in XML-Namen (#x2F findet sich nicht in den in Produktion 85 aufgeführten Unicode-Blöcken).
Die Integration der Namensräume auf diesem Weg hätte daher eine Modifikation der XML-Spezifikation nach sich gezogen. Diese erweiternde Aufweichung der zugelassenen Namen für Elemente und Attribute hätte jedoch mit der Kompatibilität zu SGML gebrochen, und somit eine der Grundforderungen der XML-Entwicklung verletzt.
Darüberhinaus ist die Spezifikation vollständiger URIs für Menschen „unhandlich“ und reduziert die Lesbarkeit der entstehenden XML-Dokumente.
Als Ausweg und pragmatischer Kompromiß zwischen eineindeutigen Namenspräfixen und Lesbarkeit wurde daher ein zweistufiges Verfahren eingeführt. Es erlaubt die Zuordnung von URIs zu Präfixen. Dieser Vorgang wird als „Bindung“ bezeichnet.
Diese Präfixes können Attributen oder Elementen vorangestellt werden, um sie in bestimmte Namensräume zu übernehmen.
Für die Präfixe gelten dieselben Bildungsgesetze wie für die Element- und Attributnamen. Im Einzelnen legt die Namespace Recommendation fest: (im XML-Namespace-Dokument nachschlagen)
[NS7] Präfix ::= NCName [NS4] NCName ::= (Letter | '_') (NCNameChar)* [NS5] NCNameChar ::= Letter | Digit | '.' | '-' | '_' | CombiningChar | Extender
Anmerkung: Die rechten Seiten der Produktionen beziehen sich entweder auf die dargestellten Definitionen des Namespace-Standards oder auf Syntaxregeln der XML-Recommendation.
Die Bindung einer URI an ein -- gemäß Produktion NS7 frei wählbares -- Präfix geschieht durch das reservierte Attribut xmlns.
Die Syntax hierfür wird mit
[NS2] PräfixedAttName ::= 'xmlns:' NCName
angegeben.
Nach der Bindung der URI an das Präfix kann dieses jedem Element oder Attribut vorangestellt werden, um es in den Namensraum zu übernehmen.
Hierdurch verändert sich die Produktion Name aus der XML-Spezifikation zum qualifizierten Namen, der durch die Voranstellung des Präfixes entsteht. Der rechts vom trennenden Doppelpunkt folgende Elementname stellt den lokalen Namen (innerhalb des Namensraumes dar). Dieser lokale Name darf keinen Doppelpunkt mehr enthalten; insofern schränkt Produktion NS8 in Verbindung mit NS4 die Festlegung der Produktion 5 der XML-Spezifikation ein.
[NS6] QName ::= (Präfix ':')? LocalPart [NS8] LocalPart ::= NCName
Während der Verarbeitung eines XML-Dokuments, das Namensräume nutzt, ersetzt ein XML-Prozessor jedes Auftreten eines deklarierten Präfixes transparent durch die gebundene URI.
Prozessoren, welche die Namensraum-Spezifikation unterstützen, werden als namespace aware bezeichnet. Alle anderen Prozessoren treffen die durch NS6 eingeführte Unterscheidung zwischen Präfix und LocalPart eines qualifizierten Namens nicht und betrachten die Kombination aus Präfix und Element- bzw. Attributnamen als Bezeichner. Die Präfix-URI-Bindung durch das xmlns:...-Attribut wird hierbei als gewöhnliches XML-Attribut betrachtet und führt daher zu keinen Validierungsfehlern. (Die Einschränkung der Produktion 5, ein Name dürfe nicht mit der Zeichenfolge (('X'|'x') ('M'|'m') ('L'|'l')) beginnen, stellt in der XML-Spezifikation lediglich einen Hinweis dar.)
Semantisch bildet die durch xmlns eingeleitete Deklaration ein Pseudoattribut, da es für die maschinelle Verarbeitung vorbehalten und mit festelegter Bedeutung ausgestattet ist, welche durch den XML-Dokumentautor nicht verändert werden kann.
Zusätzlich werden Namensraumdeklarationen durch Programmiersprachenschnittstellen nicht den gewöhnlichen Attributen gleichgestellt betrachtet, sondern nehmen, wie auch im Information Set, dort eine Sonderstellung ein.
Anmerkung: Auf Webseiten und in Mailinglisten finden sich manchmal Formulierungen der Struktur {namespaceName}elementName (z.B. {http://www.w3.org/2001/XMLSchema}element oder {http://www.w3.org/1999/XSL/Transform}template).
Hierbei handelt es sich um eine zwar geläufige, aber nicht spezifikationskonforme Schreibweise!
Sie dient lediglich dazu, das prinzipiell beliebig wählbare Präfix einzusparen und den gewählten Namensraum hervorzuheben.
Strukturen dieses Stils sind jedoch keine gültigen XML-Dokumente!
Angewendet auf das betrachtete Beispiel läßt sich die URI http://www.example.com/sales an das Präfix myNS1 binden. Diese Bindung steht im definierenden Element (local name: rechnung) und allen untergeordneten zur Verfügung.
| Beispiel 10: Dokument mit W3C-konformen Namensräumen |
Download des Beispiels |
![]()
Hinweis: Für das Attribut xmlns kann keine Namensraumdeklaration angegeben werden; es ist spezifikationsgemäß an keinen Namensraum gebunden.
Die Deklaration des Namensraumes mit der Präfixbindung kann auf beliebige hierarchisch höhergeordnete Elemente ausgelagert werden. In der Praxis hat es sich aus Übersichtlichkeitsgründen durchgesetzt, alle in einem XML-Dokument benutzten Namensräume mit ihren Präfixen zu Beginn des Dokuments im Wurzelelement zu definieren.
Das nachfolgende Beispiel zeigt dies anhand eines XHTML-Dokuments, das neben Elementen der Hypertextsprache auch mathematische Formeln und Vektorgraphiken enthält.
| Beispiel 11: Ein XHTML-Dokument mit MathML- und SVG-Inhalten |
Download des Beispiels |
![]()
| Definition 8: Namensraumidentifikation |
Jeder XML-Namensraum wird durch eine gültige URI identifziert. Diese URI dient ausschließlich
der Benennung, daher muß sie nicht auf eine gültige Ressource verweisen.
|
![]()
Überschreiben des Vorgabe-Namensraums:
Aus den Beispielen ist leicht ersichtlich, daß die explizite Angabe des definierten Präfixes für jedes Element eines Namensraumes platzraubend und für die Zuordnung aller Elemente eines Teilbaumes zum selben Namensraum redundant und -- wegen des zusätzlichen Spezifikationsaufwandes -- unpraktikabel ist. Die mehrmalige explizite redundante (identische) Angabe des identifizierenden Präfixes bildet zusätzlich noch eine potentielle Fehlerquelle hinsichtlich Übertragungsfehlern und reiner Tippfehler bei manuell erstellten XML-Dokumenten.
Eine einfache Kompaktifizierungsvariante greift auf die aus den Programmiersprachen geläufigen Regeln für Namensräume zurück. Dort beinhaltet ein explizit geöffneter Block alle enthaltenen Elemente bis zum Blockendesymbol und faßt sie so zu einem Gültigkeitsbereich zusammen.
Dieses Prinzip läßt sich leicht auch auf XML-Dokumente, die immer eine streng hierarchische Baumstruktur aufweisen, anwenden.
Hierzu wird das xmlns-Attribut leicht modifiziert eingesetzt. Wird es ohne nachfolgendes Präfix und unter Weglassung des separierenden Doppelpunktes verwendet, so definiert es einen Vorgabenamensraum (default namespace). Dieser umfaßt neben dem Element, welches das Attribut beinhaltet, auch alle Kindelemente. Eine Ausnahme hiervon bilden untergeordnete Elemente, die explizit durch Präfix oder Redefinition des Vorgabenamensraumes einem anderen Namespace zugeordnet werden.
Das nachfolgende Beispiel zeigt dies für das bereits mit Namenräumen versehene Rechnungsdokument
Die syntaktische Definitionsform der Namensraumüberschreibung als XML-(Pseudo-)Attribut stellt hierbei sicher, daß für ein Element keine mehrmalige Überschreibung des Vorgabenamensraumes vorgenommen werden kann, da in diesem Falle das Attribut xmlns mehrfach im selben Elementkontext auftreten müßte, was der XML-Basisspezifikation widerspräche.
| Beispiel 12: Rechnungsdokument mit überschriebenem Vorgabenamensraum |
Download des Beispiels |
![]()
Durch die Definition des Vorgabenamensraumes für das Element rechnung und all dessen Kindelemente wird derselbe Effekt erreicht wie durch die Präfixangabe im vorangegangenen Beispiel.
Diese Schreibweise stellt lediglich eine Abkürzung der expliziten Qualifizierung jedes einzelnen XML-Namens dar. Insbesondere führt die mehrmalige Redefinition des Vorgabenamensraumes nicht zu kaskadierten Namensräumen. Jeder Namensraum ist von allen umgebenden unabhängig definiert.
So kann das Dokument des XHTML-Beispiels auch dahingehend verändert werden, daß die Namensräume erst an der Stelle im Dokument deklariert werden, an der sie auch benötigt werden.
| Beispiel 13: Ein XHTML-Dokument mit MathML- und SVG-Inhalten, unter Verwendung überschriebener Vorgabenamensräume |
Download des Beispiels |
![]()
Die Namensraumpräfixe können durch den Anwender frei vergeben werden. Sie dienen lediglich der abkürzenden Schreibweise und sind für die Namensraumauflösung unerheblich.
Daher werden zwei Elemente oder Attribute als gleich betrachtet, wenn sie lexikalisch in Namen und Namensraumidentifier übereinstimmen. Hierbei ist es unerheblich, ob der Namensraum explizit durch Präfixangabe oder durch Überschreiben des Vorgabenamensraumes definiert wurde.
Die Elemente der XML-Dokumente aus den Beispielen 14 und 15 befinden sich alle ausnahmslos im Namensraum http://www.example.com.
| Beispiel 14: Namensraumpräfixe 1 |
Download des Beispiels |
![]()
| Beispiel 15: Namensraumpräfixe 2 |
Download des Beispiels |
![]()
Die Abbildung zeigt das Beispieldokument in der Darstellung des W3C-Browsers Amaya.

Im Beispieldokument wird der Vorgabenamensraum dreimal, entsprechend der verschiedenen verwendeten XML-Sprachen, neu gesetzt. So wird auf html und alle direkt untergeordneten Elemente der URI-identifizierte Namensraum http://www.w3.org/1999/xhtml angewendet. head, title und body sowie dessen Kindelemente finden sich demnach, da sie keinen eigenen Namensraum definieren, ebenfalls im so definierten Vorgabenamensraum.mrow als hierarchisch tieferstehendes Element redefiniert den Namensraum zu http://www.w3.org/TR/REC-MathML. Daher werden das Element mrow sowie all dessen Kindelemente (im Beispiel: ellipse) auch diesem zugeordnet.
Die Attribute width, height, cx , ... verfügen über kein explizites Namensraumpräfix und sind daher dem leeren Namensraum zugeordnet.
Auf den MathML-Namensraum folgend wird der Vorgabenamensraum zu http://www.w3.org/2000/svg redefiniert. Auch hier gelten dieselben Regeln, d.h. der überschriebene Vorgabenamensraum erstreckt sich auf alle Kindelemente.
Mit dem schließenden Tag svg endet auch dessen Namensraum. Alle folgenden Elemente befinden sich wieder im umgebenden Namensraum, der zu Beginn des Dokuments mit http://www.w3.org/1999/xhtml festgelegt wurde.
Die nachfolgende Graphik stellt die Namensräume nochmals farblich hervorgehoben dar.
Ein weiteres Beispiel findet sich in der Namespace-Recommendation.

Der XML-Namensraumstandard des W3C sieht die beiden im Vorhergehenden diskutierten Varianten exklusiv zueinander vor. D.h. für ein Element, welchem bereits durch Präfixangabe eine Namensraumzuordnung gegeben wurde, kann nicht zusätzlich der Vorgabenamensraum überschrieben werden. Deklarationen der Form <xyz:abc xmlns="..." ...> sind widersprüchlich; und daher illegal. (in der XML-Namespace Recommendation nachschlagen)
Das abschließende Beispiel 16 zeigt die Verwendung zweier Vokabulare (SVG und MathML), die beide ein mit set benanntes Element definieren.
Durch die Deklaration der jeweiligen Namensräume unterscheiden sich die qualifizierten Namen, die dem (gleichnamigen) Elementnamen die Namensraum-URI voranstellen.
| Beispiel 16: Namensräume im realen Einsatz |
Download des Beispiels |
![]()
Präzedenz des explizit zugeordneten Namensraumes:
Eine explizit durch Präfixzuordnung vorgenommene Namensraumfestlegung besitzt Präzedenz gegenüber dem evtl. überschriebenen Vorgabenamensraum.
Findet daher für ein Element sowohl die Überschreibung des Vorgabenamensraumes, als auch gleichzeitig die Namensraumfestlegung durch explizite Präfixzuordnung statt, so wird das Element demjenigen Namensraum zugeordnet, der durch die URI identifiziert wird, an den das Präfix gebunden ist.
Dies gilt insbesondere auch dann, wenn ein und dasselbe Element sowohl über ein Präfix, als auch eine Überschreibung des Vorgabenamensraumes verfügen.
Das XML-Dokument aus 17 illustriert dies beispielhaft. So wird ElementA -- durch Überschreibung des Vorgabenamensraumes -- dem Namensraum urn:namspaces:Namespace1 zugeordnet und diese Festlegung auch an das Kindelement ElementB weitergegeben.
Das Kindelement ElementC hingegen überschreibt die Vorgabe des Elternelements durch explizite Präfixangabe und ist daher dem durch urn:namespace:Namespace2 identifizierten Namensraum zugeordnet.
Für ElementD findet sich sowohl eine Namensraumdefinition, welche durch Überschreiben des Vorgabenamensraumes zu urn:namespace:Namespace3 stattfindet, als auch eine Präfix-gebundene Definition an den Namensraum urn:namespace:Namespace2. Gemäß der Präzedenz der expliziten Festlegung durch Präfix wird ElementD jedoch ausschließlich dem Namensraum zugeordnet, an den das angegebene Präfix ns1 gebunden ist. Im Beispiel ist dies die URI urn:namespace:Namespace2.
| Beispiel 17: Präzedenzregel |
Download des Beispiels |
![]()
Aufheben der Namensraumzuweisung:
Durch Überschreibung des Vorgabenamensraumes mit der Zeichenkette leeren Inhalts -- formal der Zuweisung der leeren URI als Namensraumidentifikator -- kann eine bestehende Namensraumdefinition aufgehoben werden. Als Resultat entsteht eine Situation identisch zu einem Dokument ohne festgelegte Namensräume, d.h. die Elemente finden sich im leeren Namensraum.
| Beispiel 18: Aufheben von Namensraumdeklarationen |
|
![]()
Das Beispiel 18
zeigt die notwendigen Deklarationen zur Aufhebung der
Vorgabenamensraumdefinition.
So wird zwar für das Element
table und alle seine Kindelemente der
Vorgabenamensraum auf http://www.w3.org/TR/REC-html40
gesetzt, dies jedoch für die Kindelemente Vorname,
Nachname, Straße, PLZ und
Ort durch die Festlegung xmlns=""
explizit für das jeweilige Element aufgehoben.
Die Aufhebung von definierten Namensräumen kann ausschließlich durch die Überschreibung des Vorgabenamensraum erfolgen. Eine Bindung der leeren URI an ein Präfix zur späteren Verwendung ist nicht zugelassen.
Namensräume für Attribute:
Abweichend von der Mimik für Elemente, dort wirkt sich ein überschriebener Vorgabenamensraum
auch immer auf die Kindelemente aus, wird eine Namensraumdeklaration auf Elementebene nicht auf
Attribute propagiert.
Diese Festlegung der Spezifikation mag insbesondere unter Kenntnis der Baumstruktur der Infosets, welche
Attribute und Elemente gleichermaßen als Kindknoten der beherbergenden Elementinformationseinheit darstellt,
verwundern. Eine mögliche Begründung dieser Asymmetrie mag in der besonderen Rolle der Attribute zur
Informationsdarstellung liegen. So wird teilweise damit argumentiert, daß Attribute üblicherweise unabhängig
vom aktuell umgebenden Element sein sollten und daher nur zur Darstellung von Daten herangezogen werden
sollten, die nicht über einen direkten Bezug zum sie umgebenden Element verfügen.
In der Konsequenz müssen Attribute immer explizit mit einem Namensraumpräfix versehen werden, um sie einem
Namensraum zuzuordnen.
Beispiel 19 zeigt die Anwendung der Namensräume auf
Attribute. So befinden sich weder das Attribute att1 des Elements ElementB, noch dasjenige
von ElementD in einem Namensraum. Das mit dem Wert XYZ versehene Attribut
att2 des Elements ElementC wird hingegen -- aufgrund des explizit angegebenen Präfixes --
dem Namensraum http://www.example.com/NS2 zugeordnet.
Ferner illustriert ElementC die Rolle der Namensräume als Bestandteil des identifzierenden
Namens von Elementen und Attributen. Aufgrund der Interpretation des Namensraumes als Benennungsbestandteil
darf das att2 benannte Attribut mehrfach auftreten, da die Zuhilfenahme des Namensraumes
die eindeutige Identifikation gestattet.
| Beispiel 19: Namensräume für Attribute |
|
![]()
| Definition 9: Namensraumvererbung |
Namensräume, die durch Überschreiben des Vorgabenamensraumes zugewiesen werden wirken sich ausschließlich auf Elemente und deren direkte oder transitive Kindelemente aus, sofern diese den Namensraum nicht wieder verändern. Namensräume, die durch explizite Präfixangabe zugewiesen werden, wirken sich ausschließlich auf dasjenige Element aus vor dessen Name das Präfix plaziert ist. Namensräume für Attribute werden ausnahmslos durch explizite Präfixangabe festgelegt und gelten ausschließlich für das Attribut selbst. |
![]()
Ausgehend von der Vererbungsregel für Namensräume, sowie der Präzedenz expliziter Präfixangaben lassen sich daher folgende Auswertungsregeln definieren:
Ein Element befindet sich in demjenigem Namensraum ...
Ein Attribut befindet sich in demjenigem Namensraum, der durch explizite Präfixangabe festelegt wurde.
Internationale URIs und Namensraumidentifikatoren:
Die Berücksichtigung von Zeichen, die in XML v1.1 zugelassenen, deren Nutzung in den klassischen URIs nach RFC 2396 bzw.
RFC 2732 jedoch
untersagt ist, führt zur Einführung des neuen Begriffes des
Internationalized Resource Identifiers (IRI). Diese
Neuschöpfung stellt im Kern eine URI-Fassung dar innerhalb der
Leerzeichen sowie diverse Sonderzeichen zulassen sind. Diese
internationalisierten Identifikatoren werden durch einen im
Spezifikationsentwurf festgelegten Algorithmus in syntaktisch
korrekte URIs umgewandelt.
Beispiel 20 zeigt gültige IRIs und jeweils dahinter in
Klammern angegeben die daraus resultierende URI-Darstellung.
| Beispiel 20: |
|
![]()
Kompatibilität zu älteren Dokumenten:
Elemente, für die weder ein expliziter Namensraum durch Präfix definiert ist, noch ein Namensraum von einem Elternelement übernommen werden kann, sind einem leeren Namensraum zugeordnet; konzeptionell entspricht dies einem NULL-Präfix.
Somit befinden sich alle Elemente, die keinem Namensraum angehören, automatisch in einem gemeinsamen Namensraum, der an keine URI gebunden ist.
Zusammenfassend gelten somit folgende Prinzipien:
| Web-Referenzen 6: Weiterführende Links |
XML-Namespace Recommendation Namespace Recommendation in deutscher Übersetzung Namespace Tutorial @ Zvon.org Tim Bray: Namespaces by Example Hintergrundartikel: Namespaces in XML Adopted by W3C (Tutorial) Simon St. Laurent: Namespaces in XML Roland Bourret: XML Namespaces FAQ |
![]()
Neben den in der Vergangenheit zur Sprachdefinition verwendeten Document Type Definitions ist in jüngerer Zeit ein alternativer Ansatz in den Blickpunkt des Interesses gerückt: die XML-Schemasprachen.
Sie setzen die Emanzipation der Metasprache XML von ihrer Vorgängersprache SGML fort. Bereits in engem zeitlichem Bezug zur Veröffentlichung der XML-Recommendation wurde mit XML Data ein erster Ansatz vorgestellt. In der Zwischenzeit fanden verschiedene konkurrierende Vorschläge ein breites Interesse. Übereinstimmende Zielsetzung aller verschiedenen vorgeschlagenen Schemasprachen ist die Schaffung eines Sprachdefinitionsmechanismus, der die Dokumenten-orientierten Strukturen und Inhaltsmodelle der DTD überwindet.
An die Spitze der Bemühungen setzte sich eine Arbeitsgruppe des W3C zur Definition einer XML-Schemasprache, unter Berücksichtigung der bekanntesten und verbreitetsten Vorschläge. Durch sie wurde im Mai 2001 der XML Schema-Standard des W3C veröffentlicht.
Der Begriff Schema ist der im Datenbankumfeld gebräuchlichen Terminologie entlehnt. Dort bezeichnet er Informations- oder Datenmodelle als Konstruktionsvorlage oder Dokumentation eines Datenbankdesigns. Hierzu muß ein Schema nicht unbedingt in einer graphischen Datenmodellierungssprache vorliegen, sondern kann beispielsweise auch die Tabellenstruktur einer relationalen Datenbank bezeichnen.
Zur Notwendigkeit einer Schemasprache:
Zum Zeitpunkt der Konzeption der Metasprache SGML war das Anwendungsfeld klar umrissen und im wesentlichen auf die Digitalisierung vormals papiergestützter Dokumentation festgelegt. Daraus erklärt sich auch die Mächtigkeit der Document Type Definition, der angebotenen Grammatiksprache zur Darstellung der Dokumentstrukturen.
Insbesondere war weder die Daten-orientierte Verwendung von SGML, noch die rund 30 Jahre später einsetzende Weiterentwicklung (eigentlich: Reduktion) zur eXtensible Markup Language abzusehen.
Die inzwischen eingesetzte breite Anwendung von XML-Sprachen zur Darstellung beliebiger Inhalte läßt jedoch die Beschränkungen und Unzulänglichkeiten des DTD-Mechanismus für diesen Anwendungen offenkundig werden.
Nachfolgend sind einige der durch Nutzung des DTD-Mechanismus zur Beschreibung Daten-intensiver Strukturen induzierten Einschränkungen zusammengestellt:
child elements, PCDATA, mixed content sowie das leere Inhaltsmodell EMPTY.Technische Ansätze:
Prinzipiell lassen sich die in der Vergangenheit vorgeschlagenen Ansätze zur Definition einer Schemasprache in vier Kategorien unterscheiden:
Die naheliegendste Option dürfte die Erweiterung des bestehenden DTD-Sprachumfanges bilden. Durch geeignete Modifikationen und Ergänzungen ließen sich alle, mit Ausnahme der letzten, identifizierten Unzulänglichkeiten beheben.
Konzeptionell lassen sich zwei Erweiterungsvarianten aufzeigen. Zunächst die Möglichkeit, die XML-DTDs um Elemente der ursprünglichen SGML-DTD zu erweitern. In der Konsequenz nähert sich XML, positiv formuliert, wieder der Ausdrucksmächtigkeit der Ursprache SGML an. Negativ formuliert, kann jedoch XML auf diesem Wege niemals Inhaltsstrukturen ausdrücken, die nicht durch SGML ausdrückbar sind, da die Mächtigkeit des SGML-DTD-Mechanismus eine natürliche Obergrenze der Erweiterbarkeit darstellt. Zusätzlich ist anzumerken, daß ein solcher Ansatz der ursprünglichen Intention der XML-Entwicklung -- ein leichter einsetzbares SGML zu schaffen -- entgegenläuft.
Eine der bekannten Ideen zur Erweiterung des DTD-Mechanismus stellt Datatypes for DTDs (DT4DTD) dar.
Alternativ zur Erweiterung hin zur SGML-Mächtigkeit ließe sich der bestehende XML-DTD-Mechanismus um neue zusätzliche Konstrukte anreichern, die nicht Bestandteil der SGML-DTD-Syntax sind. Dieser Ansatz böte den Vorteil, den Vorgängerstandard nicht berücksichtigen zu müssen und beliebige Erweiterungen in Syntax und Semantik einbringen zu können. Allerdings würde damit eine zentrale Forderung der XML-Entwicklung, die sich bereits im Abstract der XML-Recommendation findet, nicht berücksichtigt: die Untermengenbeziehung zu SGML. Durch eine Erweiterung, welche über die SGML-Mächtigkeit hinausreicht, würden legale (well formed und sogar valid) XML-Dokumente entstehen, die keine gültigen SGML-Dokumentinstanzen wären.
Die nachfolgende Graphik veranschaulicht die beiden Erweiterungsoptionen und die Argumente der geführten Diskussion.

Die im zweiten Punkt angedeutete Umsetzung ist durch eine programmiersprachliche Verarbeitung der XML-Dokumente motiviert. Aus Sicht dieser Anwendungsfacette ist ein Schemamechanismus idealerweise so ausgelegt, daß er die transparente Umsetzung in Applikationsdatenstrukturen ermöglicht. Dahinter steht der Wunsch, den impedance mismatch, mithin den zu leistenden Abbildungsaufwand zwischen XML-Konstrukten und Datenstrukturen, möglichst gering zu halten.
Beispielsweise greift der -- durch den Einsatz im e-Commerce-System der Firma CommerceOne bekannt gewordene -- Vorschlag Schema for Object-Oriented XML (SOX) zur Definition der notwendigen Semantik der angebotenen Schemaprimitiven auf die bekannte plattformunabhängige Programmiersprache Java zurück.
Die aktuelle Version der Schemasprache SOX, die zur Definition der XML-Sprache xCBL eingesetzt wird, findet sich unter xCBL.org.
Der dritte technische Ansatz weist auf eine alternative Interpretation der XML-Grammatikstruktur hin. So spiegelt ein Schema auch immer Wissen über Struktur und Inhalt eines betrachteten Problembereichs wieder.
Der bekannteste Vorschlag -- die Document Content Description (DCD) -- nutzt zur Definition der Wissensstrukturen eines XML-Dokuments das Resource Description Framework (RDF) des World Wide Web Consortiums.
Der Ansatz hat sich durch Referenzimplementierungen durchaus als tragfähig und, wegen der RDF-basiertheit, als allgemein verwendbar erwiesen. Jedoch liegt hierin auch die offensichtlichste Limitierung. RDF als Metasprache der Schemasprache legt bereits eine gewisse Strukturierung aller Schemata zugrunde, da jedes gültige DCD-Schema definitionsgemäß ein RDF-Dokument darstellt. Ebenso ist die Semantik der eingesetzten RDF-Elemente bereits durch diese Spezifikation vorgegeben. Beide Punkte zusammengenommen offenbaren eine ausgeprägte Abhängigkeit von den weiteren RDF-Aktivitäten des World Wide Web Consortiums, die bisher nicht auf die Interdependenz von Schemasprache und Wissensbeschreibungsformat ausgerichtet ist.
Positiv fällt an DCD die Verwendung von XML zur Beschreibung von XML-Sprachen auf, womit auch die letzte der erhobenen Anforderungen zu erfüllen wäre.
Die Verknüpfung von RDF mit DCD als Schemasprache birgt allerdings ein potentielles Problem hinsichtlich der Validierbarkeit der entstehenden Strukturen. Durch den Rückgriff von DCD auf RDF entsteht bei der Angabe eines Schemas für RDF ein transitiver Zirkelschluß. In der Konsequenz wird zur Validierung eines XML-Dokuments, welches einer mittels DCD-formulierten Grammatik folgt, neben dem eigentlichen DCD-Schema des Dokuments auch das DCD-Metaschema und dessen Semantik-liefernde RDF-Beschreibung benötigt.
Diese Beschränkung mildert die vierte Familie von XML-Schemasprachen ab. Sie umfaßt die meisten Vorschläge, die alle als eigenständige XML-Sprachen ausgelegt sind; daher definieren sie ein eigenständiges XML-Vokabular zur Darstellung der benötigten XML-Strukturen, sowie die zugehörige Semantik.
In der Folge sind sie für die Meta-Schemaebene selbstbeschreibend. Das bedeutet das Schema eines Schemas kann durch sich selbst validiert werden. Da dieser Validierungsschritt statisch nur einmal erfolgen muß, kann er durch Schemawerkzeuge vorweggenommen werden.
In dieser Kategorie sind die meisten der bisher vorgeschlagenen Schemadialekte einzuordnen.
Die größte Bedeutung haben kontextfreie reguläre Sprachen zur Spezifikation von XML-Sprachstrukturen erlangt.
Eine Sprache dieses Typs entwickelt auch die W3C-Arbeitsgruppe zur Definition eines XML-Schemasprachstandards. Insbesondere berücksichtigt diese Aktivität explizit die Vorgängersprachen XML Data, DCD, SOX sowie Document Definition Markup Language. Die erwähnten konkurrierenden Vorschläge unterscheiden sich semantisch lediglich in Nuancen, bieten dem Anwender jedoch teilweise (optisch) stark unterschiedliche Konstrukte zur Syntaxspezifikation an.
Einen strukturell unterschiedlichen Ansatz verfolgt die durch Rick Jelliffe vorgeschlagene Sprache Schematron. Sie interpretiert ein Schema als Sammlung von Regeln, denen ein gegebenes Dokument genügen muß, um als gültig akzeptiert zu werden. Dies erlaubt die Formulierung mächtiger konktextsensitiver Einschränkungen, die während des Validierungsvorganges geprüft werden.
Die Umsetzung dieser Schemasprache setzt auf den XML-Standards XPath und XSLT auf.
W3Cs XML-Schema:
Jenseits aller existierenden verschiedenen Sprachvorschläge kommt dem W3C-Standard der XML Schema Description Language (XSD) die größte praktische Bedeutung zu.
Tim Berners-Lee verkündete in der Eröffnungsrede der WWW-Konferenz in Hong Kong am 2. Mai 2001 die Verabschiedung als Recommendation. Gleichzeitig deutete er bereits weitere Schema-Aktivitäten des World Wide Web Consortiums an.
XML-Schema bildet zusammen mit XML v1.0 2nd edition und den Namensräumen die Basis aller weiteren W3C-XML-Sprachstandards.
Aus formalen Gründen ist nicht mit dem Ersatz der DTD durch Schema zu rechnen. Jedoch werden mittelfristig neu entwickelte XML-Sprachen keine Grammatiken mehr in der Syntax der DTD entwickeln, sondern direkt Schemata definieren.
XSD bildet eine vollständig in XML-Syntax formulierte kontextfreie reguläre Grammatik zur Formulierung beliebiger XML-Strukturen ab. Hierbei handelt es sich um die bekannten Grundprimitive Element und Attribut
Gleichzeitig wurde, neben zahlreichen anderen Neuerungen, die Kommentarsyntax für Schemata neu definiert.
Inhaltlich gliedert sich der XSD-Sprachvorschlag in zwei große Teilbereiche: Part 1: Structures zur Definition von Inhaltsmodellen für Elemente, Attributstrukturen und wiederverwendbaren Strukturen und Part 2: Datatypes zur Festlegung diverser inhaltlicher Charakteristika wie Datentypen und konsistenzgarantierende Einschränkungen.
In beiden Teilen werden XML-Namensräume explizit berücksichtigt. Konzeptionell rekonstruiert XSD-Part1 zunächst die bekannte Mächtigkeit der DTD um so die evolutionäre Weiterentwicklung bestehender XML-Sprachen zu ermöglichen.
Der zweite Teil der XSD-Spezifikation definiert ein eigenständiges Typsystem, das neben der naheliegenden Verwendung im ersten Teil der Schemasprache XSD auch in anderen W3C-Arbeitsgruppen Verwendung findet. Inhaltlich baut auch Part2 auf den in der DTD definierten Typen auf und erlaubt zunächst direkt ihre Angabe in Schemata. Darauf aufbauend wird eine Fülle verschiedenster Typen angeboten, die an die verschiedenen verfügbaren Typsysteme aus den Programmiersprachen, Datenbanken und internationalen Standards angelehnt sind.
Alle durch XSD definierten Elemente, d.h. alle Primitive zur Definition eines eigenen Schemas, befinden sich im Namensraum http://www.w3.org/2001/XMLSchema, der üblicherweise an das Präfix xsd gebunden wird. Elemente und Attribute aus XML-Schema, die in Instanzdokumenten verwendet werden könne sind im Namensraum http://www.w3.org/2001/XMLSchema-instance (übliches Präfix xsi) organisiert.
Wegen des Umfanges der offiziellen Schemadokumente wird zusätzlich durch das W3C ein Part 0: Primer herausgegeben. Er stellt die beiden XSD-Teile in der Zusammenschau an Beispielen dar.
Schemareferenz:
Jedes XML-Schema bildet als XML-Dokument eine eigenständige Speichereinheit, üblicherweise eine Datei.
Die Verbindung zwischen Schema und beschriebenem Dokument wird durch das in der XSD-Spezifikation vordefinierte Attribut schemaLocation bzw. noNamespaceSchemaLocation definiert. Eines dieser Attribute muß zwingend im Wurzelelement des XML-Dokuments angegeben werden.
Legt das Schema keinen Namensraum für die enthaltenen Deklarationen fest, d.h. alle darin deklarierten Elemente befinden sich im Vorgabenamensraum, so findet sich die Schemareferenz in noNamespaceSchemaLocation; andernfalls in schemaLocation.
Das nachfolgende Beispiel zeigt die Deklaration:
| Beispiel 21: Definition einer Schemareferenz |
|
![]()
Im Beispiel wird zunächst der XML-Schema-Instanzen-Namensraum an das Präfix xsi gebunden. Dies ermöglicht die Einbindung von Elementen und Attributen aus der Schemaspezifikation in das eigene Dokument.
Als erste Nutzung eines solchen Elements aus XSD wird das Attribut schemaLocation im Wurzelelement mit der URI des Schemas als Wert belegt. Die Deklaration des XSI-Namensraumes ist daher zwingend. Die angegebene URI kann zur Ermittlung des Schemas für Validierungszwecke durch einen XML-Prozessor genutzt werden.
Aufbauend auf dem Begriff der Wohlgeformtheit definiert XML-Schema den der Schemagültigkeit als höhere Qualitätsstufe eines XML-Vokabulars:
| Definition 10: Gültigkeit hinsichtlich eines Schemas |
Ein XML-Dokument heißt gültig hinsichtlich eines Schemas (schema valid), wenn es über ein Schema verfügt, und konform zu diesem aufgebaut ist. |
![]()
Aufgrund der Realisierung der Schemasprache als XML-Sprache ist jedes Schema auch ein XML-Dokument. Daher eröffnet sich die Möglichkeit, das Schema selbst durch ein Schema zu beschreiben. Dieses Schema für Schema -- auch Metaschema genannte -- XML-Dokument erlaubt die Validierung (im Sinne der schema validness) jedes Schemas. Damit erfüllt sich eine der Anforderungen an den Schemamechanismus: die Validierbarkeit der erstellten Schemata selbst, was für DTDs nicht gegeben war. In der praktischen Anwendung zeigt sich dies in der Möglichkeit, erstellte Schemata mit denselben Werkzeugen zu analysieren, verarbeiten und zu prüfen, die auch für Instanzdokumente verwendet werden.
Da das Metaschema selbst wiederum ein XML-Dokument ist, folgt, daß hierfür auch ein Schema angegeben werden kann. Die XML-Standardisierung hat hier -- nicht zuletzt um eine unendliche Reihung zur Validierung notwendiger Schemata zu vermeiden -- den Ansatz gewählt, das Schema für Schema durch sich selbst zu beschreiben.
Die Abbildung stellt die getroffenen Aussagen und Validierungsbeziehungen nochmals graphisch zusammen.

Die Schema-Definition:
Wuzelknoten jedes XSD-Dokuments ist das Element Information Item schema. Alle Definitionen eines Schemas sind direkte Kindknoten dieses Elements oder dessen Kindknoten.
Durch die Attribute des schema-Elements werden verschiedene Eigenschaften festgelegt, die für alle im Schema definierten Elemente und Attribute gelten.
Zunächst wird durch eine Reihe von Attributen das Verhalten des Schemas in Bezug auf Namensräume festgelegt. Als Besonderheit eines XML-Schemas fällt hier die ständige Berücksichtung von mindestens zwei Namensräumen ins Auge. Während ein Schema mit Elementen des Schemanamensraumes aufgebaut wird, trifft es zeitgleich Aussagen über einen zweiten Namensraum -- den Namensraum des Vokabulars für das das Schema erstellt wird. Dieser Namensraum wird Zielnamensraum (target namespace) genannt.
Daher findet sich im Attribut
targetNamespace die URI des Zielnamensraumes. In
diesen Namensraum werden automatisch alle durch das Schema
deklarierten Elemente und Attribute übernommen. Als Konsequenz
müssen diese in jedem Schema-gültigen XML-Dokument im
entsprechenden Namensraum auftreten. Hierbei wird nicht zwischen
expliziter Namensraumdeklaration durch ein gebundenes Präfix und
impliziter Deklaration durch Überschreiben des Vorgabenamensraumes
unterschieden.
Durch Angabe der Attribute
elementFormDefault und
attributeFormDefault kann der durch
targetNamespace implizierte Namensraumzwang für das
XML-Instanzdokument gelockert werden. Wird der Wert der beiden
Attribute auf unqualified gesetzt, so können die
Attribute auch außerhalb des Zielnamensraumes auftreten. Dies
entspricht auch dem Vorgabeverhalten.
Definition von Elementen:
Als Obermenge der Ausdrucksmächtigkeit der DTD unterstützt auch XSD die Inhaltsmodelle
Generell wird jedes Element durch das XSD-Element element ausgedrückt.
Während die DTD für unstrukturierten Inhalt ausschließliche uninterpretierte Zeichenketten unterstützt, wird die Ausdrucksmächtigkeit durch XML-Schema deutlich gesteigert.
XML-Schema Part 2 definiert insgesamt 44 Primitivtypen. Darunter finden sich die bereits in der DTD angebbaren Element- und Attributtypen, sowie eine Fülle Neuer.
Im Kern zerfallen die XSD-Typen in drei Typklassen:
string besteht zwar aus einzelnen Zeichen) bzw. falls erkennbar, dem nicht explizit unterstützten Zugriff auf die Komponenten (date bietet keine Zugriffsmöglichkeit auf die Komponenten Tag, Monat und Jahr), verweisen.Durch Erweiterungs- und Aggregationsmechanismen ergibt sich das in der nachfolgenden Abbildung dargestellte Typsystem.

Die Tabelle stellt die angebotenen Typen mit einigen Beispielen dar:
| Tabelle 6: Typen in XSD-Schema Part 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
![]()
Die einfachste Form zur Definition eines Elements mit unstrukturiertem typisierten Inhalt lautet:
<xsd:element
name="elementName"
type="typeName"/>
XSD definiert ferner folgende Charakteristika für Elemente, die durch Attribute der Elementdeklaration ausgedrückt werden:
true gesetzt, darf ein solches Element nicht in einem XML-Dokument auftreten. Es kann ausschließlich zur Strukturierung des Schemaentwurfs eingesetzt werden und als Basis von Spezialisierungen dienen.falseextension, restriction und substitution oder der Einzelwert #all.restriction gesetzt, so dürfen keine (einschränkend) abgeleiteten Typen Ausprägungen des Originaltyps in Instanzdokumenten ersetzen. Dasselbe gilt für extension oder als Substitutionsgruppen deklarierte Typen (substitution-Belegung).#all versammelt alle möglichen Varianten und verbietet generell die Ersetzung eines Elements durch andere.block identisch, nur daß durch dieses Attribut die Vererbungsmechanismen bereits auf Schemaebene verboten werden, während block ihre Nutzung im Instanzdokument einschränkt.qualified (Namensraumpräfix muß angegeben werden) und unqualified.1 belegt.unbounded zur Kennzeichnung beliebig vieler Auftreten.1 belegt.true oder false, was auch als Vorgabe bei Fehlen dieses Attributs angenommen wird.Nachfolgend sind einige Elementdeklarationen für unstrukturierten Inhalt versammelt
| Beispiel 22: |
|
![]()
Die Deklaration geburtsdatum definiert ein XML-Element des Typs date zur Darstellung eines Datums. Weitere Festlegungen sind nicht getroffen, daher wird das Element mit minOccurs und maxOccurs 1 belegt, wodurch es als zwingend anzugebend (mandatory) und skalar (d.h. nicht mengenwertig) ausgewiesen wird.pi legt die gleichnamige mathematische Konstante fest. Als Datentyp wurde double, eine Gleitkommazahl mit doppelter Genauigkeit gewählt. Als konstante Belegung wird durch das fixed Attribut der entsprechende Zahlenwert festgelegt. Daher muß eine Vorgabebelegung durch das Attribut default nicht erfolgen; gemäß Schema-Spezifikation darf sie sogar nicht erfolgen, fixed und default schließen sich gegenseitig aus. Um eine weitere Spezialisierung des Elements durch Vererbung oder Aggregation zu verhindern wird der Wert von block auf #all gesetzt, wodurch die Teilnahme an allen Typbildungsmechanismen unterbunden wird.
Die Definition für vorname nutzt als Datentyp den token, der automatisch mehrfache, führende und abschließende Leerzeichen sowie sonstige Formatierungssymbole entfernt. Ferner kann dieses Element beliebig häufig auftreten -- maxOccurs ist daher auf unbounded gesetzt. Die Fixierung der minimalen Auftrittshäufigkeit auf 1 (minOccurs) entspricht der Vorgabebelegung.
Für das Element artikelNummer ist als Typ NCName ausgewählt, was beliebigen Zeichenketten -- die keinen Doppelpunkt enthalten -- entspricht. Darüberhinaus ist das Attribut form mit dem Wert qualified versehen. Dies führt dazu, daß das Namensraumkürzel für dieses Element zwingend im Instanzdokument anzugeben ist.
Zur Umsetzung des freien Inhaltsmodells, das beliebige Inhalte aus den definierten Elementen und freien Texten zuläßt, wird ebenfalls auf das Typsystem zurückgegriffen.
Wird das type Attribut nicht belegt, so wird gemäß Vorgabe der Typ anyType angenommen. Elemente dieses Typs können beliebige wohlgeformte Inhalte beherbergen.
Die beiden nachfolgenden Angaben sind daher äquivalent.
<element
name="elementName"
type="xsd:anyType/>
<element name="elementName"/>
XSD prägt den bereits im Kontext der DTD genutzten Typbegriff (dort beschränkt er sich lediglich auf verschiedene Darstellungsformen uninterpretierter Zeichenketten) strenger. Dies zeigt sich deutlich in der Existenz des XSD-Elements complexType. Es führt die Möglichkeit einer expliziten, d.h. von der Verwendung losgelösten Typbildung, ein. Syntaktisch kann die complexType-Definition sowohl innerhalb einer Elementdefinition, als auch separat erfolgen.
Den einfachsten Anwendungsfall bildet die eingebettete leere complexType-Definition zur Darstellung des leeren Inhaltsmodells.
Die Syntax hierfür lautet (der XSD-Namensraum sei an das Präfix xsd gebunden):
<xsd:element
name="elementName">
<xsd:complexType/>
</xsd:element>
Ein XML-Schema-validierender Parser verhält sich in diesem Falle identisch zu einem (DTD-)validierenden Parser. Daher werden für die obige Festlegung ausschließlich die beiden Darstellungsformen zur Angabe eines leeren Elements (<elementName/> bzw. <elementName></elementName>) akzeptiert.
Die Befüllung des complexType-Elements leitet direkt zum wichtigsten Inhaltsmodell über, dem explizit angegebener Kindelemente.
Zur Festlegung der Elementreihenfolge definiert XML-Schema das Element sequence, welches die Angabe der Kindelemente in genau der im Schema angegebenen Reihenfolge erzwingt.
Das Auswahlinhaltsmodell (auch: Selektionsmodell) --- welches alternativ das Auftreten beliebiger Elemente definiert --- wird entsprechend durch das XSD-Element choice ausgedrückt.
Eine besondere Variante des Selektionsmodells stellt die all-Gruppe dar. Es erlaubt die Angabe der Kindelemente in beliebiger Reihenfolge.
Die drei Ausgangsvarianten können im Rahmen einer Elementdefinition beliebig geschachtelt und auf diesem Wege kombiniert werden.
Am Beispiel der Elementdefinitionen der Projektverwaltung:
| Beispiel 23: Einige Elementdefinitionen |
Download des Beispiels |
![]()
Das Schema enthält alle Elementdefinitionen für die Projektverwaltung. Innerhalb jedes element-Elements sind die entsprechenden Kindelemente in sequence-Strukturen eingebettet. Die Elemente müssen daher in der Reihenfolge ihres Auftretens im Schema auch im Instanzdokument wiedergegeben werden.
Von besonderem Interesse ist die Definition des Qualifikationsprofils. Es handelt sich dabei um ein mixed content model, ausgedrückt durch das Boole'sche Attribut mixed (in Spezifikation nachschlagen).
Darüberhinaus enthält das Beispiel neben lokalen Elementdeklarationen, die sich vollständig im Elternelement finden (wie Vorname, Nachname und Qualifikation), auch globale Elementdeklarationen, die zunächst deklariert und in einem zweiten Schritt durch Referenzierung als Kindelemente verwendet werden (wie Person und Projekt innerhalb Projektverwaltung, oder Qualifikationsprofil innerhalb des Elements Person). Hierdurch können vollständige Elemente an verschiedenen Stellen im Schema referenziert und so verwendet werden. Die Definition ist der lokalen ebenbürtig und wird im Instanzdokument identisch behandelt. Zusammenfassend läßt sich festhalten: Mit dem Referenzierungsmechanismus für Elemente kann eine einfache Form der Wiederverwendung umgesetzt werden.
Den Zeichenketten-artigen Elementtypen wurde durchgehend der XSD-Typ string zugewiesen.
Durch die Referenzierungsmöglichkeit existiert eine erste Möglichkeit zur Wiederverwendung bereits im Schema definierter Elemente. Jedoch werden Elemente hierbei zwingend in ihrer vollständigen Definition, d.h. Name, Typ und Inhaltsmodell, eingebunden.
XML-Schema bietet die Möglichkeit, strukturierte Typen, die ausschließlich durch ihr Inhaltsmodell definiert werden, festzulegen. In der Konsequenz verändert sich der durch die DTD formulierte Typbegriff hin zu einer eher an den Programmiersprachen orientierten Sichtweise, da die Benennung des Typs von der Namensgebung der typisierten Instanz separiert wird.
Syntaktisch erfolgt die Typbildung durch die Benennung des complexType-Elements durch ein Attribut name. Um die mehrfache Verwendung eines solchen Typen zu ermöglichen, muß seine Definition zwingend auf einer Baumstufe erfolgen, die für alle nutzenden Elemente erreichbar ist. Üblicherweise werden daher diese Definitionen auf der ersten Stufe, direkt unterhalb des Wurzelknotens, plaziert.
Zur Unterscheidung dieser benannten komplexen Typen werden die bisher genutzten -- namenlosen Typen -- als anonyme komplexe Typen bezeichnet.
Das nachfolgende Beispiel zeigt die Definition eines benannten komplexen Typen am Beispiel des Elements Person:
| Beispiel 24: Nutzung benannter komplexer Typen |
Download des Beispiels |
![]()
Das Schema zeigt die Definition des komplexen Typen PersonType. Dieser Typ wird zur Festlegung des Inhaltsmodells des Elements Person verwendet.
Definition eigener Datentypen durch Vererbung:
Zur Unterstützung von Wiederverwendung und Erhöhung der Strukturierung des Entwurfs definiert XSD ein Vererbungskonstrukt zur Bildung neuer komplexer Typen auf der Basis bereits bestehender.
Zwei verschiedene Ableitungssemantiken werden angeboten:
Das nachfolgende Beispiel zeigt die Anwendung der einschränkenden Ableitung.
Hierbei erbt der benannte komplexe Typ childType von parentType. Innerhalb des -- aus syntaktischen Gründen notwendigen -- Elements complexContent findet sich die Definition der Vererbung im Element restriction, das base-Attribut verweist auf den benannten Elterntypen.
Der Inhalt des restriction-Elements gleicht der Inhaltsmodelldefinition des komplexen Typen: Auch hier werden Elemente und ihre Auftrittsstruktur (im betrachteten Beispiel sequence) angegeben. Die Elementdefinition des Elements elementA in childType schränkt die gleichnamige Elementdefinition innerhalb des Elterntypen ein. Nachvollziehbar wird diese Einschränkungsbeziehung zwischen short und int bei Betrachtung der Datentyphierarchie und der Typdefinition der verwendeten Primitivtypen. So bildet short per definitionem eine eingeschränkte Untermenge von int an. (Die entsprechende XSD-Definition findet sich im Schema für Schema).
Die beiden Elementdefinitionen usage1 und usage2 zeigen die Verwendung der anwenderdefinierten Typen.
| Beispiel 25: Einschränkende Typableitung |
Download des Beispiels |
![]()
Durch das strukturierte Inhaltsmodell ergeben sich über die reine Typisierung hinausgehende Möglichkeiten zur Einschränkung der Inhalte. Die nachfolgende Tabelle stellt einige Varianten zusammen.
| Tabelle 7: Beispiele für zulässige Restriktionen | ||||||||||||||
|
![]()
Die direkte Umkehrung der einschränkenden Spezialisierung bildet die erweiternde Spezialisierung. Sie greift nicht verändernd auf die Elemente des Supertyps zu, sondern definiert zusätzliche neue.
Untenstehendes XSD-Schema zeigt dies am Beispiel des Supertyps parentElement, der durch das abgeleitete Kindelement childElement erweitert wird. Hierzu definiert childElement ein zusätzliches elementB.
| Beispiel 26: Erweiternde Typableitung |
Download des Beispiels |
![]()
Zusätzlich sieht XML Schema die Möglichkeit vor, komplexe Typen von simplen abzuleiten. Dies mag auf den ersten Blick ungewöhnlich erscheinen,
eröffnet es doch scheinbar einen Weg, unstrukturierte Typen in strukturierte zu überführen.
Bei näherer Betrachtung offenbart sich jedoch, daß hier lediglich der Ableitungsbegriff überladen wurde, um einen einfachen Weg zur Verknüpfung der beiden Inhaltsmodelle strukturierter „XML-artiger“ Inhalt -- wie er durch complexTypes repräsentiert wird -- auf der einen, und unstrukturierter Inhalt -- wie er durch die einfachen Datentypen repräsentiert wird -- auf der anderen Seite, zu erhalten.
| Beispiel 27: Ableitung eines komplexen Typen von einem Simplen |
Download des Beispiels |
![]()
Durch die im Beispiel dargestellte Syntax wird es ermöglicht unstrukturiert-getypten Elementen Attribute zuzuordnen, obwohl diese eigentlich Bestandteil der Definition komplex-getyper Elemente sind.
So wird im Beispiel dem Element Vorname sowohl der simple Typ string, als auch durch den Ableitungsmechanismus das Attribut rufname -- im Rahmen eines complexType, zugeordnet.
Die Typisierung des Elements erfolgt hierbei nicht durch das
type-Attribut innerhalb der Elementdeklaration,
sondern innerhalb der simpleContent-Festlegung.
Neben der anwenderdefinierten Bildung komplexer Typen steht es dem XSD-Modellierer auch offen, eigene (primitive) Datentypen festzulegen oder eigene Typen von bestehenden abzuleiten.
Hierfür definiert XML-Schema Part1 das Element simpleType. Für einfache Typen ist jedoch nur die einschränkende Vererbung (restriction) zugelassen. Dies liegt in der praktischen Beherrschbarkeit des Typsystems begründet. Durch die strikte Restriktionssemantik ergibt sich die Möglichkeit kontravarianter Substitution, wie sie bei objektorientierten Typsystemen und Vererbungsstrukturen anzutreffen ist. Dies bedeutet, daß an jeder Stelle, an der eine Ausprägung eines Supertyps erwartet wird, auch -- unter Erhalt der Typrestriktion -- eine Ausprägung eines Subtypen auftreten darf. Beispielhaft: Wird an einer Stelle des Instanzdokumentes durch das Schema das Auftreten einer Ausprägung von integer verlangt, so kann der Anwender auch Ausprägungen der Subtypen int, short oder byte angeben ohne die Gültigkeit des XML-Dokuments zu beeinträchtigen.
Vereinigungstypen werden aus einer nichtleeren Menge von Ausgangstypen gebildet.
Das Beispiel zeigt die Definition eines Typen termin, der den vorgegebenen Primitivtypen date und eine Liste NamenDerWochentage (deren Definition nicht dargestellt ist) vereinigt. Insbesondere zeigt der Ausschnitt die Möglichkeit der Vereinigungsbildung auch über aggregierte Typen.
(1)<xs:simpleType name="termin">
(2) <xs:union memberTypes="xs:date NamenDerWochentage"/>
(3)</xs:simpleType>
Das XSD-Beispiel zeigt, als Fragment der XML-Schemaspezifikation, die Definition des vorgegebenen Typs short, einer einschränkenden Spezialisierung des Typs int.
Am Beispiel gut nachvollziehbar sind die beiden Schritte zur Bildung eines eigenen Typen:
Im Beispiel wird der kleinste und größte gültige Wert (minInclusive bzw. maxInclusive) des neuen Typen short gegenüber dem Basistypen beschränkt.
| Beispiel 28: Einschränkende Spezialisierung eines simplen Typen |
|
![]()
Die Bildung aggregierter Typen folgt demselben Muster. Jedoch tritt an die Stelle der Ableitung die Spezifikation des Aggregationstyps (im Beispiel Liste) und Angabe des Inhaltstyps (im Beispiel string).
| Beispiel 29: Bildung eines Aggregationstypen |
|
![]()
Nachfolgend sind die verschiedenen Beschränkungsmöglichkeiten zusammengefaßt:
length(1)<xs:simpleType name="Postleitzahl">
(2) <xs:restriction base="xs:string">
(3) <xs:length value="5"/>
(4) </xs:restriction>
(5)</xs:simpleType>
(1)<xs:simpleType name="VornamenList">
(2) <xs:list itemType="xs:token"/>
(3)</xs:simpleType>
(4)<xs:simpleType name="VornamenRestrictedList">
(5) <xs:restriction base="VornamenList">
(6) <xs:length value="5"/>
(7) </xs:restriction>
(8)</xs:simpleType>
minLengthVornamenRestrictedList muß mindestens einen Eintrag enthalten):
(1)<xs:simpleType name="VornamenList">
(2) <xs:list itemType="xs:token"/>
(3)</xs:simpleType>
(4)<xs:simpleType name="VornamenRestrictedList">
(5) <xs:restriction base="VornamenList">
(6) <xs:minLength value="1"/>
(7) </xs:restriction>
(8)</xs:simpleType>
Titel muß aus mindestens fünf Zeichen bestehen):
(1)<xs:simpleType name="Titel">
(2) <xs:restriction base="xs:string">
(3) <xs:minLength value="5"/>
(4) </xs:restriction>
(5)</xs:simpleType>
maxLengthVornamenRestrictedList muß mindestens einen, jedoch höchstens drei, Einträge enthalten):
(1)<xs:simpleType name="VornamenList">
(2) <xs:list itemType="xs:token"/>
(3)</xs:simpleType>
(4)<xs:simpleType name="VornamenRestrictedList">
(5) <xs:restriction base="VornamenList">
(6) <xs:minLength value="1"/>
(7) <xs:maxLength value="3"/>
(8) </xs:restriction>
(9)</xs:simpleType>
Titel muß aus mindestens fünf, darf jedoch aus höchstens 80 Zeichen bestehen):
(1)<xs:simpleType name="Titel">
(2) <xs:restriction base="xs:string">
(3) <xs:minLength value="5"/>
(4) <xs:maxLength value="80"/>
(5) </xs:restriction>
(6)</xs:simpleType>
patternS eine Zeichenkette aus einer beliebigen Anzahl von Zeichen (d.h. sie kann auch leer sein!), dann gilt: | Tabelle 8: Übersicht der Quantifier | |||||||||||||||
|
![]()
| Tabelle 9: Übersicht der Escape-Symbole | |||||||||||||||||||||||||||||||||||
|
![]()
| Tabelle 10: Buchstaben | |||||||||||||
|
![]()
| Tabelle 11: Markierungssymbole | |||||||||
|
![]()
| Tabelle 12: Zahlen | |||||||||
|
![]()
| Tabelle 13: Interpunktionszeichen | |||||||||||||||||
|
![]()
| Tabelle 14: Separatoren | |||||||||
|
![]()
| Tabelle 15: Symbole | |||||||||||
|
![]()
| Tabelle 16: Sonstige Zeichen | |||||||||||
|
![]()
pattern-Elements direkt angegeben werden. Die Zeichenkettenfamilien werden durch ihre symbolische Darstellung, eingeleitet durch \p und durch geschweifte Klammern umschlossen, dargestellt.\P das Komplement zu jeder der aufgeführten Zeichenkettenfamilien definiert.^ angeboten, welches eine Aufzählung von Zeichen von der Verwendung ausschließt. Darüberhinaus können auf der Basis simpler Mengendifferenzoperationen eigene Zeichenklassen komfortabel definiert werden. | Tabelle 17: Zeichensequenzen | |||||||||||||||||||||||
|
![]()
(1)<xs:simpleType name="gerAutoNummer">
(2) <xs:restriction base="xs:string">
(3) <xs:pattern value="\p{Lu}{1,3}-\p{Lu}{1,2} \p{Nd}{1,4}"/>
(4) </xs:restriction>
(5)</xs:simpleType>
enumeration(1)<xs:simpleType name="ampelfarben">
(2) <xs:restriction base="xs:string">
(3) <xs:enumeration value="rot"/>
(4) <xs:enumeration value="gelb"/>
(5) <xs:enumeration value="grün"/>
(6) </xs:restriction>
(7)</xs:simpleType>
whitespacemaxInclusivevalue-Attribut angegebenen zugelassen. (1)<xs:simpleType name="uHu">
(2) <xs:restriction base="xs:decimal">
(3) <xs:maxInclusive value="100"/>
(4) </xs:restriction>
(5)</xs:simpleType>
maxInclusive-Festlegung ohne Informationsverlust in eine äquivalente maxExclusive-Definition überführt werden. maxExclusive(1)<xs:simpleType name="uHu">
(2) <xs:restriction base="xs:decimal">
(3) <xs:maxExclusive value="100"/>
(4) </xs:restriction>
(5)</xs:simpleType>
uHu sind alle Zahlen kleiner als 100 zugelassen. Durch die Verwendung des XSD-Typen decimal als Basistyp kann auch keine verlustfreie Überführung in eine maxInclusive-Festlegung überführt werden, da hierfür die größte zugelassene Zahl fixiert werden müßte, was jedoch die Typdefinition von decimal explizit offen läßt. minInclusive(1)<xs:simpleType name="uFz">
(2) <xs:restriction base="xs:decimal">
(3) <xs:minInclusive value="25"/>
(4) </xs:restriction>
(5)</xs:simpleType>
minExclusive(1)<xs:simpleType name="uFz">
(2) <xs:restriction base="xs:decimal">
(3) <xs:minExclusive value="25"/>
(4) </xs:restriction>
(5)</xs:simpleType>
totalDigits(1)<xs:simpleType name="myNumber">
(2) <xs:restriction base="xs:decimal">
(3) <xs:totalDigits value="7"/>
(4) </xs:restriction>
(5)</xs:simpleType>
fractionDigits(1)<xs:simpleType name="myNumber">
(2) <xs:restriction base="decimal">
(3) <xs:totalDigits value="9"/>
(4) <xs:fractionDigits value="2"/>
(5) </xs:restriction>
(6)</xs:simpleType>
![]()
Definition von Attributen:
Die Attributdeklaration erfolgt durch das XSD-Element attribute. Die Mächtigkeit entspricht auch hier, wie bereits für die Elemente verwirklicht, einer Obermenge der DTD. So können neben optionalen, zwingenden und konstanten Attributen auch Aufzählungsattribute und Mengen realisiert werden. Hierbei wurde auf die Orthogonalität zum durch simpleType geschaffenen Typmechanismus geachtet.
Die Charakteristika (ausgedrückt in Attributen des XSD-Elements attribute) einer Attributdeklaration umfassen:
NCName) gemäß Namensraumproduktion 7.simpleType.qualified, andernfalls unqualified).optional, required oder prohibited.optional angenommen und das Attribut damit nicht zwingend im XML-Dokument erwartet. Den Gegensatz hierzu bildet required, wodurch das Attribut als zwingend anzugeben definiert wird. prohibited verbietet die Nutzung des Attributes im XML-Dokument.Anmerkung: Einen Anwendungsfall der Belegung prohibited für use bilden Attribute, die innerhalb des Schemas bereits definiert sind, jedoch noch nicht zur allgemeinen Nutzung freigegeben wurden.
| Beispiel 30: Einige Attributdefinitionen |
Download des Beispiels |
![]()
Das Beispiel zeigt einige Varianten der Attributdeklaration. So definieren myAtt1 mit myAtt4 globale Attribute, die innerhalb verschiedener Elemente verwendet werden können. Hierdurch wird die bereits für Elemente verwirklichte Mimik der einmaligen Deklaration und anschließenden beliebigen Verwendung auch auf Attribute ausgedehnt. Die Nutzung der so deklarierten Attribute geschieht durch das ref-Attribut innerhalb des Attribute-Elements des beherbergenden Elements.myAtt1 definiert ein typenloses Attribut, dem vorgabegemäß der allgemeinste Typ anyType zugeordnet wird. Die Angabe dieses Attributes ist optional (use="optional"), was der Vorgabe entspricht.
Der XSD-Standardtyp decimal findet zur Definition des Attributs myAtt2 Verwendung. Die zwingend anzugebenden (use="required") Inhalte dieses Attributs werden durch einen XML-Schema-Parser auf Typkonformität geprüft.myAtt3 veranschaulicht die Bildung eines anonymen (inneren) atomaren Typen zur Definition eines Attributs. Der durch Restriktion gebildete neue Datentyp steht ausschließlich innerhalb des Attributs myAtt3 zur Verfügung. Die Syntax der Datentypspezialisierung entspricht der im vorhergehenden Abschnitt diskutierten. Zudem ist die Verwendung des Attributes innerhalb eines XML-Dokumentes untersagt; ausgedrückt durch die Belegung use="prohibited"
Analog der Typisierung eines Elementinhaltes durch einen anwenderdefinierten Typen gestaltet sich das Vorgehen für Attribute. Veranschaulicht wird dies durch die Definition von myAtt4. Sie greift auf den eigen-definierten Typen myType1 zurück.
Dem Attribut myAtt5 ist zusätzlich zur Benennung, die innerhalb des verwendenden Elementes eindeutig sein sollte, ein Dokument-weiter Schlüssel (id) zugeordnet.
Innerhalb des Elements foo werden die fünf zuvor definierten Attribute verwendet. Trotz der Reihenfolge der Definitionen im complexType-Element verfügen die Attribute im XML-Instanzdokument -- auch bei der Verwendung von XML-Schema -- über keinerlei Reihenfolge (vgl. XML-Spezifikation).
Zusätzlich enthält die Elementdefintion für foo mit myAtt6 ein „lokales“ Attribut. Diese Definitionsvariante entspricht am ehesten der der Document Type Definition, da sie eine Wiederverwendung außerhalb des definierenden Elements ausschließt.
| Beispiel 31: Vollständiges XML-Schema der Projektverwaltung |
Download des Beispiels |
![]()
Abschließend eine gültige (sowohl valid als auch schema valid) Dokumentinstanz der Projektverwaltungsstruktur.
| Beispiel 32: Gültiges Projektverwaltungsdokument |
Download des Beispiels |
![]()
Werkzeuge:
Zwar existiert -- wie für alle XML-Dokumente -- die Möglichkeit, Dokument Typ Definitionen und XML-Schemata „per Hand“ mit einem Texteditor zu erstellen, jedoch ist dieses Vorgehen, insbesondere für umfangreiche XML-Vokabulare, zeitaufwendig und fehlerträchtig. Zusätzlich läßt die rein textuelle Formulierung die entstehenden Schemadokumente schnell unübersichtlich werden.
Inzwischen existieren einige gute DTD- und Schemaeditoren, die zumeist neben visueller Syntaxhervorhebung auch die kontextsensitive Editierung erlauben und so eine wesentliche Erleichterung der Schemaerzeugung bilden. Gleichzeitig bieten die meisten verfügbaren Werkzeuge dieser Klasse auch Möglichkeiten zur Validierung des erzeugten Schemas an.
Ergänzend wird vielfach auch eine graphische Repräsentation der DTD- oder XSD-Struktur angeboten.
Die Abbildungen zeigen Ansichten der Werkzeuge XML Authority bzw. XML Spy
 |  |  |
| Web-Referenzen 7: Weiterführende Links und Werkzeuge |
XML Schema Part 0: Primer XML Schema Part 1: Structures XML Schema Part 2: Datatypes XML Schema @ Cover-Pages Parsing the Atom -- Diskussion über die Vor- und Nachteile inhärent komplexer atomarer Typen Schema-Informationen @ jeckle.de XML-Authority (DTD- und XSD-Editor) XML Spy (DTD- und XSD-Editor) |
![]()
Zur Extraktion beliebiger Teile eines wohl-geformten
XML-Dokuments verabschiedete das W3C 1999 die Sprache
XPath. Sie bildet eine pfadorientierte
Lokatorsprache, die das Auffinden von Dokumentteilen
(einzelnen Elementen, Attributen, etc.) durch Pfadausdrücke, die
sich an der Struktur des XML-Dokuments orientieren,
gestattet.
Die Grenze zwischen Lokatorsprache und
„echter“ Anfragesprache wie SQL sind fließend.
Zwei Unterscheidungsmerkmale sollen jedoch hervorgehoben werden:
XPath wird im üblichen Anwendungsfall nicht interaktiv oder in
eine Programmiersprache als Wirtssprache eingebettet verwendet,
sondern wurde (zunächst) nur für die Nutzung in Kombination mit
der Transformationssprache XSLT und den erweiterten
Verweisen der Sprache XPointer konzipiert. Zum zweiten
fehlt XPath die üblicherweise mit dem reinen Anfrageteil verwobene
Manipulationssprache zur Änderung bereits bestehender Daten; XPath
ist allein für den lesenden Zugriff auf XML-Dokumente
ausgelegt.
Hinweis: XPath unterscheidet XML-üblich zwischen Groß- und Kleinschreibung. Daher sind Element- und Attributnamen unbedingt in der im Dokument gewählten Schreibweise anzugeben.
Lokalisierungspfade:
Lokalisierungspfade dienen der abstrakten Beschreibung einer Menge von Informationsknoten innerhalb eines Dokuments.
Die einfachste Form eines Lokalisierungspfades beschreibt der Wurzellokalisierungpfad (root location path), ausgedrückt durch „/“. Er liefert für jedes XML-Dokument den Wurzelknoten. Dieser ist nicht identisch mit dem Wurzelelement eines XML-Dokuments! Der (unbenannte) Wurzelknoten entspricht dem Document Information Item des Information Sets, während das erste benannte Element des Dokuments durch ein Element Information Item dargestellt wird.
Die Navigation zu den einzelnen Elementknoten, oder Knotenmengen, wird durch einen Pfadausdruck realisiert. Die explizite Variante erlaubt die Angabe aller zu traversierenden Knoten bis hin zu den zu extrahierenden. Hierzu werden die Knoten, von der Wurzel absteigend durch „/“-Symbole separiert, notiert. Wegen der Korrespondenz der voneinander abgetrennten Knotennamen und den Baumstufen, werden diese auch als Lokalisierungsschritte bezeichnet. Als weitere sprachliche Analoge spiegelt der XPath-Ausdruck, von links nach rechts gelesen, auch die Schritte -- ausgehend vom Wurzelelement des Dokuments -- zur Lokalisierung der gesuchten Knotenmenge wieder.
Das Beispiel zeigt eine solche Definition am Beispiel der Projektverwaltung.
Anmerkung: Das Resultat ist in XML-Notation dargestellt, obwohl genaugenommen eine Knotenmenge des Information Sets als Resultat zurückgeliefert wird. Die gewählte XML-Darstellung ist hierbei nur eine der möglichen Varianten zur Ergebnispräsentation.
| Beispiel 33: XPath-Ausdruck zur Lokalisierung aller Vornamen |
|
![]()
Die Einzelknoten werden entsprechend ihrer Auftrittsreihenfolge im Quelldokument (sog. document order) zurückgegeben.
Die expliziten Pfadausdrücke lassen sich in beliebiger Länge fortsetzen, jedoch zeigen sie fundamentale Schwächen in Puncto Flexibilität. Wie im Beispiel der XHTML-Verwendung innerhalb eines eigenen XML-Dokuments gesehen, kann Information desselben Typs (d.h. umschlossen durch denselben Tag) verschiedene Elternknoten besitzen. So im Beispiel, dort ist die Qualifikation auf derselben Baumstufe sowohl unterhalb des Elternelements em als auch u anzutreffen.
Als Lösung erlaubt XPath die Nutzung von Platzhaltern statt der expliziten Elementnamen innerhalb eines Lokalisierungsschrittes. In der Folge entstehen freie Lokalisierungsschritte, die alle Kindknoten einer im direkt vorhergehenden Lokalisierungsschritt selektierten Knotenmenge adressieren.
Der nachfolgende XPath-Ausdruck zeigt dies am Beispiel des Qualifikationsprofils.
| Beispiel 34: Platzhalter in Lokalisierungsschritten |
|
![]()
Der Pfadausdruck liefert die beiden Kindelemente Qualifikation -- unabhängig von der Benennung des Elternknotens -- die direkt unterhalb des Knotens Qualifikationsprofil angeordnet sind.
Allerdings enthält die Ausgabe nicht alle Knoten des Typs Qualifikation. Der gegebene Pfadausdruck gestattet lediglich das Überspringen einer Hierarchieebene. Daher wird der hierarchisch tieferstehende Qualifikations-Knoten mit Inhalt Entwickler nicht lokalisiert. Die (zunächst naheliegende) Lösung den Pfadausdruck zu /ProjektVerwaltung/Person/Qualifikationsprofil/*/*/Qualifikation zu erweitern liefert nicht das gewünschte Resultat aller Qualifikations-Knoten, sondern ausschließlich den zuvor nicht lokalisierbaren, da der modifizierte Ausdruck nun zwingend zwei freie Lokalisierungsschritte vorsieht.
Zur Variierung der Tiefe der freien Schritte sieht XPath die Schreibweise „//“ vor. Sie erlaubt die Lokalisierung der Kindknoten auf einer beliebigen Hierarchiestufe.
| Definition 11: Lokalisierungsschritt |
Ein Lokalisierungsschritt setzt sich aus dem Namen der Achse gefolgt von zwei Doppelpunkten und einem Knotentest, optional ergänzt um ein auszuwertendes Prädikat, zusammen. Wird keine Achse spezifiziert, so gilt vorgabegemäß die Achse child.Ein Knotentest ist syntaktisch ein QName, der genau dann erfüllt ist, wenn der Knotenname mit dem Namen des Knotentests übereinstimmt.Das Prädikat filtert die Ergebnismenge hinsichtlich verschiedener Charakteristika wie Existenz von Kindknoten oder Attributen, Position in der Ergebnismenge, etc. |
![]()
Das Beispiel zeigt die korrekte XPath-Formulierung zur Lokation aller Qualifikations-Knoten:
| Beispiel 35: Hierarchieunabhänigige Knoten-Lokalisierung |
|
![]()
Durch die abkürzende Schreibweise „//“ entsteht ein Muster zur Selektion aller nachfolgenden Knoten. In Verallgemeinerung dieses Konzepts bietet XPath sog. Achsen an, um relativ zum aktuellen Knoten beliebige Teilbäume zu lokalisieren.
Die Abbildung zeigt die verschiedenen durch Achsen zugänglichen Knotenmengen relativ zum rot hervorgehobenen aktuellen Knoten.
Download der XML-Datei mit dem Beispiel der Graphik
| Tabelle 18: XPath-Achsen und ihre Bedeutung | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
![]()
Anmerkung:
Die Achsen ancestor, descendant, following, preceding und self partitionieren ein Dokument (unter Auslassung der Attribut- und Namensraumknoten): sie überschneiden sich nicht und enthalten alle Elementknoten des Dokuments.

Filterung durch Prädikate:
Ein -- durch eckige Klammern abgegrenztes -- Prädikat kann innerhalb jedes Lokalisierungsschrittes eines XPath-Ausdrucks angegeben werden. Fehlt es, wird die bisher ermittelte Knotenmenge nicht modifiziert.
Das Prädikat kann selbst ein gültiger XPath-Ausdruck sein.
Das prinzipielle Vorgehen kann folgendermaßen beschrieben werden:
Beginnend von links nach rechts für jeden Lokalisierungsschritt: (1) Ermittlung der zur Anfrage passenden Knotenmenge
(2) Reduzierung der Ergebnismenge um diejenigen Knoten, für die das Prädikat false liefert.
Befinden sich rechts vom aktuell bearbeiteten Lokalisierungsschritt weitere Ausdrücke, so wird die Resultatmenge als Eingabe eines weiteren Schritts (1) übergeben.
| Beispiel 36: Selektion unter Anwendung eines Prädikats |
|
![]()
Der Ausdruck selektiert an beliebiger Stelle des Dokuments („//“) alle Knoten des Typs Person. Die Knotenmenge wird um diejenigen Personen vermindert, zu denen kein Qualifikationsprofil angelegt ist. D.h. Es werden nur diejenigen Knoten selektiert, die über einen Kindknoten des Typs Qualifikationsprofil verfügen. Von dieser Knotenmenge (des Typs Person!) werden anschließend im zweiten Lokalisierungsschritt die Kindknoten des Typs Nachname selektiert.
Mithin liefert der XPath-Ausdruck alle Nachnamen von Personen, zu denen ein Qualifikationsprofil abgelegt ist.
Anmerkung: Das Beispiel nutzt im Prädikat die abkürzende Schreibweise zur Angabe der Vorgabeachse child. Die ausführliche Schreibweise -- mit unveränderter Semantik -- des XPath-Ausdruckes lautet daher: //Person[child::Qualifikationsprofil]/Nachname
Durch die zusätzliche Definition eines Prädikats für den zweiten Lokalisierungsschritt kann eine weitere Filterung der Ergebnismenge realisiert werden. Zusätzlich können innerhalb eines Prädikats neben XPath-Ausdrücken auch einige vordefinierte Funktionen verwendet werden.
Das Beispiel zeigt die Selektion der Vornamen als Kind eines Personen-Knotens (Test der Elternschaft durch erstes Prädikat), wenn dieser mit „O“ beginnt (Test durch starts-with-Funktion innerhalb des zweiten Prädikats). Die Struktur der Eingabedatei zwingt zusätzlich zur Anwendung der following-Achse, da Knoten des Typs Nachname in der Dokumentreihenfolge nach Knoten des Types Vornamen auftreten.
| Beispiel 37: Schrittweise Berechnung einer Selektion unter Verwendung mehrerer Prädikate |
XPath-Ausdruck: Ausgewerteter XPath: Ausgewerteter XPath: Ausgewerteter XPath: Ausgewerteter XPath: Ausgewerteter XPath: |
![]()
Die durch die XPath-Spezifikation vordefinierten Funktionen lauten in der Übersicht:
| Tabelle 19: XPath-Funktionen für Knotenmengen (node-sets) | |||||||||||||||
|
![]()
| Tabelle 20: XPath-Funktionen für Zeichenketten | |||||||||||||||||||||
|
![]()
| Tabelle 21: Boole'sche XPath-Funktionen | |||||||||||
|
![]()
| Tabelle 22: Zahlenorientierte XPath-Funktionen | |||||||||||
|
![]()
Für mathematische Berechnungen auf zahlenartigen Knoten stehen folgende Operatoren zur Verfügung.
| Tabelle 23: Mathematische Operatoren | |||||||||||
|
![]()
Ein umfangreiches Beispiel: Für das nachfolgende Beispiel wird das Projektverwaltungsdokument erweitert zu:
| Beispiel 38: Erweiterte Projektverwaltung |
Download des Beispiels |
![]()

Der XPath-Ausdruck der Abbildung 20 lokalisiert den Attributknoten des Inhalts Prj02.
| Übung 2: Einige Übungen |
Welches Ergebnis liefern folgende XPath-Ausdrücke? (a) //Person[//child::Qualifikationsprofil]/Nachname(b) //Person[parent::ProjektVerwaltung]/Vorname[following-sibling::Vorname](c) /ProjektVerwaltung/Person[attribute::PersID='Pers01']//NachnameWie muß ein XPath-Ausdruck lauten, um folgendes zu selektieren? (d) Selektion aller Personen mit Nachnamen „Obermüller“. (e) Selektion aller Nachnamen von Personen die über mehr als eine Qualifikation verfügen. (f) Selektion der Nachnamen aller Projektleiter. |
![]()
Über die Möglichkeiten der Datentypen hinausgehend bietet XML-Schema das Element unique zur Definition eindeutiger Wertbelegungen an. Hierbei wird auf die Lokatorsprache XPath zurückgegriffen um die abzuprüfenden Knoten innerhalb des Dokuments zu bezeichnen.
Die Syntax verwendet XPath-Ausdrücke eingeschränkter Mächtigkeit sowohl zur Festlegung des der Knotenmenge, auf die sich die Einschränkung bezieht (selector), als auch zur Angabe der eingeschränkten Knoten (field) selbst.
(1)<xsd:unique name="aName">
(2) <xsd:selector xpath="aValidXPath"/>
(3) <xsd:field xpath="aFieldStatement"/>
(4) ...
(5)</xsd:unique>
Die Mächtigkeit der XPath-Ausdrücke ist dahingehend eingeschränkt, daß für das selector-Element ausschließlich Ausdrücke erlaubt sind, die Kindelemente des Knotens liefern, in dessen Kontext die durch unique formulierte Einschränkung angegeben wird. Als Konsequenz ist die Nutzung der verfügbaren XPath-Achsen auf diejenigen beschränkt, die Element-Knotenmengen zurückliefern.
Die Lokationsausdrücke in den -- möglicherweise mehrfach auftretenden -- field-Elementen werden relativ zum Pfad des selector-Knotens interpretiert. Hintereinandergesetzt muß der Pfad eines selector-Elements, gefolgt von einem Pfad eines field-Elements, einen gültigen Lokationsausdruck ergeben, der genau einen Knoten oder genau ein Attribut in der Ergebnismenge liefert. Sind mehrere field-Elemente zu einem selector-Element gegeben, so werden diese als durch logisches und verknüpft interpretiert. Mithin entspricht diese Semantik einem concatenated primary key aus den relationalen Datenbanken.
Das Beispiel zeigt die Nutzung des unique-Konstrukts zur Angabe der Eindeutigkeitsbedingung für das Attribut PersID des Elements Person.
Zunächst selektiert der Pfad /Person alle Knoten des gleichnamigen Typs; durch das field-Element wird die Eindeutigkeitsbedingung auf alle Attribut-Kindnoten des Typs PersID der Knoten in der selektierten Knotenmenge angewendet.
Die Semantik ist damit zur bisherigen ID-Typisierung identisch.
| Beispiel 39: Unique-Einschränkung |
Download des Beispiels |
![]()
Das nächste Beispiel zeigt die Verwendung mehrerer field-Elemente zur Realisierung zusammengesetzter Schlüssel.
Hierzu wird die Kombination aus dem Inhalt des Nachnamen- und des Vornamen-Elements zusammen als eindeutig deklariert.
Überdies zeigt das Beispiel die Anwendung des Schlüsselmechanismus auf Elemente ohne Änderung der Basissyntax, abgesehen von der geänderten XPath-Achse.
| Beispiel 40: Zusammengesetzter Schlüssel innerhalb eines unique-Elements |
Download des Beispiels |
![]()
Zur Realisierung von wertdefinierenden Schlüsselbeziehungen bietet XML-Schema die Elemente key und keyref an. Sie werden verwendet um sicherzustellen, daß ein Element oder Attribut nur einen Wert annehmen darf, der bereits an anderer Stelle im Instanzdokument auftritt.
Hierzu lokalisiert key auf der Basis eines XPath-Ausdruckes eine Referenzmenge, während keyref diejenige Knotenmenge lokalisiert, in der ausschließlich Elemente der Referenzmenge enthalten sein dürfen.
Das Beispiel zeigt die Anwendung auf das Element ProjektVerwaltung. Der mit projectKey benannte Schlüssel definiert die Referenzmenge als das Ergebnis der Anfrage Projekt/@ID, worauf die projectReference Bezug nimmt.
| Beispiel 41: Schlüsselbasierte Referenzierung |
Download des Beispiels |
![]()
| Web-Referenzen 8: Weiterführende Links |
XPath Spezifikation Deutsche Übersetzung der XPath-Spezifikation XPath Visualisierer (Java-basiert) Visual XPath (.NET Windows-Applikation) Originalbezugsquelle XPath Explorer (Java-basiert) Originalbezugsquelle Online Experimentieren mit XPath |
![]()
3
DatenbankzugriffHäufig besteht der Wunsch oder die Notwendigkeit, auf
bereits vorliegende Datenbestände, die durch ein
Datenbankmanagementsystem (DBMS) verwaltet werden, in einer Applikationsprogrammiersprache
zuzugreifen. Dabei soll die Anbindung der benötigten Datenquelle
nicht problemspezifisch wieder und wieder neu entwickelt
werden, sondern sollte sich auf ähnliche
Datenanbindungsprobleme übertragen lassen.
Vor diesem Hintergrund liegt es nahe, sich an den Typen der
verfügbaren und kommerziell bedeutsamen
DBMS zu orientieren und
herstellerspezifische Entwicklungen außer Acht zu lassen.
Gleichzeitig offenbaren sich hierbei
Standardisierungsbemühungen wie die Sprache SQL zum Zugriff
auf relationale DBMS als lohnenswerter Ansatz der
Etablierung einer generischen und übertragbaren
Schnittstelle.
Die Idee zur Schaffung einer solchen generischen Schnittstelle für den Zugriff auf relationale DBMS geht zurück auf eine Initiative der SQL Access Group, welche später in der Vereinigung mit der X/Open Group aufging, die zwischenzeitlich in Open Group umbenannt wurde. Das dort konzipierte programmiersprachenunabhängige SQL Call Level Interface (SQL/CLI) konnte sich dank der Umsetzung unter dem Namen Open Database Connectivity (ODBC) durch die Firma Microsoft und die parallel erfolgte internationale Normierung unter dem Titel SQL/CLI breit am Markt etablieren.
Die für die Programmiersprache Java adaptierte Variante des Zugriffs auf relationale DBMS wird durch SUN Microsystems unter dem Namen Java Database Connectivity (JDBC) propagiert und stellt eine auf ODBC konzeptionell aufbauende und auf die spezifischen Bedürfnisse dieser Applikationsprogrammiersprache optimierte Untermenge des SQL/CLI-Standards dar.
Von den Vorgängeransätzen übernommene Grundidee der Schnittstelle ist es den physischen Zugriff auf das Datenbankmanagementsystem durch eine von der Applikation spearierte wiederverwendbare Softwarekomponente, den sog. JDBC-Treiber, abzuwickeln.
Dieser Treiber vermittelt zwischen der Javaapplikation und dem verwendeten DBMS. Hierbei muß für jedes DBMS ein auf es abgestimmter JDBC-Treiber verwendet werden, da lediglich die Schnittstelle zur Applikation, nicht jedoch die zum DBMS, standardisiert ist.
Diesem Treiber obliegt die Abwicklung der gesamten
Kommunikationsvorgänge mit dem DBMS. Er setzt jedoch
selbst keine datenbankspezifischen Funktionalitäten, wie
Syntax- oder Plausibilitätsprüfungen der übermittelten
Kommandos um. Etwaige Fehlerprüfungen können, ebenso wie Anfrageoptimierungen,
daher erst seitens des DBMS vorgenommen werden.
Der Vorteil dieses Vorgehens liegt in der Generizität des
JDBC-Treibers. Er kann ohne aufwendige Logikanteile als
reine uninterpretierende Vermittlungsschicht zwischen Applikation
und DBMS umgesetzt werden, wodurch schlanke Implementierungen ermöglicht werden.
Die JDBC-Spezifikation detailliert den Treiberbegriff zusätzlich hinsichtlich der gewählten technischen Umsetzung aus. So werden die vier in Abbildung 3 dargestellten Treibertypen gemäß ihrer Charakteristika beschrieben und unterschieden.

Die historisch älteste Variante bildet der Typ 1
Treiber. Strenggenommen verkörpert er selbst keinen
Datenbanktreiber, sondern lediglich eine Umsetzungsschicht
die einem existierenden ODBC-Treiber vorgeschaltet
wird.
Die Abbildung belegt diesen Treibertyp daher mit dem
Begriff JDBC-ODBC-Bridge, da er lediglich den
Brückenschlag zwischen den beiden Standards vornimmt und
sich in der konkreten Anwendung auf die Umsetzung
zwischen den beiden Protokollen beschränkt, ohne realen
Zugriff auf die Datenbank zu erhalten.
Dieser ist dem ODBC-Treiber vorbehalten, der im allgemeinen Falle mit einer weiteren Umsetzungsstufe
kommuniziert, welche die generischen ODBC-Aufrufe in konkrete DBMS-spezifische wandelt.
Während sowohl der JDBC-ODBC-Brückentreiber als auch der
ODBC-Treiber selbst für verschiedene DBMS verwendet werden
können, muß für jedes konkrete DBMS eine
herstellerspezifische, d.h. an das verwendete DBMS
angepaßte, Bibliothek vorliegen.
Für den Fall eines Typ 2 Treibers entfällt
diese durch ODBC geschaffene zusätzliche Indirektionsstufe
zugunsten der Adaption der Konversionskomponente, welcher
die Wandlung der Aufrufe in das DBMS-native Protokoll
obliegt, an das JDBC-Protokoll und ihrer Integration in den JDBC-Treiber
selbst.
Die Natur der Kommunikation des Java-Anteils des Treibers mit den
Nativen ist im Rahmen der durch die JDBC-Spezifikation
gegebenen Definition nicht festgelegt.
Durch die integration der DBMS-nativen Treiberanteile in den JDBC-Treiber muß dieser
für jedes anzusprechende DBMS neu erstellt werden. Eine Wiederverwendung der JDBC-spezifischen
Anteile, die für die Clientkommunikation eingesetzt werden, kann hierbei nicht erfolgen.
Der Fall der (partiellen) Konkretisierung dieser
Kommunikationsbeziehung zu einem beliebigen DBMS-neutralen
Protokoll wird durch einen Typ 3 Treiber
aufgegriffen.
Hier wird die DBMS-spezifische Komponente (in der
Abbildung grau dargestellt) als vom JDBC-Treiber
separiertes Modul aufgefaßt, daß mit diesem mittels eines
festgelegten neutralen Protokolls kommuniziert.
Durch diese Separierung, die auch durch Installation auf physisch getrennten
Maschinen --- der DBMS-spezifische Anteil könnte beispielsweise auf einem Middleware-Server untergebracht werden --- fundiert werden kann, gelingt die Wiederverwendung des JDBC-Treiberanteils, der
mit verschiedenen DBMS-spezifischen Bibliotheken über das gewählte Protokoll kommunizieren kann.
Der Typ 4 Treiber stellt die letzte durch
die JDBC-Spezifikation vorgesehene Ausprägung dar. Er
konzipiert eine vollständig in Java implementierte
Zugriffsschicht, die in sich geschlossen ist. Sie besitzt
daher lediglich die notwendige JDBC-Schnittstelle zur
Kommunikation mit der Java-Applikation und eine
DBMS-Spezifische zum Zugriff auf die Datenquelle.
Die Vorteile dieser Architekturvariante liegen in ihrer
Portabilität und den geringen Installations und
Wartungsaufwänden, die aus der Reduktion der
Kommunikationsbeziehungen resultieren. So kann ein solcher
Treiber durch einfache Integration in die Java-Applikation
verwendet werden und bedarf keiner Installationen oder
Modifikationen an der verwendeten Ausführungsumgebung.
Gleichzeitig offenbart sich diese Lösung jedoch als
technisch aufwendig in der Umsetzung, sobald
DBMS verschiedener Hersteller angesprochen werden sollen,
da die JDBC-Anteile des Treibers nicht separat
wiederverwendet werden können.
Hinsichtlich des Laufzeitverhaltens zeigt sich deutlich
die Schwäche der Typ 1 Treiber, welche in der
inhärent notwendigen Doppelkonversion (JDBC zu ODBC und
ODBC zu nativem Aufruf) begründet liegt. Daher sind
Treiber dieses Typs als Übergangserscheinung hin zu
„echten“ JDBC-Treibern, d.h. Treibern der
restlichen Typen, anzusehen und sollten in
Produktivumgebungen nicht eingesetzt werden.
Die Vorteile der Typ 2 und 3 Treiber seitens der
Ausführungsgeschwindigkeit liegen in den nativen
Codeanteilen begründet, welche für das jeweilige verwendete
DBMS optimiert werden können.
Zwar spricht der leichte Installations- und
Adminstrationsaufwand eindeutig für Typ 4
Treiber, jedoch fallen diese in ihrer
Leistungsfähigkeit durch die ausschließliche Verwendung
der Programmiersprache Java teilweise deutlich hinter
Treiber des Typs 2 und 3, mit unter sogar hinter solche des Typs 1,
zurück. Sie verkörpern jedoch den aus konzeptioneller
Sicht zu bevorzugenden Ansatz hinsichtlich Portabilität
und Vergleichbarkeit der erzielten quantitativen Ergebnisse.
Typischerweise kommen im
produktiven Einsatz jedoch Treiber der Typen 2 und 4 zum Einsatz,
die entweder durch den Hersteller des DBMS mitgeliefert werden (Typ 2) oder
auf der Basis publizierter Schnittstellen plattformunabhängig
für genau ein spezifisches DBMS entwickelt wurden (Typ 4).
Generell formuliert das JDBC-Konzept auf dieser Ebene noch keine Einschränkung hinsichtlich der unterstützten DBMS-Typen und ist generell auf verschiedenste Datenquellen anwendbar. Durch die Struktur des API und die verfügbaren Treiber kristallisieren sich jedoch relationale DBMS als Hauptanwendungsgebiet dieser Zugriffsschnittstelle heraus.
Im folgenden wird die Verwendung des Typ 4 Treibers Connector/J im Zusammenspiel mit dem RDBMS MySQL betrachtet.
Die Beispiele basieren auf einer Demodatenbank, deren Struktur und Inhalte nachfolgend angegeben sind.
+----------+-------+---------+-----------+------------+--------------------------+------+----------+-----------+------+
| FNAME | MINIT | LNAME | SSN | BDATE | ADDRESS | SEX | SALARY | SUPERSSN | DNO |
+----------+-------+---------+-----------+------------+--------------------------+------+----------+-----------+------+
| John | B | Smith | 123456789 | 1965-01-09 | 731 Fondren, Houston, TX | M | 30000.00 | 333445555 | 5 |
| Franklin | T | Wong | 333445555 | 1955-12-08 | 638 Voss, Houston, TX | M | 40000.00 | 888665555 | 5 |
| Joyce | A | English | 453453453 | 1972-07-31 | 5631 Rice, Houston, TX | F | 25000.00 | 333445555 | 5 |
| Ramesh | K | Narayan | 666884444 | 1962-09-15 | 975 Fire Oak, Humble, TX | M | 38000.00 | 333445555 | 5 |
| James | E | Borg | 888665555 | 1937-11-10 | 450 Stone, Houston, TX | M | 55000.00 | NULL | 1 |
| Jennifer | S | Wallace | 987654321 | 1941-06-20 | 291 Berry, Bellaire, TX | F | 43000.00 | 888665555 | 4 |
| Ahmad | V | Jabbar | 987987987 | 1969-03-29 | 980 Dallas, Houston, TX | M | 25000.00 | 987654321 | 4 |
| Alicia | J | Zelaya | 999887777 | 1968-07-19 | 3321 Castle, Spring, TX | F | 25000.00 | 987654321 | 4 |
+----------+-------+---------+-----------+------------+--------------------------+------+----------+-----------+------+
Das Klassendiagramm der Abbildung 4 zeigt die zentralen Klassen des Paketes
java.sql.
Auffallend ist, daß alle Elemente des dargestellten Pakets
-- abgesehen von den definierten Exceptionklassen -- als
Schnittstellen ausgelegt sind. Durch diese Mimik wird die
Organisation der JDBC-Schnittstelle deutlich. Die API legt
lediglich das Verhalten hinsichtlich seiner Semantik und
die Einzeloperationen durch Definition ihrer Parameter
fest, die konkrete DBMS-spezifische Implementierung dieser
Operationen wird durch den JDBC-Treiber bereitgestellt.
Zentrale Klasse der JDBC-API ist die Schnittstelle Connection. Sie bildet die
Kommunikationsverbindungen zum DBMS ab und bietet
notwendige Verwaltungsoperationen.
Hierunter fallen insbesondere auch die Aufrufe zur Transaktionssteuerung.
Die Schnittstelle Statement realisiert genau eine aus
Javasicht atomare Datenbankaktion. Diese muß hierbei aus
minimal einem Aufruf an das DBMS bestehen, kann aber
eine Reihe separater Aufrufe zu einem Batch
bündeln.
Als Sonderform sieht die API die Spezialisierung PreparedStatement
vor, die es gestattet, parametrisierte Anfragen zwischenzuspeichern, die nach Belegung der Parameterfelder an das DBMS übergeben
werden. Hierdurch wird ein einfacher Mechanismus zur Wiederverwendung von DBMS-Aufrufen etabliert.
Liefert eine DBMS-Anfrage Ergebnistupel, so werden
diese konform zur Schnittstelle ResultSet verwaltet. Diese Schnittstelle
erlaubt die lesende Traversierung der vom DBMS gelieferten
Tupel ebenso wie ihre Aktualisierung im Hauptspeicher und
das anschließende Zurückschreiben in die Datenbank.
Die in der Abbildung nur durch getXXX und updateXXX angedeuteten
Operationen existieren in Ausprägungen für alle unterstützten Datentypen, wobei XXX den Namen
des Typs bezeichnet.
Ferner definiert die API mit SQLWarning eine Ausnahme zur Behandlung
auftretender Fehlersituationen sowie eine Reihe weiterer,
in der Abbildung 4 nicht
dargestellter Klassen wie beispielsweise verschiedene
Datentypen.
Die Klasse SQLException
bietet durch ihre Methoden getErrorCode und getSQLState Möglichkeiten an um die nähere Ursache eines datenbankseitigen Fehlers zu ermitteln.
Zusätzlich gestatten Objekte dieses Ausnahmetyps die Verschachtelung von Ausnahmen, d.h. die rekursive Einbettung eines Ausnahmeereignisobjekts in ein bestehendes. Auf diesem Wege können aufgetretene Fehler durch mehrere Ausnahmeobjekte näher spezifiziert werden.
Beispiel 42 zeigt die Abfrage von Details der empfangenen und aller eingebetteten Ausnahmeereignisobjekte mittels der durch die JDBC-API vorgesehenen Methoden.
| Beispiel 42: Ermittlung von Fehlerdetails |
Download des Beispiels |
![]()
Mit der Version 1.4 der Java-Standard-Edition wurde die zuvor nur in der JDBC-API zur Verfügung stehende Möglichkeit zur Schachtelung von Ausnahmeereignissen auch für beliebige Ausnahmeereignisobjekte des Typs Throwable definiert.
Anders als die JDBC-API sieht die generische Lösung jedoch die Nutzung der Methode getCause zur Extraktion der eingebetteten Ausnahmeereignisobjekte vor.
Der Code des Beispiels 43 spiegelt daher die Standard-API-konforme Realisierung wieder. Zusätzlich wendet die Lösung die Standard-Methode getMessage zur Ermittlung der deskriptiven Fehlerbeschreibung an.
| Beispiel 43: Standard-API-konforme Ermittlung von Fehlerdetails |
Download des Beispiels |
![]()

Beispiel 44
zeigt den Ablauf zur Aufnahme einer Verbindung mit der
Datenbank jdbctest auf dem lokalen Rechner
(localhost).
Zunächst muß die Klasse des gewählten JDBC-Treibers (im
Beispiel com.mysql.jdbc.Driver vor ihrer Verwendung
geladen werden. Dies geschieht durch den Aufruf der statischen Methode forName auf der Klasse Class.
Der zu ladende Treiber muß hierbei die
JDBC-Schnittstellenklasse Driver implementieren um später durch
die JDBC-API verwendet werden zu können.
Gleichzeitig mit dem dynamischen Ladevorgang erfolgt die Registrierung des
Treibers beim JDBC-DriverManager,
der die Verwaltung der geladenen DB-Treiber übernimmt.
Nach dem erfolgreichen Laden des Treibers wird durch den Aufruf von getConnection (Zeile
16) die Verbindung zur Datenbank hergestellt. Die
anzusprechende Datenbank wird hierbei durch eine URI der
Form
jdbc:mysql://DB-Server/DB-Name
repräsentiert (Zeile 17). Zusätzlich können ein zur
Anmeldung am DB-System benötiger Benutzer (Zeile 18) und sein Paßwort (Zeile 19)
übergeben werden.
| Beispiel 44: Aufbau einer Datenbankverbindung |
Download des Beispiels |
![]()
Zusätzlich stellen die Klassen Driver und
DriverManager die Möglichkeit der Abfrage von
verbindungsunabhängigen Verwaltungsinformationen zur
Verfügung.
| Beispiel 45: Ermittlung von Informationen über Treiber und Treibermanager |
Download des Beispiels Download der Ergebnisdatei |
![]()
Beispiel 45
zeigt die Ermittlung des durch den
DriverManager für alle durch ihn verwalteten
Treiber global definierten Login Timouts, der angibt
wie lange beim Anmeldevorgang an der Datenbank auf eine
Rückmeldung gewartet wird.
Zusätzlich werden für alle verwalteten Treiber
der Klassenname sowie Daten zur Version und zum Stand der
JDBC-Unterstützung ermittelt und ausgegeben.
Der JDBC-Unterstützungsstand gibt an, ob ein gegebener
Treiber die Konformitätstests der Firma SUN bestanden hat.
Voraussetzung hierfür ist u.a. die vollständige
Unterstützung des SQL 92-Standards (entry level).
Diese Interpreatation von Spezifikationskonformität
verwundert etwas, da alle JDBC-Treiber mit Ausnahme der
inhärent DB-neutralen Typ 1
Treiber DBMS-spezifisch realisiert sind. Aus
diesem Grunde bewertet der Konformitätstest vielmehr den
Umsetzungsgrad des SQL-Standards in dem via JDBC genutzten
DBMS als die Güte des JDBC-Treibers selbst.
Seit der JDBC-Schnittstellenversion 2 ist neben der „klassischen“ Zugriffsvariante auch eine auf dem Java Naming and Directory Interface (JNDI) basierende Zugriffsmethodik definiert, deren Verwendung --- abgesehen von der geänderten Mimik im Aufbau der DB-Verbindung --- identisch gestaltet ist.
Jedoch ist, wie in JNDI üblich, vor dem Zugriff ein
benanntes Objekt beim JNDI-Dienst zu registrieren.
Im Falle von JDBC ist dies ein Objekt welches die
Schnittstelle DataSource implementiert.
Der Code des Beispiels 46 zeigt die notwendigen Schritte zur
Registrierung eines MysqlDataSource-Objekts, der durch den MySQL-JDBC-Treiber gelieferten
Implementierung der Schnittstelle
DataSource.
| Beispiel 46: Ablage von Verbindungsinformation in einem JNDI-Verzeichnis |
Download des Beispiels |
![]()
Entsprechend der modifizierten Ablage der Verwaltungsinformation
ändert sich die Erzeugung der
Datenbankverbindung beim Zugriff. Hier wird nun
zunächst über einen Zugriff auf den JNDI-Verzeichnisdienst
das benannte DataSource-Objekt (es trägt den
Namen jdbc/mySrc ermittelt.
Anschließend wird durch das dem Verzeichnisdienst
entnommene DataSource-Objekt die
Datenbankverbindung (d.h. das
Connection-Objekt) erzeugt.
Alle weiteren Schritte zur Interaktion mit der Datenbank
verlaufen dann identisch zur im Beispiel 44 gezeigten
Verbindungsaufnahme.
Der Code des Beispiels 47
zeigt die notwendigen Schritte zur Ermittlung der Referenz auf
das Objekt des Typs DataSource aus dem JNDI-Verzeichnis,
sowie die Erzeugung des Connection-Objekts.
| Beispiel 47: Verbindungsaufbau unter Nutzung von JNDI |
Download des Beispiels |
![]()
Auffallend ist die Ablage des Datenbanknamens im
Verzeichnisdienst mittels des Methodenaufrufs
setDatabaseName. Diese Verschiebung der
Information wird durch die geänderte Mimik der
Erzeugung des Connection-Objekts impliziert.
So sieht die Implementierung dieser Methode für die Klasse
DataSource keine Möglichkeit zur
gleichzeitigen Übergabe von Anmeldenamen, Paßwort und
Datenbank vor.
Vielmehrnoch ist es sogar möglich diese Daten allesamt
innerhalb des JNDI-Verzeichnisdienstes abzulegen. (Für diesen Zweck
stehen die Methoden setUser bzw. setPassword zur Verfügung.)
Als Konsequenz hiervon kann der Verbinungswunsch durch
Aufruf der Methode getConnection ohne weitere
Parameter erfüllt werden.
Diese Umsetzungsweise ist vor ihrer Realisierung
hinsichtlich des damit eintretenden Verlustes an
Sicherheit zu prüfen, da in ihrer Folge eine
Datenbankverbindung allein durch Kenntnis des
JNDI-residenten Namens des
DataSource-Objektes erfolgen kann.
Generell wählen JDBC-Umsetzungen den Weg, jede Ausprägung eines Connection-Objekts
in eine physische Datenbankverbindung abzubilden. Dieses, durchaus der intuitiven Semantik der
Connection-Klasse entsprechende Vorgehen kann jedoch in realen Applikationen, begründet
in der Vielzahl der durch das DBMS zu verwaltenden Verbindungen, zu Zugriffsengpässen führen.
Aus diesem Grunde definiert die JDBC-Schnittstelle Operationen zur Zusammenfassung „gleichartiger“
Zugriffe. Hierzu zählen Zugriffe die unter derselben Nutzerkennung auf dieselbe Datenbank abgewickelt werden.
Diese Zugriffsform tritt insbesondere bei Anwendungen auf, die über nur einen in der Datenbank eingetragenen
Anwender verfügen und die gesamte Nutzerverwaltung datenbanktransparent applikationsseitig abwickeln.
Zur Optimierung von Zugriffen dieser Natur sieht die JDBC-Schnittstelle das sog. Connection Pooling vor,
welches gleichartige Zugriffe bündelt.
Das Beispiel 48 zeigt eine Umsetzung:
| Beispiel 48: Verbindungsaufbau unter Nutzung von Connection Pooling |
Download des Beispiels |
![]()
Statt für jede gewünschte Datenbankverbindung ein zusätzliches Objekt des Type Connection
zu erzeugen, wird die erzeugte Verbindung zur Konstruktion eines Objektes, welches Konform zur Schnittstelle
PooledConnection definiert ist,
verwendet. Dieses sorgt für die Verwaltung der DB-Verbindung und stellt dieselbe physische
Verbindung verschiedenen Anfragern zur Verfügung.
Konsequenterweise wird daher eine neue Verbindung nicht mehr vom DriverManager angefordert, sondern
durch die Methode getConnection der aus der Verwaltungsstruktur entnommenen PooledConnection
beantragt.
Aufgrund der Unterstützung des SQL-Sprachumfanges, durch unveränderte textuelle Propagation an das DBMS sind durch JDBC im Allgemeinen alle Facetten der Datenbanksprache nutzbar, sofern sie durch das verwendete DBMS Unterstützung finden. Hierunter fallen:
JDBC reflektiert jedoch nicht diese Sprach(-sub-)klassen selbst in der API, sondern sieht vielmehr ausschließlich zwei Formen des Zugriffs vor. Solche die tabellenwerte Resultate liefern und solche, deren Ausführung lediglich primitivwertige Rückgabewerte liefert.
Primitivwertige Datenbankzugriffe liefern, abgesehen von
Fehler- oder Warnmeldungen, lediglich die Anzahl der
geänderten Tupel, falls zutreffend, oder 0 zurück.
Aus dieser Festlegung lassen sich diejenigen
SQL-Anweisungstypen ableiten, welche als primitivwertiger
Zugriff realisiert sind. Hierunter fallen alle Operationen
der Datendefinition wie CREATE oder
ALTER TABLE sowie alle Einfüge-
(INSERT) Änderungs- (UPDATE) und
Löschvorgänge (DELETE). Darüberhinaus alle
Operationen zur Administration der Datenbank durch
Rechtevergabe (GRANT, REVOKE).
Zugriffe dieser Art werden generell durch die Methode
executeUpdate, oder einer Abart davon,
realisiert.
| Beispiel 49: Erstellung einer neuen Tabelle |
Download des Beispiels Download der Ergebnisdatei |
![]()
Beispiel 49
zeigt die notwendigen Schritte zur Erstellung der Tabelle EMPLOYEE in
der Datenbank.
Nach dem (üblichen) Verbindungsaufbau (Zeile 8-24) wird
in Zeile 27 eine Variable des Typs Statement deklariert. Auch bei
Statement handelt es sich um eine durch die
JDBC-API vordefinierte Schnittstelle, die als Bestandteil
des JDBC-Treibers von einer Klasse implementiert
wird.
Ausgehend von der etablierten Datenbankverbindung wird
durch Aufruf der Methode createStatement
eine konkrete Ausprägung konform zur
Statement-Schnittstelle erzeugt (Zeile
29).
Der Aufruf von executeUpdate übergibt das als
Zeichenkette abgelegte SQL-Kommando an die Datenbank zur
Ausführung.
Da durch CREATE TABLE keine Tupeländerungen vorgenommen werden ist das
Resultat des Aufrufs der Rückgabewert 0.
Beispiel 50
zeigt mit dem ALTER TABLE-Kommando eine
weitere Anwendung der
executeUpdate-Methode.
Auch in diesem Falle wird als Resultat 0 geliefert, da die Definition des
Primärschlüssels keine Änderungen an den verwalteten Datensätzen vornimmt.
| Beispiel 50: Modifikation der Tabellendefinition |
Download des Beispiels Download der Ergebnisdatei |
![]()
| Beispiel 51: Einfügen von Werten |
Download des Beispiels Download der Ergebnisdatei |
![]()
Beispiel 51
zeigt den Einfügevorgang von acht Werten in die durch die
vorangegangenen Beispiele erzeugte Tabelle
EMPLOYEE.
Jeder der Einfügevorgänge der Zeilen 36-43 führt im Rahmen einer separaten Datenbankkommunikation
sequentiell genau einen Einfügevorgang durch, was durch den Rückgabewert 1 dokumentiert wird.
Zwar ist dieses Verfahren praktikabel und erzielt die angestrebten Resultate, jedoch ist es unter Zeiteffizienzgesichtspunkten inadäquat, da sich Einfüge- und Kommunikationsvorgänge zahlenmäßig entsprechen.
Aus diesem Grunde bietet die Schnittstelle Statement die Möglichkeit zur Bündelung
einzelner SQL-Aufrufe in einem sog. Batch an.
Beispiel 52 zeigt die entsprechende Umgestaltung des vorangegangenen Beispiels.
| Beispiel 52: Einfügen von Werten mittels eines Batches |
Download des Beispiels |
![]()
Statt der Einzelübergabe der SQL
INSERT-Anweisungen werden diese nun (in Zeile
36-43) in in einem Batch gesammelt. Hierzu werden die
SQL-Zeichenketten durch den Aufruf addBatch innerhalb des
Statement-Objekts abgelegt und durch Aufruf
der Methode executeBatch gesammelt an das DBMS
übergeben.
Statt der Einzelresultate wird durch diese Aufrufvariante
ein Array geliefert, das die Einzelrückgabewerte der als
Batch übergebenen Aufrufe versammelt.
Dies verdeutlicht nochmals das nachfolgende Beispiel.
In ihm wird zunächst mittels ALTER TABLE eine
neue Tabellenspalte zur Aufnahme des Wochentages der
Geburt erstellt und anschließend durch SQL
UPDATE-Anweisungen die benötigten Daten aus
dem vorhandenen Geburtsdatum ermittelt.
Auch dieses Beispiel bedient sich zur Performancebeschleunigung der Möglichkeiten des Batchaufrufes.
| Beispiel 53: Aktualisieren von Tabellendefinitionen und Werten |
Download des Beispiels Download der Ergebnisdatei |
![]()
Die Ausführung liefert als Resultat:
Statement No 0 changed 8 rows
Statement No 1 changed 0 rows
Statement No 2 changed 1 rows
Statement No 3 changed 0 rows
Statement No 4 changed 1 rows
Statement No 5 changed 1 rows
Statement No 6 changed 2 rows
Statement No 7 changed 3 rows
So werden durch den ALTER TABLE-Aufruf
(Indexnummer 0) alle acht Tupel der Tabelle modifiziert,
während die nachfolgenden Aufrufe nur Teilmengen davon
verändern.
Die nähere Betrachtung der Zeilen 37-43 des Quellcodes
von Beispiel 53
zeigt sich, daß diese im Kern denselben Vorgang ausführen,
nur jeweils mit variierenden Parametern.
Zur Behandlung von Fällen dieser Problemstellung definiert
die JDBC-API die Schnittstelle PreparedStatement als Spezialisierung
von Statement.
Diese Schnittstelle gestattet es, Anweisungen, die später
an die Datenbank übermittelt werden sollen, mit
Platzhaltern zu versehen und diese vor der Übermittlung
mit Werten zu befüllen.
Beispiel 54 zeigt die entprechende
Modifikation des vorangegangenen Beispiels.
| Beispiel 54: Aktualisieren von Tabellendefinitionen und Werten |
Download des Beispiels Download der Ergebnisdatei |
![]()
Im Beispiel wird neben dem Objekt des Typs Statement
zusätzlich eines des Typs PreparedStatement erzeugt (Zeile 32).
Die dem Konstruktor übergebene Anweisung enthält als Sonderzeichen zur Markierung der Platzhalter
das Fragezeichen (?).
Die Wochentage werde in Zeile 40, des vereinfachten Zugriffs wegen, als Array definiert.
In den Zeilen 42 mit 46 werden die benötigten SQL-UPDATE-Anweisungen dynamisch
durch Einsetzen der geeigneten Werte in den vorpräparierten Änderungsausruck erzeugt und einem eigenen
Batch zugeordnet. Der Einsetzungsvorgang der benötigten Werte geschieht durch die Methoden
setString
für zeichenkettenartige bzw. setInt für den
ganzzahlige Parameter. Den Methoden wird jeweils die Position des Parameters, gezählt ab 1 sowie die zu wählende Wertbelegung übermittelt.
Zur Ausführung müssen beide Batches getrennt angefordert werden.
Die in der Praxis quantitativ bedeutendste Klasse von
Datenbankzugriffen dürfte zweifellos auf die lesende
Ermittlung von bestehenden Daten darstellen, kurzum alle Spielarten der SQL SELECT-Anweisung.
Für Anfragen an die Datenbank steht prinzipiell der gesamte durch das DBMS unterstützte SQL-Umfang zur Verfügung.
Anfragen werden im Gegensatz zu den bisher
betrachteten lesenden Zugriffen nicht als primivwerte
Methoden realisiert, sondern liefern als Resultat immer
eine Tabelle zurück.
Diese wird durch den API-Typ ResultSet dargestellt.
Zusätzlich werden Anfragen durch die Methode executeQuery
ausgeführt.
Das Beispiel 55
zeigt die generische Extraktion von DB-Daten und den Zugriff auf
Metadaten.
Die aus der Datenbank gelesenen Ergebnistupel werden im durch rs
benannten ResultSet abgelegt (Zeile 39). Die Resultatmenge wird
mithilfe eines Cursors (Datensatzzeiger) traversiert. Hierzu wird der initial auf
eine Ausgangsstellung vor dem ersten empfangenen Tupel positionierte Cursor durch Aufruf der Methode
next solange weitergerückt, bis der letzte Datensatz verarbeitet wurde.
Der Aufruf der MethodegetMetaData
liefert deskriptive Metadaten wie Spaltenzahl sowie deren Bezeichner und Typen für die erstellte Resultattupelmenge.
In Zeile 43 werden diese Metadaten verwendet um die
Spaltennamen der extrahierten Attribute anzuzeigen.
Zeile 47-52 liest die einzelnen Werte jedes Tupels mittels
getObject aus und stellt sie am
Bildschirm dar.
| Beispiel 55: Auslesen von Daten und Metadaten |
Download des Beispiels Download der Ergebnisdatei |
![]()
Neben im Beispiel 55
gezeigten Verarbeitung in exakter der Ablagereihenfolge der Datenbank
kann auch durch Definition eines Cursors die Traversierung in
inverser Ablagerichtung erreicht werden.
Das nachfolgende Beispiel illustriert das entsprechende Vorgehen durch anfängliche Positionierung
des Cursors ans Ende der empfangenen Daten (d.h. nach dem letzten Datensatz) und
anschließendes schrittweises Rückpositionieren durch Aufruf der Methode previous.
| Beispiel 56: Auslesen von Daten in invertierter Reihenfolge |
Download des Beispiels Download der Ergebnisdatei |
![]()
Ferner kann der Cursor wahlfrei auf eine beliebige Position der Ergebnisrelation gesetzt werden.
Das nachfolgende Beispiel zeigt dies. Ferner illustriert es das Vorgehen zur Größenermittlung
des resultierenden ResultSets durch das Aufrufpaar last und getRow, welches
zunächst den Cursor auf den letzten aus der Datenbank extrahierten Datensatz positioniert und anschließend dessen
Nummer liefert.
| Beispiel 57: Auslesen von Daten in wahlfreier Reihenfolge |
Download des Beispiels Download der Ergebnisdatei |
![]()
Wird der benötigte ResultSet geeignet
(d.h. mit den Parameter CONCUR_UPDATABLE)
(siehe Zeile 49) initialisiert, so können Änderungen, die im
Hauptspeicher durch die JDBC-API durchgeführt werden, in
die Datenbank persistiert werden.
Beispiel 58 zeigt dies exemplarisch für den
Einfügevorgang eines neuen Tupels.
Die Voraussetzungen für Einfüge- und Aktualisierungsvorgänge entstprechen denen von updatable views, d.h. die Daten dürfen nur aus genau einer Tabelle entnommen sein und müssen den Primärschlüssel enthalten.
| Beispiel 58: Auslesen und Einfügen von Daten |
Download des Beispiels Download der Ergebnisdatei |
![]()
Auf dieselbe Weise können auch Tupel einer Relation
verändert werden. Hierzu stehen eine Reihe von
updateXXX-Methoden zur Verfügung, wobei
XXX für den Typ des zu aktualisierenden
Attributs steht.
Nach durchgeführter Modifikation der
hauptspeicherresidenten Werte werden diese durch updateRow in die Datenbank
rückgeschrieben.
Beispiel 59 zeigt dies:
| Beispiel 59: Modifizieren von Daten |
Download des Beispiels |
![]()
Analog vollzieht sich der Löschvorgang mittels deleteRow:
| Beispiel 60: Löschen von Daten |
Download des Beispiels |
![]()
Die bisher betrachteten Varianten extrahieren Daten aus der Datenbank im Stile einer Momentaufnahme
(snapshot) zum Zeitpunkt der Anfrage. Die einmal angefragten Inhalte können sich jedoch noch zur
Laufzeit der zugreifenden JDBC-Applikation datenbankseitig ändern, wenn sie durch eine andere Applikation
neu geschrieben werden. Zur Gewährleistung der Konsistenz des extrahierten Snapshots mit den tatsächlichen
Datenbankinhalten steht die Operation rowUpdated
zur Verfügung. Sie ermittelt ob der im Hauptspeicher befindliche Wert mit dem aktuellen Datenbankinhalt
übereinstimmt, d.h. ob der DB-Inhalt aktualisiert wurde.
Beispiel 61 zeigt ein Umsetzungsbeispiel.
| Beispiel 61: Test auf geänderte Daten |
Download des Beispiels |
![]()

Die Abbildung zeigt die Ergebnisse einiger Geschwindigkeitsmessungen als Vergleich zwischen dem Zugriff auf eine MySQL-Datenbank unter Nutzung der Textschnittstelle und der Abwicklung derselben Zugriffe mittels JDBC.
Zur Messung wurde eine nicht-indexierte Datenbank mit 107
Einträgen verwendet die aus der Relation tab bestand. Deren Tupel wurden
aus Paaren von 36-Byte großen UUIDs gemäß dem Spezifikationsentwurf
der IETF gebildet.
Zur Zeitmessung wurden folgende Einzeloperationen betrachtet:
INSERT INTO tab
VALUES(...)SELECT COUNT(*) FROM
tabSELECT * FROM
tabUPDATE tab SET UUID1="X" WHERE
UUID1<>"X"X
enthalten.DELETE FROM tab WHERE
UUID2<>"X"X
enthalten.Insgesamt zeigt sich ein ausgewogenes Bild, in welchem
der JDBC-Zugriff lediglich bei datenintensiven Zugriffen
(große Mengen schreibender Zugriffe bei INSERT
bzw. große Mengen lesender Operationen bei
SELECT) im Bereich von fünf Prozent
zurückliegt.
Diese enge Vergleichbarkeit der beiden Zugriffsmodi rührt von den Realisierung des eingesetzten JDBC-Treibers her; insbesondere von der Handhabung der physischen Datenbankverbindung auf Ebene des Netzwerkprotokolls.
Die JDBC-API unterstützt mit Zugriffsmethoden auf die Datentypen BLOB, CLOB,
ARRAY, Object und Ref bereits eine Untermenge des SQL:1999-Standards.
So können, vorausgesetzt das durch JDBC angesprochene DBMS unterstützt dies, große unstrukturierte Binär- oder Textdaten
sowie einfache verschachtelte Tabellen, mithin NF2-Strukturen verwaltet werden.
Beispiel 62 zeigt den Zugriff
auf ein als eingebettete Tabelle realisiertes mengenwertiges Attribut.
Die Beispieldatenbank wurde hierfür wie folgt modifiziert:
alter table EMPLOYEE ADD CAR SET('53M91','521R4', 'LLO415', 'XNU457');
update EMPLOYEE set CAR='XNU457' where SSN=123456789;
update EMPLOYEE set CAR='XNU457,521R4' where SSN="999887777"; | Beispiel 62: Zugriff auf ein mengenwertiges Attribut |
Download des Beispiels |
![]()
Das Beispiel unterstreicht die Rolle der mengenwertigen Attribute als eingebettete Tabellen.
So erfolgt der Zugriff auf die Einzelwerte des Attributs CAR identisch zur Ermittlung der
Resultatmenge der SQL-Anfrage mittels getResultSet. Auch die Traversierung der einzelnen
CAR-Elemente erfolgt äquivalent.
Die Aufnahme der large objects in ihrer Ausprägungsform als Character Large Objects (CLOB)
oder Binary Large Objects (BLOB) stellen eine der zentralen Erweiterungen des SQL:1999-Standards
gegenüber seinen Vorgängern dar.
Zwar ist die Ablage großer unstrukturierter Datenobjekte in relationalen Datenbanken konzeptionell durchaus diskussionswert,
jedoch in der Praxis oftmals, trotz der teilweise erheblichen Geschwindigkeitseinbußen im Zugriff (so benötigt die Ausführung
der Beispielapplikation mit einem 106 Byte großen Datenstrom 1,1 Sekunden, während dieselbe
Operation dateisystembasiert in 0,1 Sekunde abläuft), gewünscht.
Beispiel 63 zeigt die notwendigen Schritte zur Ablage und erneuten Auslese
eines aus einer Datei gewonnen Binärdatenstroms in der Datenbank.
Die Beispieldatenbank wurde hierfür um ein Attribut zur Aufnahme binärer Daten erweitert:ALTER TABLE EMPLOYEE ADD binData blob;
| Beispiel 63: Verarbeitung unstrukturierter Binärdaten |
Download des Beispiels |
![]()
Die Binärdaten können naturgemäß nicht direkt in die SQL-UPDATE-Anweisung eingebunden werden,
sie werden daher einer mittels prepareStatement vorerzeugten Anweisung durch Aufruf der Methode setBinaryStream
übergeben.
Zur Steuerung des transaktionalen Verhaltens einer JDBC-Anfrage bietet die Klasse Connection
verschiedene Methoden an:
getIsolationLevel.TRANSACTION_NONE: Keinerlei TransaktionsunterstützungTRANSACTION_READ_UNCOMMITTED: Auch nicht durch commit freigegebene
Daten werden gelesen. Es können daher dirty reads, Nicht-wiederholbare- und Phantomlesevorgänge
auftreten.TRANSACTION_READ_COMMITTED: Nur durch commit freigegebene
Daten werden gelesen. nichtwiederholbare- und Phantomlesevorgänge können jedoch auftreten.TRANSACTION_REPEATABLE_READ: Innerhalb einer Transaktion können die verarbeiteten
Daten nicht durch eine andere Transaktion verändert werden. Das Auftreten von dirty reads und
nichtwiederholbaren Lesevorgängen ist daher ausgeschlossen, Phantomlesevorgänge sind jedoch weiterhin möglich.TRANSACTION_SERIALIZABLE: Strikte Isolation aller Transaktionen, auf dieser
Stufe sind auch Phantomlesevorgänge ausgeschlossen.setTransactionIsolationsetAutoCommit. Die Übergabe von true bewirkt die Aktivierung des Modus bei
dem jede Einzelanweisung sofort persistent übernommen und für andere Transaktionen sichtbar wird.getAutoCommit ermittelt werden.commit.rollback.rollback(Savepoint s).setSavepoint.Beispiel 1 zeigt
die Nutzung des Transaktionskonzepts.
Zunächst wird die aktuelle Isolationsstufe ermittelt und geprüft ob
das angesprochene DBMS die höchste durch JDBC vorhergesehene Isolationsstufe unterstützt.
Nach Abschaltung der automatischen Änderungsübernahme (setAutoCommit(false)) werden
zunächst zwei Tupel in die Tabelle EMPLOYEE eingefügt, die jedoch nur innerhalb der
laufenden Transaktion sichtbar werden, für alle anderen Transaktionen innerhalb des DBMS bleiben die
neuen Werte (zunächst) unsichtbar.
Eine angenommene Fehlersituation führt zum Rücksetzen der Transaktion durch (rollback).
Nach Abschluß des Programms wurden zwar die beiden ersten Werte lokal in die Datenbank übernommen, aber noch
innerhalb der laufenden Transaktion wieder daraus entfernt, weshalb sie zu keinem Zeitpunkt für andere
Datenbankbenutzer sichtbar waren.
| Beispiel 64: Transaktionsverarbeitung |
Download des Beispiels Download der Ergebnisdatei |
![]()
Neben dem Zurücksetzen einer vollständigen Transaktion bietet
die JDBC-API auch die Möglichkeit alle Schritte bis zu einem anwenderdefierten aus
der Datenbank zu entfernen.
Beispiel 65 zeigt dies unter Verwendung der
Methode setSavepoint zur Definition eines Sicherungspunktes und
rollback(sp) zum Zurücksetzen bis zu diesem Sicherungspunkt.
| Beispiel 65: Transaktionsverarbeitung mit Sicherungspunkten |
Download des Beispiels |
![]()
Der Netzwerkmitschnitt zeigt den TCP-Kommunikationsverlauf
der SQL-Anfrage SELECT * FROM EMPLOYEE;.
Die vom Anfrager an den MySQL-Server übermittelten Datenanteile sind rot hervorgehoben. Zusätzlich
sind die für eine gleichwertige native Kommunikation anfallenden Daten berücksichtigt. Ihre Anteile
entsprechen den zusätzlich durch Fettdruck hervorgehobenen.
0000 4 00 00 00 \n 4 . 0 . 1 2 - s t a n d a r d - l o g 00 ' 00 00 00 N 4 V
0020 5 G D a 9 00 , \b 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 14 00 00 01 87 00 ÿ ÿ
0040 ÿ m a r i o 00 N W N J S ] L K 00 03 00 00 02 00 00 00 \t 00 00 00 02 j d b c
0060 t e s t 03 00 00 01 00 00 00 0f 00 00 00 03 S H O W V A R I A B L E S 01 00
0080 00 01 02 19 00 00 02 00 \r V a r i a b l e _ n a m e 03 1e 00 00 01 þ 03 01 00 1f
00a0 11 00 00 03 00 05 V a l u e 03 00 01 00 01 þ 03 01 00 1f 01 00 00 04 þ \f 00 00 05 \b b
00c0 a c k _ l o g 02 5 0 7 00 00 06 07 b a s e d i r . / o p t / r a i d
00e0 / m y s q l - s t a n d a r d - 4 . 0 . 1 2 - p c - l i n u x -
0100 i 6 8 6 / 18 00 00 07 11 b i n l o g _ c a c h e _ s i z e 05 3 2 7 6
0120 8 00 00 \b 17 b u l k _ i n s e r t _ b u f f e r _ s i z e 07 8 3
0140 8 8 6 0 8 15 00 00 \t \r c h a r a c t e r _ s e t 06 l a t i n 1 á 00
0160 00 \n 0e c h a r a c t e r _ s e t s Ñ l a t i n 1 b i g 5 c z
0180 e c h e u c _ k r g b 2 3 1 2 g b k l a t i n 1 _ d e
01a0 s j i s t i s 6 2 0 u j i s d e c 8 d o s g e r m a n
01c0 1 h p 8 k o i 8 _ r u l a t i n 2 s w e 7 u s a 7 c
01e0 p 1 2 5 1 d a n i s h h e b r e w w i n 1 2 5 1 e s t o
0200 n i a h u n g a r i a n k o i 8 _ u k r w i n 1 2 5 1 u k
0220 r g r e e k w i n 1 2 5 0 c r o a t c p 1 2 5 7 l a t
0240 i n 5 15 00 00 0b 11 c o n c u r r e n t _ i n s e r t 02 O N 12 00 00 \f
0260 0f c o n n e c t _ t i m e o u t 01 5 17 00 00 \r 15 c o n v e r t _ c
0280 h a r a c t e r _ s e t 00 < 00 00 0e 07 d a t a d i r 3 / o p t / r
02a0 a i d / m y s q l - s t a n d a r d - 4 . 0 . 1 2 - p c - l i n
02c0 u x - i 6 8 6 / d a t a / 13 00 00 0f 0f d e l a y _ k e y _ w r i t
02e0 e 02 O N 19 00 00 10 14 d e l a y e d _ i n s e r t _ l i m i t 03 1 0
0300 0 1b 00 00 11 16 d e l a y e d _ i n s e r t _ t i m e o u t 03 3 0 0
0320 18 00 00 12 12 d e l a y e d _ q u e u e _ s i z e 04 1 0 0 0 \n 00 00 13
0340 05 f l u s h 03 O F F \r 00 00 14 \n f l u s h _ t i m e 01 0 ! 00 00 15 11
0360 f t _ b o o l e a n _ s y n t a x 0e + - > < ( ) ~ * : " " & |
0380 12 00 00 16 0f f t _ m i n _ w o r d _ l e n 01 4 14 00 00 17 0f f t _ m a
03a0 x _ w o r d _ l e n 03 2 5 4 1c 00 00 18 18 f t _ m a x _ w o r d _ l
03c0 e n _ f o r _ s o r t 02 2 0 1c 00 00 19 10 f t _ s t o p w o r d _ f
03e0 i l e \n ( b u i l t - i n ) \f 00 00 1a \b h a v e _ b d b 02 N O 0f 00
0400 00 1b \n h a v e _ c r y p t 03 Y E S 10 00 00 1c 0b h a v e _ i n n o d
0420 b 03 Y E S 0e 00 00 1d \t h a v e _ i s a m 03 Y E S \r 00 00 1e \t h a v e
0440 _ r a i d 02 N O 16 00 00 1f \f h a v e _ s y m l i n k \b D I S A B L
0460 E D 10 00 00 \f h a v e _ o p e n s s l 02 N O 15 00 00 ! 10 h a v e _
0480 q u e r y _ c a c h e 03 Y E S 0b 00 00 " \t i n i t _ f i l e 00 ( 00
04a0 00 # 1f i n n o d b _ a d d i t i o n a l _ m e m _ p o o l _ s i
04c0 z e 07 2 0 9 7 1 5 2 ! 00 00 $ 17 i n n o d b _ b u f f e r _ p o o
04e0 l _ s i z e \b 1 6 7 7 7 2 1 6 - 00 00 % 15 i n n o d b _ d a t a _
0500 f i l e _ p a t h 16 i b d a t a 1 : 1 0 M : a u t o e x t e n d
0520 16 00 00 & 14 i n n o d b _ d a t a _ h o m e _ d i r 00 19 00 00 ' 16 i
0540 n n o d b _ f i l e _ i o _ t h r e a d s 01 4 18 00 00 ( 15 i n n o
0560 d b _ f o r c e _ r e c o v e r y 01 0 1c 00 00 ) 19 i n n o d b _ t
0580 h r e a d _ c o n c u r r e n c y 01 8 ! 00 00 * 1e i n n o d b _ f
05a0 l u s h _ l o g _ a t _ t r x _ c o m m i t 01 1 18 00 00 + 14 i n n
05c0 o d b _ f a s t _ s h u t d o w n 02 O N 15 00 00 , 13 i n n o d b _
05e0 f l u s h _ m e t h o d 00 1c 00 00 - 18 i n n o d b _ l o c k _ w a
0600 i t _ t i m e o u t 02 5 0 17 00 00 . 13 i n n o d b _ l o g _ a r c
0620 h _ d i r 02 . / 17 00 00 / 12 i n n o d b _ l o g _ a r c h i v e 03
0640 O F F 1f 00 00 0 16 i n n o d b _ l o g _ b u f f e r _ s i z e 07 8
0660 3 8 8 6 0 8 1d 00 00 1 14 i n n o d b _ l o g _ f i l e _ s i z e 07
0680 5 2 4 2 8 8 0 1c 00 00 2 19 i n n o d b _ l o g _ f i l e s _ i n _
06a0 g r o u p 01 2 1d 00 00 3 19 i n n o d b _ l o g _ g r o u p _ h o m
06c0 e _ d i r 02 . / 1d 00 00 4 1a i n n o d b _ m i r r o r e d _ l o g
06e0 _ g r o u p s 01 1 1a 00 00 5 13 i n t e r a c t i v e _ t i m e o u
0700 t 05 2 8 8 0 0 18 00 00 6 10 j o i n _ b u f f e r _ s i z e 06 1 3 1
0720 0 7 2 19 00 00 7 0f k e y _ b u f f e r _ s i z e \b 1 6 7 7 7 2 1 6
0740 L 00 00 8 \b l a n g u a g e B / o p t / r a i d / m y s q l - s t
0760 a n d a r d - 4 . 0 . 1 2 - p c - l i n u x - i 6 8 6 / s h a r
0780 e / m y s q l / e n g l i s h / 17 00 00 9 13 l a r g e _ f i l e s
07a0 _ s u p p o r t 02 O N 10 00 00 : \f l o c a l _ i n f i l e 02 O N 15
07c0 00 00 ; 10 l o c k e d _ i n _ m e m o r y 03 O F F \b 00 00 < 03 l o g
07e0 03 O F F 0f 00 00 = \n l o g _ u p d a t e 03 O F F 0b 00 00 > 07 l o g _
0800 b i n 02 O N 16 00 00 ? 11 l o g _ s l a v e _ u p d a t e s 03 O F F
0820 15 00 00 @ 10 l o g _ s l o w _ q u e r i e s 03 O F F 11 00 00 A \f l o
0840 g _ w a r n i n g s 03 O F F 13 00 00 B 0f l o n g _ q u e r y _ t i
0860 m e 02 1 0 19 00 00 C 14 l o w _ p r i o r i t y _ u p d a t e s 03 O
0880 F F 1b 00 00 D 16 l o w e r _ c a s e _ t a b l e _ n a m e s 03 O F
08a0 F 1b 00 00 E 12 m a x _ a l l o w e d _ p a c k e t 07 1 0 4 7 5 5 2
08c0 ! 00 00 F 15 m a x _ b i n l o g _ c a c h e _ s i z e \n 4 2 9 4 9
08e0 6 7 2 9 5 1b 00 00 G 0f m a x _ b i n l o g _ s i z e \n 1 0 7 3 7 4
0900 1 8 2 4 14 00 00 H 0f m a x _ c o n n e c t i o n s 03 1 0 0 16 00 00 I
0920 12 m a x _ c o n n e c t _ e r r o r s 02 1 0 17 00 00 J 13 m a x _ d
0940 e l a y e d _ t h r e a d s 02 2 0 1d 00 00 K 13 m a x _ h e a p _ t
0960 a b l e _ s i z e \b 1 6 7 7 7 2 1 6 19 00 00 L \r m a x _ j o i n _
0980 s i z e \n 4 2 9 4 9 6 7 2 9 5 15 00 00 M 0f m a x _ s o r t _ l e n
09a0 g t h 04 1 0 2 4 17 00 00 N 14 m a x _ u s e r _ c o n n e c t i o n
09c0 s 01 0 12 00 00 O 0e m a x _ t m p _ t a b l e s 02 3 2 00 00 P 14 m a
09e0 x _ w r i t e _ l o c k _ c o u n t \n 4 2 9 4 9 6 7 2 9 5 * 00 00
0a00 Q 1f m y i s a m _ m a x _ e x t r a _ s o r t _ f i l e _ s i z
0a20 e \t 2 6 8 4 3 5 4 5 6 % 00 00 R 19 m y i s a m _ m a x _ s o r t _
0a40 f i l e _ s i z e \n 2 1 4 7 4 8 3 6 4 7 1b 00 00 S 16 m y i s a m _
0a60 r e c o v e r _ o p t i o n s 03 O F F 00 00 T 17 m y i s a m _ s
0a80 o r t _ b u f f e r _ s i z e 07 8 3 8 8 6 0 8 17 00 00 U 11 n e t _
0aa0 b u f f e r _ l e n g t h 04 8 1 9 2 14 00 00 V 10 n e t _ r e a d _
0ac0 t i m e o u t 02 3 0 13 00 00 W 0f n e t _ r e t r y _ c o u n t 02 1
0ae0 0 15 00 00 X 11 n e t _ w r i t e _ t i m e o u t 02 6 0 \b 00 00 Y 03 n
0b00 e w 03 O F F 13 00 00 Z 10 o p e n _ f i l e s _ l i m i t 01 0 F 00 00
0b20 [ \b p i d _ f i l e < / o p t / r a i d / m y s q l - s t a n d
0b40 a r d - 4 . 0 . 1 2 - p c - l i n u x - i 6 8 6 / d a t a / l i
0b60 n u x . p i d 0b 00 00 \ \t l o g _ e r r o r 00 \n 00 00 ] 04 p o r t 04
0b80 3 3 0 6 14 00 00 ^ 10 p r o t o c o l _ v e r s i o n 02 1 0 18 00 00 _
0ba0 10 r e a d _ b u f f e r _ s i z e 06 1 3 1 0 7 2 1c 00 00 ` 14 r e a
0bc0 d _ r n d _ b u f f e r _ s i z e 06 2 6 2 1 4 4 14 00 00 a 11 r p l
0be0 _ r e c o v e r y _ r a n k 01 0 1a 00 00 b 11 q u e r y _ c a c h e
0c00 _ l i m i t 07 1 0 4 8 5 7 6 13 00 00 c 10 q u e r y _ c a c h e _ s
0c20 i z e 01 0 14 00 00 d 10 q u e r y _ c a c h e _ t y p e 02 O N \f 00 00
0c40 e \t s e r v e r _ i d 01 1 17 00 00 f 11 s l a v e _ n e t _ t i m e
0c60 o u t 04 3 6 0 0 19 00 00 g 15 s k i p _ e x t e r n a l _ l o c k i
0c80 n g 02 O N 14 00 00 h 0f s k i p _ n e t w o r k i n g 03 O F F 17 00 00
0ca0 i 12 s k i p _ s h o w _ d a t a b a s e 03 O F F 13 00 00 j 10 s l o
0cc0 w _ l a u n c h _ t i m e 01 2 17 00 00 k 06 s o c k e t 0f / t m p /
0ce0 m y s q l . s o c k 18 00 00 l 10 s o r t _ b u f f e r _ s i z e 06
0d00 5 2 4 2 8 0 0b 00 00 m \b s q l _ m o d e 01 0 0f 00 00 n 0b t a b l e _
0d20 c a c h e 02 6 4 12 00 00 o \n t a b l e _ t y p e 06 I N N O D B 14 00
0d40 00 p 11 t h r e a d _ c a c h e _ s i z e 01 0 14 00 00 q \f t h r e a
0d60 d _ s t a c k 06 1 9 6 6 0 8 1d 00 00 r \f t x _ i s o l a t i o n 0f
0d80 R E P E A T A B L E - R E A D 0e 00 00 s \b t i m e z o n e 04 C E S
0da0 T 18 00 00 t 0e t m p _ t a b l e _ s i z e \b 3 3 5 5 4 4 3 2 \r 00 00
0dc0 u 06 t m p d i r 05 / t m p / 1c 00 00 v 07 v e r s i o n 13 4 . 0 . 1
0de0 2 - s t a n d a r d - l o g 13 00 00 w \f w a i t _ t i m e o u t 05
0e00 2 8 8 0 0 01 00 00 x þ 11 00 00 00 03 S E T a u t o c o m m i t = 1 03
0e20 00 00 01 00 00 00 18 00 00 00 03 S E L E C T * F R O M E M P L O Y E
0e40 E ; 01 00 00 01 \n 19 00 00 02 \b E M P L O Y E E 05 F N A M E 03 \n 00 00 01 ý
0e60 03 01 00 00 19 00 00 03 \b E M P L O Y E E 05 M I N I T 03 01 00 00 01 þ 03 00 00
0e80 00 19 00 00 04 \b E M P L O Y E E 05 L N A M E 03 \n 00 00 01 ý 03 01 00 00 17 00
0ea0 00 05 \b E M P L O Y E E 03 S S N 03 \t 00 00 01 03 03 01 00 00 19 00 00 06 \b E M
0ec0 P L O Y E E 05 B D A T E 03 \n 00 00 01 \n 03 00 00 00 1b 00 00 07 \b E M P L O
0ee0 Y E E 07 A D D R E S S 03 1e 00 00 01 ý 03 00 00 00 17 00 00 \b \b E M P L O Y
0f00 E E 03 S E X 03 01 00 00 01 þ 03 00 01 00 1a 00 00 \t \b E M P L O Y E E 06 S A
0f20 L A R Y 03 07 00 00 01 05 03 00 02 1c 00 00 \n \b E M P L O Y E E \b S U P E
0f40 R S S N 03 \t 00 00 01 03 03 00 00 00 17 00 00 0b \b E M P L O Y E E 03 D N O 03
0f60 01 00 00 01 03 03 00 00 00 01 00 00 \f þ R 00 00 \r 04 J o h n 01 B 05 S m i t h \t
0f80 1 2 3 4 5 6 7 8 9 \n 1 9 6 5 - 0 1 - 0 9 18 7 3 1 F o n d r e n
0fa0 , H o u s t o n , T X 01 M \b 3 0 0 0 0 . 0 0 \t 3 3 3 4 4 5 5
0fc0 5 5 01 5 R 00 00 0e \b F r a n k l i n 01 T 04 W o n g \t 3 3 3 4 4 5 5
0fe0 5 5 \n 1 9 5 5 - 1 2 - 0 8 15 6 3 8 V o s s , H o u s t o n ,
1000 T X 01 M \b 4 0 0 0 0 . 0 0 \t 8 8 8 6 6 5 5 5 5 01 5 T 00 00 0f 06 A
1020 l i c i a 01 J 06 Z e l a y a \t 9 9 9 8 8 7 7 7 7 \n 1 9 6 8 - 0 7
1040 - 1 9 17 3 3 2 1 C a s t l e , S p r i n g , T X 01 F \b 2 5
1060 0 0 0 . 0 0 \t 9 8 7 6 5 4 3 2 1 01 4 W 00 00 10 \b J e n n i f e r 01
1080 S 07 W a l l a c e \t 9 8 7 6 5 4 3 2 1 \n 1 9 4 1 - 0 6 - 2 0 17 2
10a0 9 1 B e r r y , B e l l a i r e , T X 01 F \b 4 3 0 0 0 . 0
10c0 0 \t 8 8 8 6 6 5 5 5 5 01 4 V 00 00 11 06 R a m e s h 01 K 07 N a r a y
10e0 a n \t 6 6 6 8 8 4 4 4 4 \n 1 9 6 2 - 0 9 - 1 5 18 9 7 5 F i r e
1100 O a k , H u m b l e , T X 01 M \b 3 8 0 0 0 . 0 0 \t 3 3 3 4
1120 4 5 5 5 5 01 5 S 00 00 12 05 J o y c e 01 A 07 E n g l i s h \t 4 5 3 4
1140 5 3 4 5 3 \n 1 9 7 2 - 0 7 - 3 1 16 5 6 3 1 R i c e , H o u s
1160 t o n , T X 01 F \b 2 5 0 0 0 . 0 0 \t 3 3 3 4 4 5 5 5 5 01 5 S 00
1180 00 13 05 A h m a d 01 V 06 J a b b a r \t 9 8 7 9 8 7 9 8 7 \n 1 9 6 9
11a0 - 0 3 - 2 9 17 9 8 0 D a l l a s , H o u s t o n , T X 01 M
11c0 \b 2 5 0 0 0 . 0 0 \t 9 8 7 6 5 4 3 2 1 01 4 G 00 00 14 05 J a m e s 01
11e0 E 04 B o r g \t 8 8 8 6 6 5 5 5 5 \n 1 9 3 7 - 1 1 - 1 0 16 4 5 0
1200 S t o n e , H o u s t o n , T X 01 M \b 5 5 0 0 0 . 0 0 û 01 1
1220 01 00 00 15 þDie Analyse des Datenverkehrs zeigt, daß im Falle der JDBC-basierten Kommunikation
ein gegenüber der nativen Schnittstelle um 3529 Byte vergrößertes Datenaufkommen ausgetauscht wird.
Diese zusätzliche Datenmenge fällt jedoch nur einmal zum Zeitpunkt des JDBC-Verbindungsaufbaus statisch an.
(Vgl. Mitschnitt der mehrfachen Ausführung einer SQL-Anfrage innerhalb einer
bestehenden JDBC-Verbindung)
Zusätzlich offenbart Zeile 0x40 des Datenverkehrs die verschlüsselte Übermittlung des Paßwortes des
Anwenders mario. Allerdings werden die per Anfrage ermittelten Nutzdaten (ab Zeile 0xe40) unverschlüsselt
über die Netzwerkschnittstelle übertragen und stellen somit ein potentielles Angriffsziel dar.
Abhilfe hierfür kann die Tunnelung des Datenverkehrs, beispielsweise mittels
SSH,
durch eine sichere Verbindung bieten.
Zwar legt die JDBC-Schnittstelle inhärent eine relationale und damit tabellenorientierte
Sicht der zu verarbeitenden Datenquelle zugrunde, jedoch ist die Nutzung der JDBC keinesweges
auf jeden Anwendungsfall beschränkt.
Beispielsweise steht mit dem Produkt Sunopsis XML Driver (JDBC Edition)
ein JDBC-Treiber für den dateibasierten Zugriff auf XML-Inhalte zur Verfügung.
Der Code des Beispiels 66 zeigt die Verwendung.
Als Beispiel dient folgende XML-Datei:
<?xml version="1.0" encoding="ISO-8859-1"?>
<Employees>
<Employee>
<FName>John</FName>
<Minit>B</Minit>
<LName>Smith</LName>
</Employee>
<Employee>
<FName>Franklin</FName>
<Minit>T</Minit>
<LName>Wong</LName>
</Employee>
<Employee>
<FName>Alicia</FName>
<Minit>J</Minit>
<LName>Zelaya</LName>
</Employee>
<Employee>
<FName>Jennnifer</FName>
<Minit>S</Minit>
<LName>Wallace</LName>
</Employee>
<Employee>
<FName>Ramesh</FName>
<Minit>K</Minit>
<LName>Narayan</LName>
</Employee>
<Employee>
<FName>Joyce</FName>
<Minit>A</Minit>
<LName>English</LName>
</Employee>
</Employees>
| Beispiel 66: JDBC-artige Verarbeitung von XML-Dateien |
Download des Beispiels Download der Ergebnisdatei |
![]()
| Web-Referenzen 9: Weiterführende Links |
![]()
Neben den bereits aus anderen Veranstaltungen bekannten Servlets und den davon abgeleiteten Java Server Pages bildet die Technik der Enterprise Java Beans (EJB) einen weiteren zentralen Baustein der Java 2 Enterprise Plattform. Als serverseitige Komponenten kommt den EJBs heute große Bedeutung in der Realisierung komplexer Anwendungen, insbesondere durch Umsetzung der sog. „Business Logik“, d.h. den nicht-interaktiven fachlichen Anwendungsteilen, zu.
Der Begriff der Enterprise Java Bean stützt sich auf dem historisch älteren der Java Bean. Eine solche stellt eine abgeschlossene wiederverwendbare Softwarekomponente dar, die nach ihrer Erstellung über festgelegte Schnittstellen parametrisiert und manipuliert werden kann. Hierzu muß eine Bean eine festgelegte Interaktionsschnittstelle bieten, die durch die Java Bean Spezifikation definiert ist. Es handelt sich dabei um eine Reihe von Konventionen, der eine Bean gehorchen muß, jedoch um keine festgelegte API, die durch eine Komponente zu implementieren ist.
Der Begriff der Enterprise Java Bean greift diese inhaltliche Fundierung auf und präzisiert gleichzeitig die technische Umsetzung. So stellt eine Enterprise Java Bean eine Softwarekomponente dar, die in einer festgelegten Ausführungsumgebung, welche durch die EJB-Spezifikation festgelegte Dienste zur Nutzung durch die Beans anbieten kann. Eine solche Ausführungsumgebung wird als Container bezeichnet.
Ziel der Trennung in Komponente und Ausführungsumgebung ist die Zielsetzung, die Enterprise Java Bean ausschließlich zur Umsetzung fachlicher Aufgaben heranzuziehen und alle infrastrukturellen Fragestellungen wie Betriebsmittelverwaltung, Persistenz oder Sicherheit durch die Ausführungsumgebung in gleicher Weise für alle Komponenten bereitzustellen.
Ein EJB-Container wird zumeist im Rahmen eines Application-Servers bereitgestellt.
Die gelegentlich anzutreffende Hervorhebung der anfänglich für Java Beans intendierten visuellen Manipulationsmöglichkeit trifft für Enterprise Java Beans nicht zu und hat sich für Java Beans auch nur begrenzte Bedeutung erlangt.
Spezifikationsgemäß können EJB-Container folgende Eigenschaften offerieren:
Neben den in der Aufzählung dargestellten Eigenschaften dürfen Container zusätzlich Weitere wahlfrei implementieren.
Grundsätzlich lassen sich alle EJBs drei Typen zuordnen: Session Beans, Entity Beans und Message Driven Beans. Während erstere hauptsächlich zur Abbildung von Abläufen eingesetzt werden, dienen Entity Beans der Abwicklung von Zugriffen auf Daten. Eine Sonderstellung nehmen die Message Driven Beans ein, die lediglich hinsichtlich ihres Kommunikationsverhaltens festgelegt sind.
Session Beans dienen der Abbildung von Abläufen im Rahmen der Programmierung der sog. Business Logik. Die Lebensdauer (d.h. Zeitspanne zwischen Erzeugung im und Entfernung aus dem Hauptspeicher) ist daher identisch mit der einer durch den Client erfolgenden Anfrage. Jede zu einem Zeitpunkt existierende Session Bean repräsentiert daher eine zugehörige Clientinstanz.
Nach ihrer internen Ausgestaltung werden stateless und statefull Session Beans unterschieden. Während Erstere keinen über einen einzigen Aufruf hinausgehenden Zustand verwalten und daher seiteneffektfrei lediglich auf den durch den Aufruf übermittelten Daten operieren erhält das zustandserhaltende Pendant die Daten eines Aufrufs und kann diese auch in nachfolgenden Aufrufen verarbeiten.
Entity Beans sind programmiersprachliche Stellvertreter datenbankresidenter Objekte. Sie dienen dem erleichterten Zugriff auf persistent vorliegende Datenbestände. Ihre interne Realisierung ist eng mit der Technik relationaler Datenbankmanagement System verbunden. So werden Sie durch einen anwenderdefinierten Primärschlüssel dauerhaft identifiziert.
Message Driven Beans sind hinsichtlich ihres Kommunikationsverhaltens auf asynchrone Aufrufe beschränkt. Die Realisierung des eigentlichen Verhaltens wird durch eine Ausprägung eines der anderen Beantypen geboten.
Konzeptionell umfaßt jede EJB-Anwendung, die Session Beans einsetzt, die in Abbildung 6 dargestellten Teile:

Gegenüber der Realisierung als RMI-Anwendung benötigt die Umsetzung als zustandslose Session Bean die Erstellung einer sog. „Home-Schnittstelle“ (Home Interface), welche die Operation create zur Instanziierung des serverseitigen EJB-Objekts bietet.
Sie ist im Beispiel 67 dargestellt.
| Beispiel 67: Home-Schnittstelle einer EJB |
Download des Beispiels |
![]()
Die anwenderdefinierte Home-Schnittstelle erweitert die durch die Standard-API vorgegebene Schnittstelle EJBHome. Diese definiert Operationen zur Entfernung existierender EJB-Objekte aus dem Hauptspeicher (remove) sowie zur Ermittlung von Metadaten (getEJBMetaData) oder zum Erhalt eines netzwerkunabhängigen Verweises auf das EJB-Objekt (getHomeHandle).
Im Einzelnen sind dies die Operationen:
EJBMetaData getEJBMetaDate()EJBMetaData-Objekt welches einzelne Eigenschaften einer EJB näher beschreibt. Hierzu zählen: HomeHandle getHomeHandle()HomeHandle zurück, welches eine netzwerkunabhängige Abstraktion des Verweises auf das Home-Objekt realisiert.void remove (Handle h)Handle) identifiziertes EJB-Objekt aus dem Hauptspeicher.void remove (Object pk)Interessanterweise definiert die Schnittstelle zwar Operationen zur Ermittlung von Daten über bestehende Objekte und zur Entfernung dieser Objekte aus dem Hauptspeicher, nicht jedoch zu ihrer Erzeugung.
Dies liegt in der durch die Programmiersprache Java angestrebten statischen Typsicherheit begründet, die es nicht gestattet Operationen mit variablen Parameterlisten --- wie sie für die zum API-Erstellungszeitpunkt unbekannten spezifischen Initialisierungsparameter aller denkbaren EJBs benötigt würden --- zu versehen.
Aus diesem Grunde definiert die EJB-Spezifikation informell, daß ein diese Schnittstelle erweiternde eigene Home-Schnittstelle zusätzlich die Methode create, deren Signatur als Rückgabetyp den Typ der Remote-Schnittstelle vorsehen muß definiert. Zusätzlich enthält diese Operation die zur Initialisierung der Bean benötigten Parameter in ihrer Parameterliste.
Die im Beispiel 68 ist Remote-Schnittstelle dargestellt, deren Ausprägungen von Home-Objekten angesprochenen werden:
| Beispiel 68: Remote-Schnittstelle einer EJB |
Download des Beispiels |
![]()
Schnittstellen dieses Typs enthalten ausschließlich die fachlichen Operationen, d.h. die Signaturen der Methoden, die später durch den Client benutzt werden.
Jede Remote-Schnittstelle erweitert zusätzlich die vorgegebene Schnittstelle EJBObject, welche, ähnlich zur Home-Schnittstelle, einige Operationen zur Verwaltung eines EJB-Objektes vorgibt:
EJBHome getEJBHome()Handle getHandle()HomeHandle zurück, welches eine netzwerkunabhängige Abstraktion des Verweises auf das Home-Objekt realisiert.Object getPrimaryKey()boolean isIdentical(EJBObject eo)void remove()Beispiel 69 zeigt die Implementierung der Bean selbst:
| Beispiel 69: Realisierung einer Session Bean |
Download des Beispiels |
![]()
Die programmiersprachliche Umsetzung der Bean enthält die Methoden der in der Remote-Schnittstelle bekanntgegebenen fachlichen Operationen. Zusätzlich muß ein Konstruktur expliziert werden, dessen Parameterliste mit den für die Operation create des Home-Interfaces gegebenen übereinstimmen.
Spezifikationsgemäß muß jede Session Bean die gleichnamige API-Schnittstelle implementieren. Diese definiert einige Operationen zur Behandlung unterschiedlicher Lebenszyklusstadien einer EJB. Hierunter fallen Methoden, die beim Erzeugen (ejbCreate), Entfernen (ejbRemove), bei der Passivierung (d.h. Auslagerung auf Hintergrundspeicher) (ejbPassivate) und dessen Reaktivierung (ejbActivate) eines EJB-Objekts durch die Ausführungsumgebung aufgerufen werden.
Bei der zwingend zu implementierenden Schnittstelle SessionBean handelt es sich nicht nur um eine Konvention um die Umsetzung der Lebenszyklusschnittstelle sicherzustellen, sondern auch um die Kategorisierung der Bean selbst. So stellt die im Beispiel verwandte Schnittstelle SessionBean neben EntityBean und MessageDrivenBean eine Spezialisierung der (operationslosen) Schnittstelle EnterpriseBean dar, deren „Implementierung“ durch eine Klasse lediglich zur Kennzeichnung dieser als EJB herangezogen wird.
Die genannten Spezialisierungen dieser Schnittstelle erfüllen daher sowohl den Zweck der Ausübung des Implementierungszwanges für die in ihnen aufgeführten Operationen als auch den der typisierenden Kennzeichnung.
Darüberhinaus ist EnterpriseBean als Spezialisierung der Standard-Schnittstelle Serializable angelegt. In der Konsequenz muß jedes EJB-Objekt durch die Javasprachmechnismen serialisierbar sein. Diese Eigenschaft wird insbesondere für die Passivierung und im Rahmen der Entity Beans genutzt.
Konzeptionell erinnert die Trennung in publizierte fachliche Schnittstelle (Remote-Schnittstelle) und deren technischer Umsetzung durch die EJB an die aus der Betrachtung des Remote Method Invocation Mechanismus bekannte Struktur.
Allerdings weicht die Umsetzung der Bean von der dort anzutreffenden Konvention ab, die publizierte Schnittstelle selbst durch die realisierende Klasse zu implementieren. Dies liegt vor allem an der gegenüber RMI veränderten Struktur der publizierten Schnittstelle begründet. Während RMI für die Schnittstelle die Spezialisierung der operationslosen Standardschnittstelle Remote fordert die EJB-Spezifikation die Erweiterung der Schnittstelle EJBObject, welche selbst die oben dargestellten Operationen definiert. Aus diesem Grunde würde die Aufnahme der Remote-Schnittstelle, obwohl konzeptionell durchaus zu rechtfertigen, in die Umsetzungsliste der EJB gleichzeitig die Implementierung von zumindest leeren Methodenrümpfen für die in EJBObject definierten Operationen notwendig werden lassen.
Abgesehen von dieser Ausnahme rekonstruiert das Verhältnis zwischen EJB und deren Remote-Schnittstelle die aus RMI bekannte Beziehung zwischen Schnittstelle und Umsetzung.
Die Nutzung einer durch eine Java Bean angebotenen Funktionalität erfolgt gemäß dem in Abbildung 6 dargestellten Schema. Ein dies umsetzender Client ist in Beispiel 70 dargestellt.
| Beispiel 70: Zugriff auf eine Session Bean |
Download des Beispiels |
![]()
Zunächst ermittelt der Client unter Nutzung der JNDI-API eine Referenz auf die EJB. Dies geschieht durch Anfrage (lookup) an den JNDI-Dienst unter Übergabe des bekannten Klarnamens (helloBean).
Die erhaltene generische Referenz wird durch Aufruf der statischen Methode narrow der Klasse PortableRemoteObject typsicher in eine Ausprägung der Home-Schnittstelle konvertiert.
Der Aufruf der in dieser Schnittstelle durch den Anwender definierten create-Methode sorgt für die serverseitige Instanziierung der EJB, die als Ausprägung der Remote-Schnittstelle geliefert wird. Tatsächlich wird nicht das EJB-Objekt selbst durch den Methodenaufruf retourniert, sondern lediglich ein netzwerktransparenter Verweis darauf, der jedoch clientseitig einer lokalen Objektreferenz gleichgestellt verwendet werden kann.
Ferner wird serverseitig zur Kommunikation mit der EJB ein Home-Objekt erzeugt, welchem eine Stellvertreterrolle für den anfragenden Client zukommt.
Der Aufruf der durch die EJB zur Verfügung gestellten Methode erfolgt identisch zu dem einer Lokalen.
Die zweite zentrale Klasse von Enterprise Java Beans bilden die zur serverseitigen Persistierung von Objekten dienenden Entity Beans.
Sie kapseln Datenbankinhalte durch Objekte, die gemäß der EJB-Spezifikation instanziierbar und zugreifbar sind. Die Verwaltung der gekapselten Dateninhalte erfolgt durch ein frei festlegbares Datenbankmanagementsystem, die der Objekte selbst durch den EJB-Container.
Ziel dieser Technik ist es die Komplexität der Persistenzlogik für den Verwender der bereitgestellten Bean vollkommen transparent zu gestalten und serverseitig zu realisieren.
Die Familie der Entity Beans selbst zerfällt in zwei Untertypen, welche sich entlang des Realisierungspunktes der Persistenzlogik separieren: Bean Managed Persistence, der Bean obliegt die Umsetzung der Persistenzlogik, und Container Managed Persistence, hierbei wird die Persistenzlogik durch den EJB-Container realisiert.
Das nachfolgende Beispiel zeigt die Umsetzung einer Entity Bean mit Bean Managed Persistence. Es kapselt die Verwaltung und den Zugriff auf Objekte, die Personen beschreiben. Jedes Personen-Objekt enthält Daten zu Name, Geburtsdatum und Wohnstraße. Der Name dient als eindeutige Identifikation und daher datenbankseitig als Primärschlüssel. Die notwendige Datenbanktabelle wurde erzeugt durch den SQL-Ausdruck: CREATE TABLE PERSON( Name VARCHAR(20) PRIMARY KEY, Birthdate DATE, Street VARCHAR(30));
Wie bereits für die Realisierung von Session Beans eingeführt, werden auch zur Publikation der extern zugänglichen Schnittstellen Home und Remote Interfaces benötigt.
Struktur und Aufbau der Home-Schnittstelle ähnelt konzeptionell der für Session Beans eingeführten. Dieser Schnittstellentyp dient auch für Entity Beans zur Aufnahme der Verwaltungsoperationen zur Erzeugung (create) und zur Suche existierender EJBs (findByPrimaryKey).
Beispiel 71 zeigt die Home-Schnittstelle des Beispiels.
| Beispiel 71: Home-Schnittstelle einer Entity Bean |
Download des Beispiels |
![]()
Die Home-Schnittstelle zeigt die create-Operation zur Erzeugung einer neuen EJB-Instanz. Ihre Übergabeparameter dienen zur Konstruktion des neuen Objekts und werden durch die Bean-Implementierung interpretiert.
Ferner enthält die Schnittstelle mit findByPrimaryKey eine Operation, deren Implementierung eine Entity-Bean anhand ihres Primärschlüssels identifiziert und liefert. Aus diesem Grunde erhält die Methode den zu suchenden Wert vom Typ des Primärschlüssels übergeben.
Hinsichtlich der verwendeten Typen zeigt sich bereits hier, daß eine Abbildung der durch die Programmiersprache Java bereitgestellten Typen auf die des eingesetzten Persistenzsystems stattfinden muß. In der im Beispiel gewählten Ausführungsform der durch die EJB selbst verwalteten Persistenz muß diese Abbildung manuell durch den Programmierer bereitgestellt werden.
Die Remote-Schnittstelle gibt die für Nutzer der Bean zugänglichen Geschäftsfunktionen wieder. Daher enthält dieser Schnittstellentyp lediglich Operationen zum Zugriff auf die verwalteten Daten, nicht jedoch zur technischen Verwaltung und Interaktion mit dem Bean-Container.
Per Konvention muß diese Schnittstelle als Spezialisierung der Schnittstelle EJBObject definiert sein. Diese Standardschnittstelle definiert allgemeine Interaktionsformen, wie Löschen (remove), Vergleich (isIdentical) und Ermittlung des Primärschlüsselwertes (getPrimaryKey) die für alle Entity Bean Objekte gleichermaßen benötigt werden.isIdentical liefert den Vergleich zweier serverseitiger EJB-Objekte und ermittelt so, ob zwei Java-Objektreferenzen auf dasselbe Datenbankobjekt zugreifen.getPrimaryKey ermittelt den Wert des Primärschlüssels eines gegebenen EJB-Objekts aus der Datenbank.
Zur Lösung von datenbankresidenten Objekten wird remove eingesetzt. Der Aufruf dieser Methode entfernt ausschließlich die durch die EJB repräsentierten Datenbanktupel, die programmiersprachliche Objektrepräsentation bleibt jedoch über die gesamte Laufzeit (sofern nicht durch Gültigkeitsbereiche oder explizite NULL-Setzung explizit anders gehandhabt) intakt.
| Beispiel 72: Remote-Schnittstelle einer Entity Bean |
Download des Beispiels |
![]()
Beispiel 73 zeigt den vollständigen Code der Bean. Sie implementiert mit EntityBean die Standardschnittstelle aller Entity Beans, welche als Spezialisierung der ausschließlich markierenden Schnittstelle EnterpriseBean die notwendigen Basisoperationen zur Abwicklung der persistenten Speicherung bieten.
Im Falle einer Bean Managed Persistence enthalten die Methoden der durch die Schnittstelle definierten und der zusätzlich im Rahmen der Spezifikation textuell definierten Operationen die notwendigen Aufrufe zur Ablage eines Objekts in der Datenbank und zu seiner späteren Extraktion daraus.
Im Einzelnen sind dies die Operationen:
| Tabelle 24: Persistenzoperationen einer Entity Bean | ||||||||||||||
|
![]()
| Beispiel 73: Eine Entity Bean |
Download des Beispiels |
![]()
Zusätzlich enthält die Bean des Beispiels mit getAge eine zwar in der Remote-Schnittstelle veröffentlichte Operation, die keinen direkt abgespeicherten Wert liefert, sondern diesen dynamisch zur Ausführungszeit anhand der verfügbaren Daten berechnet.
Alle anderen in der Remote-Schnittstelle aufgeführten Operationen (etwa: getStreet, setStreet) modifizieren lediglich, den durch die Attribute repräsentierten Java-Objektzustand und greifen nicht direkt auf die Datenbank zu.
Innerhalb der Datenbankzugreifenden Methoden muß durch den Anwender die Abbildung der Java-Datentypen auf die des verwendeten Datenbankmanagementsystems erfolgen. Die mit dem Präfix ejb versehenden Methoden zeigen dies für die lesenden und schreibenden DB-Zugriffe. So kann die im Beispiel für name und street verwendete Java-Repräsentation String vergleichsweise leicht in den SQL-Typ VARCHAR abgebildet werden, sofern alle Methoden, die Datenbankinhalte schreiben, sicherstellen, daß nur zum Datenbankschema konforme Werte eingefügt werden. Die Beispielimplementierung zeigt dies examplarisch anhand der Methoden ejbCreate und setStreet.
Für programmiersprachliche Typen, die nicht direkt in DB-Typen abbildbar sind, muß im Falle der Bean Managed Persistence der Bean-Entwickler selbst Sorge für die adäquate Abbildung tragen. Das Beispiel illustriert dies anhand des Java-Datumstyps GregorianCalendar, der manuell in die durch das DBMS erwartete ISO 8601-konforme Darstellung zu überführen ist.
Einige der möglichen Interaktionen mit der Bean zeigt der Code des Clients aus Beispiel 74:
| Beispiel 74: Client der auf eine Entity Bean zugreift |
Download des Beispiels |
![]()
Der Client ermittelt zunächst per JNDI eine Referenz auf die Bean, welche unter dem Namen personBean im Verzeichnisdienst registriert ist.
Die erhaltene generische Referenz wird durch Aufruf der statischen Methode narrow der Klasse PortableRemoteObject typsicher in eine Ausprägung der Home-Schnittstelle (PersonHome) konvertiert.
Der Aufruf der in dieser Schnittstelle durch den Anwender definierten create-Methode sorgt für die serverseitige Instanziierung der EJB, die als Ausprägung der Remote-Schnittstelle geliefert wird. Tatsächlich wird nicht das EJB-Objekt selbst durch den Methodenaufruf retourniert, sondern lediglich ein netzwerktransparenter Verweis darauf, der jedoch clientseitig einer lokalen Objektreferenz gleichgestellt verwendet werden kann.
Ferner wird serverseitig zur Kommunikation mit der EJB ein Home-Objekt erzeugt, welchem eine Stellvertreterrolle für den anfragenden Client zukommt.
Der Aufruf der durch die EJB zur Verfügung gestellten Methode erfolgt identisch zu dem einer Lokalen.
So dient der Aufruf der Methode create zur Erzeugung von serverseitig instanziiert und transparent persistierten EJB-Objekten sowie den lokalen Java-(Stellvertreter-)Objekten für den Zugriff darauf.
Der Aufruf von getAge zeigt die Nutzung einer in der Remote-Schnittstelle veröffentlichten Zugriffsmethode. Mit getPrimaryKey wird die, in der durch die Remote-Schnittstelle erweiterten Schnittstelle EJBObject angesiedelte, Operation zur Ermittlung des Primärschlüsselwertes eines EJB-Objektes aufgerufen.
Die Methode remove stellt dagegen eine durch die Home-Schnittstelle definierte Operation dar. Durch den Aufruf dieser Methode auf dem durch p1 referenzierten Objekt wird durch Ausführung der Beanmethode ejbRemove die die Bean serverseitig repräsentierenden Datenbankeinträge entfernt sowie der durch die Bean belegte Speicherbereich als frei markiert. Alle Versuche nach Aufruf dieser Methode auf der clientseitigen hauptspeicherrepräsentation Wertänderungen durchzuführen führen daher zu einem Fehler.
Die Ermittlung von Referenzen auf existierende EJB-Objekte erfolgt durch die in der Remote-Schnittstelle definierte Methode findByPrimaryKey. Der EJB-Container stellt sicher, daß verschiedene Referenzen auf dasselbe EJB-Objekt synchronisiert in die Datenbank abgebildet werden, so daß keine Inkonsistenzen entstehen.
Für den Betrieb einer Enterprise Java Bean ist neben den bisher betrachteten Schnittstellen-Komponenten und der Realisierung der Bean selbst auch ein als Deployment Deskriptor bezeichnetes XML-Konfigurationsfile notwendig, welches verschiedene Einstellungsdaten sowie die Schnittstellendaten enthält.
Beispiel 75 zeigt ein Beispiel hierfür:
| Beispiel 75: Deployment Deskriptor der Entity Bean |
Download des Beispiels |
![]()
Hintergrund des Ansatzes der Java Data Objects (JDO) ist es, die bestehenden
Schnittstellenmechanismen dahingehend weiterzuentwickeln, daß die Persistenz von Objekten und Objektgraphen
für den Programmierer vollständig transparent durch Komponenten der Laufzeitumgebung zur Verfügung gestellt
werden.
Gleichzeitig etabliert JDO eine Abstraktion der verschiedenen Speicherungsmöglichkeiten und erlaubt es
beispielsweise die dateibasierte Ablage innerhalb des Programmes identisch zur Objektspeicherung
in einem Datenbankmanagementsystem zu handhaben. Auf dieser Basis läßt sich im Bedarfsfalle den
Persistenzdienstleister auszutauschen ohne Änderungen am Programmcode zu erfordern.
Plakativ wird der Ansatz daher, in Anlehnung an die Zielsetzung der Programmiersprache Java des
write once -- run anywhere, als write once -- store anywhere charakterisiert.
Um die weitestgehend transparente Handhabung der Objektpersistenz zu gewährleisten bedient sich JDO eines Ansatzes der über das alleinige Angebot einer Programmierschnittstelle hinausreicht. Die Zielsetzung der möglichst einfach handzuhabenden Interaktion mit den generischen Persistenzmechanismen läßt sich zwar durch das Angebot von durch den Programmierer zu implementierenden Schnittstellen und Persistenzklassen erreichen, jedoch ist der Einsatz signifikant komplexer als der bestehenden Persistenzschnittstellen. Darüberhinaus konterkariert der Zwang bei der Programmerstellung vorgegebene Schnittstellen zu berücksichtigen die Zielsetzung weitestgehender Transparenz der angebotenen Speichermechanismen.
Daher führt JDO die Technik der sog. Bytecodeanreicherung (engl. bytecode enhancing) ein.
Hierbei wird durch eine Programmkomponente vorübersetzer Bytecode so abgeändert, daß die notwendigen
Persistenzanweisungen in den bereits erzeugten ausführbaren Bytecode eingewoben werden.
Die benötigte Übersetzerkomponente wird durch die jeweilige JDO-Implementierung zur Verfügung gestellt und
muß durch den Programmierer im Bedarfsfalle lediglich geeignet parametrisiert werden.
Im Falle der Referenzimplementierung müssen daher alle Klassen, die Objekte ausprägen, welche
persistiert werden sollen, mit dem Werkzeug entsprechend nachbearbeitet werden. Der notwendige Aufruf
hat folgende Struktur:
java com.sun.jdori.enhancer.Main -d enhanced de/jeckle/jdotest/Employee.class de/jeckle/jdotest/Employee.jdo.
Dieser Aufruf reichert die bereits übersetzte Klasse Emplyoee innerhalb der Pakethierarchie
de.jeckle.jdotest um Persistenzdaten an und legt das Ergebnis innerhalb des
Dateisystemkatalogs de/jeckle/jdotest ab. Zur Anreicherung wird die Konfigurationsdatei
Employee.jdo herangezogen, die im selben Pfad abgelegt ist wie die Quellcodedatei.
Alternativ zu diesem Ansatz steht auch die Möglichkeit zur Verfügung die benötigten Anweisungen bereits im Quellcode vorzusehen um so dasselbe Resultat zu erzielen, welches durch den Anreicherungsprozeß erzeugt wird. Diese Vorgehensweise hat jedoch wegen der damit verbundenen Aufwände kaum praktische Bedeutung erlangt und wird daher im folgenden nicht vertieft betrachtet.
Die Beispiele dieses Kapitels basieren auf der kostenfrei verfübaren JDO-Referenzimplementierung von SUN.
Diese beschränkt zwar die unterstützten Persistenzmechanismen auf ausschließlich dateibasierte Speicherung und
sieht keine Ablage in Datenbankmanagmenetsystemen vor.
Konzeptionell und programmierseitig ist die Interaktion mit dieser Implementierung jedoch identisch zu
kommerziell verfügbaren Lösungen und können daher ohne weiteres auf diese und damit beliebige
Persistenzdienstleister übertragen werden.
Die Abbildung der in der Programmiersprache formulierten Interaktionen auf den konkreten physischen
Persistenzdienstleister erfolgt sinnvollerweise an einer für alle JDO-nutzenden Applikationen
zugänglichen Stelle im Rahmen einer Property-Datei.
Die Inhalte dieser Datei unterscheiden naturgemäß bei den verschiedenen JDO-Herstellen und inhärent
mit dem gewählten Persistenztyp. So benötigt die dateibasierte Objektablage offenkundig andere
Festlegungen als der Zugriff auf ein relationales Datenbankmanagementsystem.
Beispiel 76 zeigt die notwendigen Einstellung
zur Konfiguration der dateibasierten Speicherung mit der SUN-Referenzimplementierung. Dort wird
mit der PersistenceManagerFactoryClass diejenige Klasse innerhalb des JDO-Rahmenwerkes
benannt, welche dem Programmierer die Persistenzdienste zur Verfügung stellt. ConnectionURL
bildet das Bindeglied der Abbildung auf die physische Datei und benennt daher den Speicherort aller
persistierten Objekte. Die zusätzlichen Angaben dienen der Authentisierung und Zugriffssteuerung beim Zugriff
auf die erstellte Datei.
| Beispiel 76: Konfiguration einer JDO-Implementierung |
Download des Beispiels |
![]()
Die JDO-API ist im Rahmen des Java Community Prozesses als Java-Schnittstellensammlung nebst zugehöriger
Semantikdefinition spezifiziert. Die Implementierung der Schnittstellen erfolgt durch den Anbieter
der jeweiligen JDO-Implementierung und erfolgt auf den jeweiligen Persistenztyp abgestimmt.
Abbildung 7 zeigt die grundlegenden Schnittstellen der JDO-API
sowie die sie anbietenden Klassen der Referenzimplementierung.

Die Schnittstelle PersistenceCapable bildet das Rückgrat der gesamten Persistenzbemühungen.
Jede Klasse, deren Speicherung durch JDO verwaltet werden soll (in Beispiel die Klasse Employee)
muß diese Schnittstelle zwingend implementieren.
Typischerweise erfolgt diese Implementierung jedoch nicht direkt durch den Applikationsprogrammierer, sondern
wird im Rahmen der Bytecodeanreicherung nachträglich hinzugefügt.
Zur Interaktion mit Klassen, deren Implementierung der in PersistenceCapable deklarierten
Methoden erst nach dem initialen Übersetzungsvorgang hinzugefügt werden kann der JDO-Anbieter die
Hilfsklasse JDOHelper anbieten. Diese definiert verschiedene, ausschließlich als statisch deklarierte,
Methoden um mit Objekten von Klassen zu operieren, als würden diese die Schnittstelle
PersistenceCapable umsetzen, ohne deren Klassen zur tatsächlichen Schnittstellenimplementierung
verpflichten.
Damit stellt JDOHelper die unabdingbare Voraussetzung zur Anwendungsentwicklung
unter Verwendung der Bytecodeanreicherung dar, da diese erst nach dem Übersetzungsvorgang
Implementierungen derjenigen Schnittstellen hinzufügt, die bereits im Code verwendeten wurden.
Ferner bietet die Klasse die Möglichkeit den aktuellen Persistenzzustand eines
JDO-verwalteten Objektes auszulesen.
Zur Erzeugung von Objekten, die später den Zugriff auf das physische Speichermedium
regeln dienen die Umsetzungen der Schnittstelle PersistenceManagerFactory. Sie erlaubt die
Parametrisierung und Verwaltung der Verbindung zum Persistenzmedium. Bereitgestellt wird die
Implementierung, im Falle der Referenzimplementierung, durch die Klasse
com.sun.jdori.fostore.FOStorePMF.
Die Verbindung zwischen Schnittstelle und tatsächlicher Implementierung wird im Rahmen der
in Beispiel 76 gezeigten JDO-Konfiguration definiert. Zum Wechsel
des Persistenzanbieters -- etwa von der durch die Referenzimplementierung angebotenen dateibasierten
Speicherung auf eine datenbankgestützte Umsetzung -- genügt im die Abänderung dieses Eintrages in der
Konfigurationsdatei.
Klassen, welche die Schnittstelle PersistenceManagerFactory implementieren, werden
zur Erzeugung von sog. PersistenceMangern herangezogen. Umsetzungen dieser Schnittstelle
(im Falle der Referenzimplementierung ist dies die Klasse
com.sun.jdori.common.PersistenceManagerWrapper) dienen zur Interaktion mit der Persistenzveraltung
innerhalb der JDO nutzenden Applikation. Alle Änderungen des Zustandes eines persistenten Objektes
werden durch diese Klasse abgewickelt.
JDO wickelt sämtliche Zugriffe auf die persistenten Daten transaktionsgesichert ab. Dieser Mechanismus
wird auf der abstrakten Ebene der API durch die Schnittstelle Transaction definiert und steht
daher für alle Persistenzanbieter gleichermaßen zur Verfügung.
Die Schnittstelle definiert alle zur Transaktionssteuerung benötigten Operationen (darunter begin,
commit und rollback) an.
Im Falle der Referenzimplementierung wird die Schnittstelle durch die Klasse
com.sun.jdori.common.query.QueryImpl umgesetzt.
Zusätzlich sieht JDO eine abstrakte Möglichkeit zur Formulierung von Anfragen auf den verwalteten
Datenbestand vor. Die notwendige Schnittstelle wird durch Query bereitgestellt.
Hierfür müssen die verschiedenen JDO-Implementierungen ebenfalls eigene Umsetzungen vorsehen.
Zur Erzeugung eines Objektspeichers ist bereits die Nutzung der Implementierungen der
zentralen JDO-Schnittstellen sowie die der Transaktionssteuerung notwendig.
Das Beispiel zeigt die notwendigen Schritte zur Erzeugung eines persistenten Objektspeichers.
Zunächst lädt das Beispiel die Konfiguration aus der Eigenschaftsdatei des Beispiels 76. Anschließend wird durch die mit true belegte
implementierungsspezifische Eigenschaft com.sun.jdori.option.ConnectionCreate
festgelegt, daß im Rahmen des Verbindungsaufbaus auch notwendigenfalls der Objektspeicher neu erzeugt wird.
Die Interaktion mit JDO beginnt durch die Erzeugung eines PersistenceManagerFactory konformen
Objektes durch den Aufruf getPersistenceManagerFactory unter Auswertung der zuvor geladenen und
ergänzten Konfigurationseigenschaften.
Nach der Erzeugung des Factory-Objektes kann mittels diesem durch den Aufruf
getPersistenceManager ein Objekt erzeugt werden, das die
Interaktion mit dem Objektspeicher bereitstellt. Durch die Ermittlung des Persistenzmanagers
wird gleichzeitig eine Verbindung zum Persistenzanbieter aufgebaut.
Ausgehend von diesem Verwaltungsobjekt kann durch Definition einer „leeren“ Transaktion --
d.h. einer Transaktion, die jenseits der Erzeugung des transaktionalen Kontexts und seines Abschlusses
mit committ, keine Operationen definiert -- der Objektspeicher erzeugt werden.
Den Abschluß der Interaktion mit dem Objektspeicher bildet die Beendigung der Verbindung durch
Ausführung der Methode close des Verbindungsobjektes.
| Beispiel 77: Erzeugung eines persistenten Objektspeichers |
Download des Beispiels |
![]()
Grundsätzlich können Ausprägungen jeder beliebigen Javaklasse durch JDO persistiert werden, solange diese
Klassen die Schnittstelle PersistentCapable explizit im Quellcode implementieren oder die
benötigte Implementierung im Rahmen der Bytecodeanreicherung hinzugefügt wird.
Zur Steuerung des konkreten Persistenzverhaltens wird eine zusätzliche Konfigurationsdatei benötigt.
Diese bedient sich der bekannten XML-Sytnax und definiert das Persistenzverhalten der durch JDO
zu verwaltenden Klasseninstanzen näher.
Beispiel 78 zeigt zunächst die zu persistierende
Klasse Employee.
| Beispiel 78: Zu persistierende Javaklasse |
Download des Beispiels |
![]()
Die Nutzung JDO-gestützter Objektpersistenz impliziert keinerlei Modifikationen
oder Ergänzungen am Quellcode. Ebenso sind keinerlei Umsetzungskonventionen einzuhalten, die
im Beispiel definierten get- und set-Methoden dienen lediglich der vereinfachten
Interaktion.
Das Beispiel 79 illustriert eine
Parameterdatei zur Definition des spezifischen Persistenzverhaltens von Objekten der Klasse
Employee.
| Beispiel 79: Parametrisierung der Objektpersistenz |
Download des Beispiels |
![]()
Die XML-Datei definiert zunächst den Paket- und Klassennamen der zu persistierenden Klasse mittels des
Attributs name der XML-Elemente package und class.
Innerhalb eines class-Elements kann für jedes Attribut der Javaklasse ein mit
field benanntes Element zur näheren Charakterisierung des Speicherungsverhaltens angegeben werden.
Ein solches Element trägt zunächst im Attribut name den klassenweit eindeutigen Namen
des Attributs und erlaubt die Festlegung des spezifischen Persistenzverhaltes mittels der Belegung des
Attributs persistence-modifier. Ist dieses mit dem Wert persistent versehen, so
wird ein so gekennzeichnetes Attribut durch JDO im Datenspeicher persistiert. Trägt das XML-Attribut den
Wert none, so wird das Javaattribut bei der Abbildung in den JDO-Datenspeicher ignoriert.
Zusätzlich besteht die Möglichkeit durch die Belegung mit transactional die Zwischenspeicherung
des Attributwertes während der Abarbeitung einer Transaktion zu erzwingen, um so eine spätere Wiederherstellung
(nach einem Aufruf von rollback) zu gewährleisten. Jedoch werden Felder, die so gekennzeichnet sind,
nicht persistent in den Datenspeicher übernommen, sondern stehen nur während der Programmlaufzeit zur
Verfügung.
Fehlt diese Spezifikation zu einem Attribut in der XML-Datei, so wird vorgabegemäß die Belegung mit
persistent angenommen, sofern es in der beherbergenden Javaklasse nicht als static,
transient oder final ausgewiesen ist.
Attribute vom Typ einer Sammlungsklasse, wie sie durch die
Collection API
definiert werden müssen
zusätzlich mit einem collection-Element, welches innerhalb des field-Elements
plaziert ist, charakterisiert. Das collection-Element spezifiziert durch sein
Attribut element-type den Typ der Elemente in der Sammlung festlegt. Zusätzlich kann durch
das Boole'sche-Attribut embedded-element gesteuert werden, ob die Inhalte des Sammlungsobjektes
zusammen mit dem die Sammlung referenzierenden Objekt persistiert werden sollen.
Das Beispiel legt für alle Attribute der Klasse Employee ihre persistente Speicherung fest
(Belegung des XML-Attributs persistence-modifier für alle Attribute persistent);
ebenso wird die in Objekten des Typs Employee, unter dem Namen projects, enthaltene
Sammlungsinstanz einschließlich ihrer Inhaltsobjekte des Standard-API-Typs String dauerhaft
abgespeichert.
Über diese Festlegungen hinaus gestattet das Parametrisierungsformat die Festlegung spezifischer
Konsistenzsemantik in Gestalt der Auszeichnung eines Primärschlüssels. Dieses aus dem relationalen
Modell bekannte Konstrukt fordert die Eindeutigkeit eines Attributs oder einer Kombination von Attributen
über die gesamte Menge der Ausprägungen eines Typs.
Durch die Unterstützung als abstraktes JDO-Konstrukt steht dieses Konzept zur Konsistenzsicherung auch
für Applikationen zur Verfügung, die sich nicht relationaler Datenbanken als Persistenzdienstleister
bedienen.
Zur Realisierung des Primärschlüsselkonzeptes ist das als Schlüssel zu interpretierende Attribut
in der XML-Beschreibung zusätzlich mit dem XML-Attribut primary-key zu versehen, welches
den Wert true tragen muß. Zusätzlich ist innerhalb des Elements class diejenige
Klasse anzugeben, welche das Attribut beherbergt, das als Schlüssel herangezogen werden soll.
80 zeigt die notwendigen Modifikationen an der
Parameterdatei des Beispiels 79 um das Java-Attribut
name als Primärschlüssel festzulegen. Die primärschlüsselanbietende Klasse ist in diesem
Falle die Klasse Employee selbst, weshalb sich ihr Name auch im XML-Attribut
objectid-class des class-Elements findet.
| Beispiel 80: Parametrisierung der Objektpersistenz und Definition eines Primärschlüssels |
Download des Beispiels |
![]()
Konsequenz der Einführung eines Primärschlüsselattributs ist die Überwachung der damit einhergehenden Konsistenzbedingungen durch das JDO-Laufzeitsystem. So führen Versuche zwei Objekte, die sich in der Belegung des als Primärschlüssel definierten Attributs nicht unterscheiden ebenso zu Fehlern wie schreibende Zugriffe auf dergestalt ausgezeichnete Attribute.
Voraussetzung der Persistenzverwaltung eines Objektes durch JDO ist die entsprechende Modifikation
dieses Objektes, konkret die Implementierung der in PersistenceCapable festgelegten
Operationen durch Methoden der objekterzeugenden Klasse.
Dies wird jedoch nur in Ausnahmefällen durch den Applikationsprogrammierer direkt vorgenommen. Häufigste
Eionsatzform der JDO-API ist die Anwendung der Bytecodeanreicherung, welche die Implementierung der notwendigen
Funktionalität automatisiert vornimmt und diese nach dem eigentlichen Übersetzungsvorgang in den erstellten
Bytecode einbringt.
Abbildung 8 zeigt die daher notwendigen zwei Übersetzungsschritte.

Die Illustration versammelt die zur Erzeugung und Anreicherung des Bytecodes der per JDO zu persistierenden
Klasse Employee aus Beispiel 78. Zur Anreicherung des
Bytecodes werden die in Beispiel 79 getroffenen Parametrisierungen
herangezogen.
Zunächst wird der im Paket de.jeckle.jdotest abgelegte Quellcode Employee.java
mit dem Javacompiler in (gewöhnlichen) Bytecode übersetzt.
Anschließend wird dieser vermöge des in der JDO-Referenzimplementierung vorhandenen Werkzeuges
Enhancer um die Implementierung der in der Schnittstelle PersistenceCapable
definierten Operationen angereichert. Hierzu wird dem Enhancer (bereitgestellt durch die Klasse
com.sun.jdori.enhancer.Main zunächst das Zielverzeichnis des zu erzeugenden
Bytecodes mittels des Parameters d übergeben. Naheliegernderweise kann der aus dem
ursprünglichen Bytecode durch Erweiterung erzeugte nicht die Ausgangsdatei überschreiben, daher
wird der angereicherte Bytecode im Verzeichnis enhanced gespeichert. Zusätzlich
ist dem Enhancer der vollqualifizierte Name der anzureichernden Klasse sowie der vollqualifizierte
Pfad der Parameterdatei (im Beispiel: de/jeckle/jdotest/Employee.jdo) zu übergeben.
Diese muß im Falle des Einsatzes der Referenzimplementierung zwingend die Extension jdo besitzen.
Im Zusammenspiel zwischen transienter Objektverwaltung durch die Applikation im Hauptspeicher
und persistenter Objektverwaltung durch JDO im Hintergrundspeicher werden verschiedene Status eines
verwalteten Objekts unterschieden zwischen denen explizite Übergänge durch API-Aufrufe vorgegeben sind bzw.
implizit durch Operationen auf den involvierten Objekten bestehen.
Im Detail werden folgende Status unterschieden:
transient gekennzeichnet sind.commit noch rollback abgeschlossenen) Transaktion erzeugt wurden.commit bestätigt wurden.commit dauerhaft gespeichert wurden und auf die noch kein Zugriff (weder lesend
noch schreibend) erfolgte.makeDirty manuell in diesen
Zustand versetzt werden.refresh werden die Inhalte von Haupt- und Hintergrundspeicher
synchronsiert, d.h. Inhalte des Hintergrundspeichers werden in den Hauptpeicher übernommen.Abbildung 9 zeigt die verschiedenen JDO-Status sowie die Ereignisse, die zu Zustandsübergängen führen, in der Übersicht.

Zur Speicherung von Objekten, deren Klassen durch den Bytecodeanreicherungsprozeß nachbearbeitet wurden,
bietet die JDO-API die Aufrufe makePersistent und makePersistentAll an. Diese
werden innerhalb eines Transaktionskontextes als Methoden eines PersistenceManager-Objekte
ausgeführt.
Beispiel 81 zeigt die Speicherung von drei Objekten der
Klasse Emplyoee, deren übersetzter Bytecode durch Anreicherung zur JDO-Kompatibilität
modifiziert wurde.
Zunächst wird mit empCol vom Standardtyp Vector eine Sammlungsobjekt zur
Aufnahme von Objektreferenzen definiert. Dieser Objektsammlung werden die Referenzen auf die erzeugten
Emplyoee-Objekte (emp1, emp2 und emp3) hinzugefügt.
Als Voraussetzung der Interaktion mit dem Objektspeicher muß zunächst eine Transaktion eröffnet werden.
Hierzu muß zunächst durch Aufruf der Methode currentTransaction die der
PersistenceManager-Instanz zugeordnete Transaktion ermittelt werden. Ausgehend vom
gelieferten Ergebnisobjekt kann durch Ausführung der Methode begin eine neuer
Transaktionskontext eröffnet werden.
Der Aufruf von makePersistentAll persistiert bei Übergabe der Objektsammlung alle in der
Sammlung referenzierten Objekte. Alternativ können Einzelobjekte durch die Methode makePersistent
in den Zustand dauerhafter Speicherung überführt werden.
Zur Übernahme in den Hintergrundspeicher muß der Transaktionskontext durch Aufruf von commit
abgeschlossen werden. Der Aufruf von rollback würde stattdessen alle in der Transaktion
vorgenommenen Änderungen verwerfen und auf den im Hintergrundspeicher verwalteten Datenzustand zurückgesetzt.
| Beispiel 81: Speicherung von Objekten mit JDO |
Download des Beispiels |
![]()
Würde wie im Beispiel 80 gezeigt das Attribut name
der Klasse Employee als Primärschlüssel definiert sein, so würde der Persistierungsversuch
des durch emp3 referenzierten Objektes einen Laufzeitfehler liefern, da mit emp2
bereits ein Objekt mit derselben Belegung des Attributs name persistiert wurde.
Treten während der Interaktion mit dem Persistenzspeicher, d.h. während eines noch nicht mit
commit abgeschlossenen Transaktionskontextes Fehler auf, so können durch Aufruf
der Methode rollback alle im aktuellen Kontext vorgenommen Änderungen auf den Stand
vor Beginn der Transaktion zurückgesetzt werden.
Beispiel 82 zeigt das Verhalten der Methode
rollback am Beispiel. Durch die Schreiboperation innerhalb der geöffneten Transaktion
wird der Wert des Attributs name zwar verändert, jedoch durch Aufruf von rollback
wieder auf den ursprünglichen Wert zurückgesetzt.
| Beispiel 82: Transaktionen mit JDO |
Download des Beispiels |
![]()
Die Ausführung des Beispiels liefert folgende Ausgabe:Employee named Marta Mayer works in department null
works in projects:
Martha gets married and changes her name
Employee named Marta Smith works in department null
works in projects:
Suppose and error happens now ...
Rolling back
Employee named Marta Mayer works in department null
works in projects:
Ist in bestimmten Anwendungsfällen die Arbeit ohne Transaktionsschutz -- und damit ohne
die Möglichkeit der expliziten Rücksetzung von Änderungen mittels rollback oder der
impliziten Rücksetzung nach einem Systemausfall -- gewünscht, so kann dies durch Aktivierung der
Schreibfunktionalität ohne Transaktionsschutz erreicht werden.
Hierzu muß de Methode setNontransactionalWrite mit dem Übergabeparameter true
für eine Transaktion aufgerufen werden.
Das nachfolgende Beispiel zeigt als Modifikation von Beispiel 81
die persistente Übernahme einer Wertänderung ohne Transaktionsschutz.
| Beispiel 83: Schreiboperation ohne Transaktionsschutz |
Download des Beispiels |
![]()
Zugriffe auf alle im Hintergrundspeicher verwalteten Objekte werden ebenfalls einheitlich durch
Methoden der Implementierung der Schnittstelle PersistenceManager abgewickelt. Zur
Traversierung des vollständigen Bestandes aller Instanzen einer Klasse bietet diese Schnittstelle
die Operation getExtent an. Sie liefert alle Elemente der Extension (d.h. der Gesamtheit
von Ausprägungen) einer gegebenen Klasse.
Beispiel 84 zeigt die Verwendung der Methode. Als Parameter
wird diejenige Klasse übergeben, deren Ausprägungen zu ermitteln sind. Zusätzlich kann durch einen
Boole'schen Schalter gesteuert werden, ob auch Subklassen der übergebenen Klasse retourniert werden sollen.
Der Aufruf liefert eine Sammlung von Objekten des Typs, welcher der Methode getExtent
übergeben wurde.
| Beispiel 84: Traversierung des Objektbestandes |
Download des Beispiels |
![]()
Als mächtige Alternative zur manuellen Traviersierung einer Objektextension spezifiziert JDO
die Verwendung einer eigenen Anfragesprache auf Basis des Standards der Object Query Language (OQL)
der Object Database Management Group (ODMG).
Diese -- als JDO Object Query Language (JDOQL) bezeichnete -- Anfragesprache ist direkt in die
JDO-API integriert und wird über verschiedene Einzelmethoden genutzt. Aus diesem Grunde sind JDOQL-Anfragen
nicht direkt mit den konsizsen SQL- oder OQL-Anfragen vergleichbar.
Beispiel 85 zeigt die Einbettung der Anfragesprache in die JDO-API.
| Beispiel 85: Anfrage auf den persistenten Objektbestand mittels OQL |
Download des Beispiels |
![]()
Das Beispiel illustriert eine Anfrage, die alle Employee-Objekte liefert, deren
department-Attribut mit dem Wert B042 belegt ist und liefert die
nach dem Inhalt des Attributes name in aufsteigender Reihenfolge sortiert.
Hierzu wird zunächst die vollständige Extension der Klasse Employee ermittelt. Allerdings
Extrahiert dieser Aufruf noch keine Werte aus dem persistenten Objektspeicher, sondern schafft nur
die Grundlagen einer späteren manuellen Traversierung oder der Anfrage via JDOQL.
Zur Vorbereitung der tatsächlichen physischen Anfrage wird zunächst eine Zeichenkette geeignet
belegt, um als Filterausdruck dienen zu können, der auf die vollständige Extension angewandt wird.
Im Beispiel ist dieser Filterausdruck mit department == \"B042\" belegt. Aus Gründen
der Zeichenkettenverarbeitung in Java muß hierzu der notwendige Einschluß des zu suchenden Wertes
in Anführungszeichen geeignet maskiert werden.
Nach diesen Vorbereitungsschritten kann durch den Aufruf der durch das PersistenceManager-kompatible
Objekt bereitgestellten Methode newQuery ein neues Anfrageobjekt (vom Typ Query)
erzeugt werden.
Dieses Objekt erlaubt nach der gezeigten Festlegung des Anfrageumfanges die Parametrisierung der Anfrage.
Das Beispiel illustriert dies am Aufruf der Methode setOrdering, die es erlaubt eine
bestimmte Sortierreihenfolge der gelieferten Ergebnisse vorzugeben.
Zusätzlich kann durch die optionale Ausführung der Methode compile eine Prüfung der zusammengestellten
Anfrage erfolgen, die zusätzlich auch interne implementierungsspezifische Optimierungen vornehmen kann.
Abschließend erfolgt die Ausführung der Anfrage durch Aufruf der Methode execute, welche die
Anfrageergebnisse konform zur Standardschnittstelle Collection
zurückliefert.
Zur Entfernung eines Objektes aus dem Objektspeicher stellt die Schnittstelle
PersistenceManager die Methode deletePersistent zur Verfügung, welche
ein einzelnes hauptspeicherresidentes Objekt aus dem persistenten Speicher löscht, bzw.
mit deletePersistentAll eine Möglichkeit alle durch eine Sammlung referenzierten
Objekte zu entfernen.
Da es sich hierbei um einen schreibenden Zugriff handelt, muß dieser in einen Transaktionskontext
eingebettet werden oder explizit transaktionslos durchgeführt werden wie in Beispiel 83 gezeigt.
Beispiel 86 zeigt die Löschung unter Verwendung eines
Transaktionskontextes.
| Beispiel 86: Löschen eines Objektes aus dem persistenten Objektbestand |
Download des Beispiels |
![]()
Der JDO-Ansatz tritt mit dem Versprechen auf vollständig sowohl unabhängig vom verwendeten
Persistenzmedium (etwa: Datenbank, Dateisystem, etc.) als auch der eingesetzten JDO-Implementierung zu sein.
Diese Zielsetzung wird nachfolgend auf Basis des im vorhergehenden diskutierten Employee-Beispiels
untersucht. Hierzu wird die frei verfügbare JDO-Implementierung TJDO eingesetzt, welche verschiedene
Datenbankmanagementsysteme zur Speicherung der Javaobjekte heranziehen kann. Im Beispiel wird das
DBMS MySQL Persistierung der Applikationsobjekte genutzt.
Zur Portierung der bestehenden Applikation ist lediglich die Anpassung der JDO-Eigenschaften
(Property-Datei) vorzunehmen, um den neuen Persistenzdienstleister sowie die verschiedenen DBMS-Spezifika
zu berücksichtigen.
Beispiel 87 zeigt die neuen Inhalte.
| Beispiel 87: Konfiguration der JDO-Implementierung TJDO |
Download des Beispiels |
![]()
Zunächst werden die bereits in der Konfiguration der Referenzimplementierung durch Beispiel
76 genutzten Eigenschaften zur Identifikation
derjenigen Klasse, welche die JDO-Schnittstelle PersistenceManagerFactory implementiert sowie
zur Festlegung der Verbindungs-URL und des zu verwendenden Benutzernamens uns Passwortes an die neuen
Gegebenheiten adaptiert. Konkret wird die durch TJDO bereitgestellte Klasse
com.triactive.jdo.PersistenceManagerFactoryImpl als PersistenceManagerFactory
konforme Implementierung sowie die Identifikation der zu verwendenden Datenbank nebst Benutzername
und Anmeldekennwort bekanntgegeben.
Zusätzlich wird mit com.triactive.jdo.autoCreateTables eine implementierungsspezifische
Eigenschaft mit true belegt, die TJDO veranlaßt im Bedarfsfalle benötigte Tabellenstrukturen
automatisiert zu erzeugen.
Zusätzlich erfordert die verwendete JDO-Implementierung die Adaption der im Rahmen des Bytecodeanreicherungsprozesses herangezogenen Konfigurationsdatei (Beispiel 88). Auf diesem Wege wird dem Programmierer die Möglichkeit eröffnet die Abbildung auf relationale Tabellenstrukturen beeinflussen. In der Konsequenz erfordert der Wechsel der JDO-Implementierung die Wiederholung des Anreicherungslaufes für den Bytecode der zu persistierenden Klassen.
| Beispiel 88: Parametrisierung der Objektpersistenz |
Download des Beispiels |
![]()
Weitere Änderungen an den zu persistierenden Klassen oder den mit deren Objekten operierenden Applikationen ist nicht notwendig, alle Zugriffe werden nach den oben beschriebenen Änderungen transparent und ohne Neuübersetzung datenbankbasiert abgewickelt.
Abschließend seien die charakteristischen Eigenschaften der drei diskutierten Persistenzansätze JDBC, EJB und JDO kurz vergleichend nebeneinandergestellt.
|
| ||||||||||||||||||||||||||||||||||||
Die Tabelle zeigt klar, daß alle drei Persistenzmechanismen grundlegende Eigenschaften
teilen, sich jedoch auch in zentralen Charakteristika unterscheiden.
Während sowohl JDBC als auch EJBs die direkte Verwendung von SQL-Anfragen gestatten bietet
JDO mit JDOQL eine eigenständige Anfragesprache, die direkt in die Sprach-API eingebettet ist.
Für EJBs existiert neben den in Kapitel 1.2 gezeigten Mechanismen auch die Möglichkeit der
Verwendung der EJB-spezifischen Anfragesprache EJBQL, die jedoch hier nicht betrachtet wurde.
Hinsichtlich der jeweils unterstützten Hintergrundspeicherarchitekturen zur Realisierung der Persistenz
treten jedoch deutliche Unterschiede zu Tage. So ist der Einsatz der JDBC-API auf relationale Datenquellen,
bzw. Datenquellen die eine relationale Sicht anbieten, beschränkt. Innerhalb der EJB-Architektur können
hingegen neben den -- hier diskutierten JDBC-basierten Mechanismen -- auch die Dienste einer
Integrationsmiddleware zu Speicherung herangezogen werden und so eine gewisse Unabhängigkeit vom
physischen Speichermedium erreicht werden. Einzig JDO bietet durch seine starke Abstraktion
die Möglichkeit beliebige Persistenzdienstleister zu nutzen.
Zur effizienten Abwicklung dieses speicherformunabhängigen Zugriffs etabliert JDO notwendigerweise
eine stark abstrahierte API, deren Funktionen keinerlei Rückschlüsse auf den verwendeten Persistenzmechanismus
zulassen. Für EJB läßt sich dies prinzipiell auch realisieren, allerdings müssen für die Variante
der bean managed persistence innerhalb der Entity Bean die Interaktionen mit dem Persistenzdienstleister
expliziert werden, beispielsweise durch JDBC. Daher verhält sich dieser Ansatz intern ähnlich zur direkten
Verwendung der JDBC-API, die inhärent jeden angebundenen Persistenzmechanismus mit relationaler
Zugriffssemantik belegt.
Aufgrund des vorherrschenden relationalen Speicherparadigmas kann die Einbindung bestehender Tabellenstrukturen
in den API-Mechanismus gewünscht sein. Dies ist ausschließlich mit Ansätzen möglich, welche die
anwenderdefinierte Strukturierung der Zugriffsausdrücke -- etwa durch die Verwendung von SQL -- gestatten. Dies
ist ausschließlich für JDBC und EJB (sofern bean managed persistence verwendet wird) möglich; JDO sieht
dies generell nicht vor.

Abschließend lassen sich die vorgestellten Schnittstellen hinsichtlich ihrer Möglichkeiten zur
Bereitstellung eines transparenten Zugriffs auf den Hintergrundspeicher und der manuellen Eingriffsmöglichkeiten
zur Kontrolle der Persistenz durch den Programmierer kategorisieren.
Prinzipiell läßt sich festhalten, daß diese Eigenschaftstypen konkurrierende Zielsetzungen darstellen.
So bietet JDBC zweifelsohne die größten Möglichkeiten zum steuernden Eingriff durch den Programmierer, wobei
dieser Ansatz in der Interaktion auch die größte Menge Wissen des Programmierers über die etablierten
Speicherstrukturen erfordert. Daher realisiert JDBC generell die geringste Transparenz im Zugriff auf
den Objektspeicher.
Auf der anderen Seite realisiert JDO die größtmögliche Transparenz im Objektzugriff, wobei dieser Freiheitsgrad
zu generell zu Lasten der Eingriffsmöglichkeiten durch den Programmierer umgesetzt werden.
| Web-Referenzen 10: Weiterführende Links |
![]()
4
FunktionsintegrationDer Austausch von Daten zwischen Rechnersystem ist so alt wie die Vernetzung zunächst separierter Rechnersysteme selbst. Während die Abwicklung des Austausches von Nachrichten zwischen den vernetzen Systemen anfänglich individuell für jede Plattform, d.h. spezifisch für jede Programmiersprache, das zugrundeliegende Betriebssystem und die zur physischen Datenübertragung eingesetzte Netzwerkinfrastruktur, gelöst werden mußte bildeten sich zur Steigerung der Interoperabilität und Portabilität bei gleichzeitiger Komplexitätsreduktion im Laufe der Zeit eigenständige generische Kommunikationskomonenten heraus, die zum Versand beliebiger Nachrichten eingesetzt werden können.
Ziel dieser -- als message-oriented Middleware bezeichneten -- Softwareinfrastruktur ist die deutliche Komplexitätsreduktion bei der Erstellung vernetzt kommunizierender Applikationen durch Einführung einer standardisierten, plattformübergreifend verfügbaren Lösung, welche dem Applikationsprogrammierer eine abstrahierte und vergleichsweise simple Programmierschnittstelle anbietet.
Zentrales Architekturmerkmal nachrichtenorientierter Middlewarekomponenten ist die gleichzeitige Betrachtung von ausschließlich zwei kommunizierenden Partnern, die als client und server bezeichnet werden, die in asynchroner Weise miteinander Nachrichten austauschen.
Im Rahmen der abgewickelten Interaktion versendet der Client dabei beliebige Daten an den Server, oder empängt diese von ihm. Der Server ist dabei die Message-orientierte Middleware, welche Sender und tatsächlichen Empfänger physische voneinander entkoppelt.
Die Begriffsbildung asynchron bezeichnet hierbei einen Kommunikationsstil, der die beteiligten Kommunikationspartner weder zeitlich noch prozedural koppelt.
Das Verhältnis zwischen Clients und Server, sowie das Zusammenspiel der verschiedenen physischen Architekturelemente ist in Abbildung 11 dargestellt.
Die Abbildung zeigt JMS-API, welche seitens der beteiligten Clients den Zugriff auf die systemspezifische Schnittstelle der verwendeten Middlware-Implementierung kapselt. Durch Pfeile ist der Ablauf eines Nachrichtenversandes von Applikation1 an Applikation2 dargestellt. Zunächst wird die Nachricht, durch Nutzung der involvierten Schnittstellen, an das MOM-System übertragen, welches es anschließend an den durch Applikation2 vorgehaltenen Client ausliefert bzw. diesem zur Abholung bereitstellt.
Entlang des Pfades, welchen eine versandte Nachricht zurücklegt können auch mehrere MOM-System hintereinandergeschaltet auftreten. Diese agieren dann als Client bezüglich der in der Nachrichtenkette angrenzenden MOM-Systeme.

Zusätzlich zeigt die Abbildung die typischerweise in MOM-Systemen präsente Datenbankkomponente, welche zur Sicherstellung der verläßlichen Nachrichtenübertragung dient. Im Normalfall wird dem versendenden Client erst die korrekte Übernahme der Nachricht in das MOM-System signalisiert, wenn sie persistent in der Datenbank abgelegt wurde. Im selben Sinne wird eine datenbankresidente Nachricht erst dann dauerhaft gelöscht, wenn sie dem Zielclient korrekt übermittelt wurde.
Durch diese Mimik entsteht, auch im Falle des Hintereinanderschaltens einzelner MOM-Systeme, eine verlässliche Nachrichtenstrecke, welche den Versand der Nachricht auch im Falle des Ausfalls einzelner Streckenabschnitte (d.h. MOM-Systeme) sicherstellen kann.
Abbildung Abbildung 12 zeigt, als Ausschnitt der Untersuchungen des W3C zu Web-Service-Architekturen, eine aktuelle Bestandsaufnahme der Komponenten einer Nachrichten-orientierten Architektur:
| Tabelle 25: Elemente einer Nachrichten-orientierten-Middleware-Architektur | |||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||
![]()

Innerhalb der Java-J2EE-API bietet die Programmierschnittstelle Java Message Service (JMS) einfachen Zugriff auf die Prinzipien Nachrichten-orientierter Kommunikation, die durch beliebige Implementierungen Nachrichten-orientierter-Middleware-Systeme zur Verfügung gestellt werden können.
Für die nachfolgenden Codebeispiele wurde die Implementierung der Sun Java Message Queue, welche als Bestandteil der J2EE-Referenzimplementierung ausgeliefert wird, genutzt. Die Beispiele sollten sich jedoch mit geringem Anpassungsaufwand auch auf andere Middlwaresysteme übertragen lassen.
TODO(Hier fehlt noch eine textuelle Erklärung)
Die JMS-API besteht aus einer Reihe von Java-Schnittstellenspezifikationen, die durch das verwendete Middlewaresystem implementiert werden.
Nachfolgend ist eine Übersicht der zentralen Schnittstellen und der durch sie angebotenen Funktionalität gegeben.
| Tabelle 26: Schnittstellen der JMS-API | |||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
![]()
Das Beispiel 89 zeigt die notwendigen Schritt zur Implementierung eines Clients zum synchronen Nachrichtenversand.
Zunächst ermitteln die Zeilen 29 bis 53 durch Nutzung des JNDI-Mechanismus die Referenz auf das zur Verbindungserzeugung zum Server benötige Objekt des Typs Connection Factory. Davon ausgehend wird in Zeile 56 ein Connection-Objekt erzeugt, welches die Verbindung zum Server verwaltet.
Der in Zeile 57 erfolgende Aufruf der API-Funktion createSession liefert eine Ausprägung des Typs Session, welches die logische Verbindung zum Server etabliert. Die in Zeile 57 des Beispiels genutzten Übergabeparameter erzeugen eine Session, die nicht transaktionsgestützt (erster Parameter) arbeitet und durch die als zweiten Übergabeparameter spezifierte Konstante AUTO_ACKNOWLEDGE dazu führt, daß die Verbindung (d.h. das Session-Objekt) den Nachrichtenempfang selbständig bestätigt, sobald der Client seine receive-Methode aufgerufen hat oder die Nachricht aus dem Nachrichtenspeicher entnommen wurde.
Ausgehend von der erzeugten Session erzeugt die Methode createProducer ein Objekt des Typs MessageProducer, welches zum Versand von Nachrichten an einen gegebene Adresse dient.
Zeile 60 erzeugt eine neue Nachricht des Typs TextMessage zum Versand. Dieser wird anschließend, durch die API-Funktion setText, textueller Nachrichteninhalt zugewiesen.
Der tatsächliche Sendevorgang findet (in Zeile 65) durch den Aufruf send statt. Die Implementierung des Beispiels wiederholt diesen Sendevorgang (mit unterschiedlichen Nutzdateninhalten) so oft, wie per Aufrufparameter spezifiziert.
Zum Abschluß der Kommunikation versendet der Client eine Nachricht mit leerem Nutzdateninhalt (sie besteht nur aus verwaltender Headerinformation) an den Server. Diese dient als „Endemarkierung“ des kompletten Sendevorganges.
| Beispiel 89: Versand einer Nachricht |
Download des Beispiels Download der Ergebnisdatei |
![]()
Aufruf des Beispiels 89 mit: j2ee14/bin/appclient -client SProducer.jar jms/Queue queue 5
Beispiel 90 zeigt die Umsetzung eines nachrichtenempfangenden Clients.
Auch er ermittelt zunächst, ebenfalls unter Nutzung von JNDI, die relevanten Umgebungsdaten und erzeugt ausgehend von der ConnectionFactory eine Verbindung (Zeile 55) und eine Session zur Abwicklung des nachrichtenverkehrs.
Zur Kommunikation mit dem Client, welcher im vorhergehenden Beispiel zum Abschicken der Nachrichten diente, muß derjenige Client, der die Nachrichten entgegennimmt, an dieselbe Adresse gebunden werden, die bereits im Client als Nachrichtenendpunkt diente. Entsprechend wird dem Aufruf der JMS-API-Methode createConsumer dieselbe Endpunktidentifikation übergeben, die zuvor für den sendenden Client Verwendung fand. Der Aufruf der genannten Methode erzeugt ein Objekt des Typs Consumer, welches im Anschluß zum Empfang von Nachrichten, die an die übergebene Adresse versandt wurden, genutzt wird.
Die Empfangsbereitschaft seitens des Clients wird durch den Aufruf der Methode start (Zeile 58), die durch das Connection-Objekt bereitgestellt wird, hergestellt.
In Zeile 61 wird die Methode receive zum Empfang serverseitig vorliegender Nachrichten aufgerufen. Diese Methode ist synchron-blockierend, d.h. sie kehrt erst nach Empfang einer Nachricht zurück. Stellt die Middlewarekomponente aktuell keine solche zur Verfügung, so wird der methodenausführende Thread so lange blockiert, bis eine Nachricht vorliegt.
Konnte eine Nachricht empfangen werden, so wird in Zeile 64 durch getText der übermittelte textuelle Inhalt extrahiert.
| Beispiel 90: Empfang einer Nachricht |
Download des Beispiels Download der Ergebnisdatei |
![]()
Aufruf des Beispiels 90 mit: j2ee14/bin/appclient -client SProducer.jar jms/Queue queue 5
TODO(Hier fehlt noch eine textuelle Erklärung)
Aufruf mit: j2ee14/bin/appclient -client PSProducer.jar
| Beispiel 91: Versand einer Nachricht |
Download des Beispiels |
![]()
TODO(Hier fehlt noch eine textuelle Erklärung)
Aufruf mit: j2ee14/bin/appclient -client PSConsumer.jar
| Beispiel 92: Empfang einer Nachricht |
Download des Beispiels |
![]()
Die ursprünglich eigenständig entwickelte JMS-API ist inzwischen in die Java 2 Enterprise Architecture integriert worden. Implementierungen dieser Architektur können daher als MOM-System eingesetzt werden.
Darüber hinaus bildet die JMS-Funktionalität der Basis der Message-driven Beans. Diese Spielart der Entity Beans kann durch Empfang einer per JMS versandten Nachricht angesprochen werden. Voraussetzung hierzu ist die Implementierung der Operation onMessage der Schnittstelle MessageListener sowie die Implementierung der Schnittstelle MessageDrivenBean.
Das nachfolgende Beipiel zeigt die Reforumulierung des Beispiels 92 als Message-driven Bean.
| Beispiel 93: Empfang einer Nachricht durch eine Message-driven Bean |
Download des Beispiels |
![]()
| Web-Referenzen 11: Weiterführende Links |
![]()
Der Java-spezifische Ansatz der Remote Method Invocation (RMI) zielt darauf
einen lokationstransparenten Aufruf innerhalb von (verteilten) Java-Anwendungen zu ermöglichen.
RMI stellt hierbei die Einzelobjekte einer Applikation in den Vordergrund und gestattete den Aufruf von
Methoden in derselben Art und Weise unabhängig davon ob sich das Objekt auf der aufrufenden Maschine selbst
befindet oder an einer entfernten Lokation zur Verfügung steht.
Damit stellt sich RMI in die Tradition des objektorientierten Verteilungsmechanismus CORBA, ohne allerdings
dessen programmiersprachenunabhängige Zielsetzung zu verfolgen. Gleichzeitig wurde das von DCE übernommene
Serialierungsformat für hauptspeicherresidente Inhalte auf die Objektübertragung mittels eines Netzprotkolls
ausgedehnt.
Die Grundprimitive des Ansatzes ist daher der entfernte Methodenaufruf (engl. Remote Procedure Call, RPC)
welcher Kraft der lokalisationstransparenten Abstraktion RMIs dem Programmierer dieselbe Aufrufschnittstelle
für entfernte Methoden bietet, die bereits für die Interaktion mit lokalen Objekten zum Einsatz kommt.
Zusätzlich erweitert RMI bestimmte zunächst lokal angebotene Dienstleistungen, wie etwa automatische Speicherverwaltung
(Garbage Collection) für die verteilte Anwendung mit der Zielsetzung die Verwendung entfernter Objekte
der lokal vorliegender gleichzustellen (Lokalisationstransparenz).
Zusammenfassend formuliert die RMI-Spezifikation daher folgende Ziele:
Integrale Bestandteile des RMI-Ansatzes und direkte Folgerungen der angestrebten Transparenz sind
Architekturbestandteile Stub und Skeleton.
Beide erfüllen symmetrische Aufgabenstellungen und werden mittels eines Dienstprogrammes automatisch
aus dem übersetzten Bytecode des für den entfernten Zugriff anzubietenden Objekts erstellt.
Zur Ausführungszeit wirkt der Stub als Stellvertreter des entfernten Serverobjektes innerhalb der
Adreßumgebung des Clients, analog fungiert der Skeleton als serverseitiger Stellvertreter des
aufrufenden Objekts.
Abbildung 21 zeigt den Ablauf des Aufrufs eines entfernten Objekts mittels RMI. Hierbei spielen die Stub- und die Skeletonkomponente wie folgt zusammen:

Um das entfernte Objekt lokalisieren zu können, ohne daß dem Aufrufer der Server, auf dem dieses verwaltet wird, bekannt sein muß, wird als zusätzliche Architekturkomponente ein Verzeichnisdienst verwendet. Innerhalb dieses Dienstes wird jedes Objekt, auf das der entfernte Zugriff angeboten werden soll, ein eineindeutiger Name und die physische Objektlokation verwaltet.
Unter Berücksichtung des Verzeichnisdiensts ergibt sich daher folgender Interaktionsablauf:

Das Bild zeigt das Objekt s als Instanz der Klasse Server sowie
das auf die darin enthaltene Methode theMethod zugreifenden Client-Objekt.
Zusätzlich ist mit RMI Registry der Verzeichnisdienst zur Verwaltung der zugreifbaren
Objekte dargestellt. Die beiden Objekte Registrator bzw. Deregistrator dienen
zur Ablage (Bindung) des Server-Objektes an einen im Verzeichnisdienst gespeicherten Namen
bzw. der Aufhebung dieser Bindung.
Da die Bindung objektbezogen erfolgt, muß die registrierende Instanz (im Beispiel Registrator)
eine Referenz auf das abzulegende Objekt besitzen. Die Beispielinteraktion unterstellt daher die Erzeugung der
benötigten Server-Instanz durch den Registrator selbst. Dieser bindet das Server-Objekt
unter dem Klarnamen name und legt diese Zuordnung durch Aufruf der Methode bind oder rebind in der Registry ab.
Dort kann danach mittels der Methode lookup,
unter Angabe des Namens eine Referenz auf das gebundene Objekt, erfragt werden. Die Interaktion zeigt diesen
Aufruf durch den Client.
Ausgehend von dieser Referenz kann durch den Client die durch die Server-Schnittstelle publizierte
Methode theMethod aufgerufen werden.
Ferner zeigt der Ablauf die Deregistrierung des Server-Objektes durch das Deregistrator-Objekt
mittels der Methode unbind. Für
diesen Aufruf ist keine Objektreferenz, sondern lediglich der Klarname des Objektes notwendig.
Die Entwicklung einer RMI-basierten Applikation vollzieht sich immer im selben Ablauf der Erstellung
der notwendigen Kompontenten.
Dieser Ablauf ist nachfolgend anhand einer simplen Applikation veranschaulicht:
HelloInterface)HelloServer)HelloClient)rmic)rmiregistry)Die Schnittstelle HelloInterface:
| Beispiel 94: Die Schnittstelle HelloInterface |
Download des Beispiels |
![]()
Die Schnittstelle enthält die Operationen aller Methoden, die
ein Serverobjekt zur Verwendung zur Verfügung stellen soll.
Hierbei sind naturgemäß keine als private oder protected
deklarierten Operationen zugelassen, da auf sie kein Zugriff möglich wäre.
Für jede Operation ist die möglicherweise auftretende Erzeugung einer Ausnahme
des Typs RemoteException
vorzusehen. Dieser Typ kapselt durch Kommunikationsfehler verursachte Ausnahmen.
Zusätzlich ist die gesamte Schnittstelle als Spezialisierung der Standardschnittstelle
Remote zu definieren. Diese Schnittstelle
definiert selbst keine Operationen, sondern dient lediglich zur Kennzeichnung von Schnittstellen, die
entfernt aufrufbare Methoden versammeln.
Die Klasse HelloServer:
| Beispiel 95: Die Klasse HelloServer |
Download des Beispiels |
![]()
Die Klasse enthält neben der Methode der durch die Schnittstelle exponierten Operation sayHello
auch im Konstruktor die Registrierung innerhalb des RMI-Verzeichnisdienstes. Dieser ist jedoch, ebenso so
wie alle anderen möglicherweise codierten Methoden, die nicht Bestandteil der explizierten Schnittstelle sind,
nicht von einem entfernten Objekt aus zugreifbar.
Formal implementiert die Klasse mit HelloInterface die öffentlich zur Verfügung gestellten Operationen.
Zusätzlich muß sie als Spezialisierung der API-Klasse UnicastRemoteObject definiert sein um durch die virtuelle Maschine zur Laufzeit als
Objekt mit entfernten Zugriffen behandelt zu werden. Dies zieht von der Behandlung des lokalen Falles
abweichende Handhabungen der Parameterübergabe sowie der Freispeicherverwaltung und -rückgewinnung nach sich.
Die Implementierung der durch die Schnittstelle bekanntgegebenen und später durch entfernte
Objekte nutzbaren Operation erfolgt identisch zur herkömmlichen Umsetzung im lokalen Falle. Einzige
äußerlich erkennbare Änderung ist die Deklaration der möglicherweise bei der Ausführung
auftretenden RemoteException.
Diese wird jedoch üblicherweise nicht aktiv durch den anwenderdefinierten Code ausgelöst, sondern wird
durch die Java-Standardbibliothek bzw. die -Laufzeitumgebung erzeugt. Die Deklaration dieser Ausnahme ist für
Operationen, auf deren Implementierung entfernt zugegriffen werden soll, zwingend.
Zusätzlich nimmt die Applikation im Konstruktor die Registrierung des neu erzeugten Objektes unter dem
frei gewählten Namen HelloService in der RMI-Registry vor. Hierbei wird die Methode
rebind verwendet, um eine eventuell bereits existierende Objektbindung unter diesem Namen
zu überschreiben. Auffallend ist die zur Bindung in der Registry verwendete URI rmi://localhost:1099/HelloService.
Sie enthält nach dem idenzifizierenden URI-Schema (rmi) zwingend die Identifikation derjenigen Maschine,
die das bereitzustellende Objekt verwaltet. Einschränkend sei hier jedoch angemerkt, daß RMI lediglich
die Registrierung von Objekten vorsieht, die auf derselben physischen Maschine verwaltet werden wie der
Registrierungsdienst selbst. Daher ist neben dem Pseudonamen localhost lediglich der Name der
Maschine bzw. deren IP-Adresse oder die Pseudoadresse 127.0.0.1 zugelassen. Die optionale Portnummer
benennt die logische TCP-Portadresse, über welche Kommunikationen mit der RMI-Registry abgewickelt werden. Daran
im Anschluß folgt der anwenderdefinierte Namen des abzulegenden Objekts.
Obwohl nach erfolgreicher Ausführung der Methode rebind die Kontrolle an das
neu erzeugte Objekt der Klasse HelloServer zurückübergeben wird, terminiert das Programm
nach Abarbeitung des Konstruktors (und damit Abschluß der Anweisungen in main) nicht, sondern
wird durch die RMI-Registry wartend auf Aufrufe der Methode sayHello im Hauptspeicher gehalten.
Die Klasse HelloClient:
| Beispiel 96: Die Klasse HelloClient |
Download des Beispiels |
![]()
Die Klasse des Beispiels 96 enthält den
notwendigen Code um auf eine entfernt verwaltete und abgelegte Ausprägung der Schnittstelle
HelloInterface zuzugreifen.
Zunächst wird vermöge der Methode lookup eine Referenz eines HelloInterface-konformen Objekts aus
dem RMI-Verzeichnisdienst erfragt. Hierzu dient die bereits zur Ablage verwendete URI
auch zu Ermittlung des Objekts durch das nutzungswillige Clientobjekt. Naturgemäß müssen sich Client- und
Serverobjekt nicht auf derselben physischen Maschine befinden, sondern müssen lediglich durch eine
bestehende Netzwerkverbindung miteinander kommunizieren können.
Nach Erhalt der Referenz kann das entfernte Objekt einem durch die lokale virtuelle Maschine
verwaltetem gleichgestellt verwendet werden.
Da das Server-Objekt auch nach Abarbeitung seiner Methode resident im Speicher der entfernten
virtuellen Maschine verbleibt ermittelt jeder Client bei jedem Aufruf der Methode lookup
denselben Verweis auf dasselbe physische Objekt. Aus diesem Grunde ist bei der Programmierung darauf zu achten,
daß sich nebenläufig stattfindende Zugriffe nicht gegenseitig behindern oder inkorrekte Ergebnisse liefern.
Die Nutzung des Verzeichnisdienstes ist keine notwendige Voraussetzung zur Ausführung entfernter Methodenaufrufe. Besitzt der Client bereits eine Referenz auf das entfernte Objekt (etwa aus einem Aufruf durch dieses welcher die Objektreferenz als Parameter enthielt), so kann der entfernte Methodenaufruf auch ohne vorherige Ermittlung der Referenz aus dem RMI-Verzeichnisdienst erfolgen.
Die Parameterübergabe zwischen Client und entferntem Serverobjekt geschieht anders als in der
Java-üblichen Weise, d.h. für primitivwerte
Parameter als Wert und Objektwertige als Referenz, durchgängig durch Wertübergabe.
Dies liegt darin begründet, daß der innerhalb der virtuellen Maschine verwandte Referenzierungsmechanismus
auf Objekte als Inhalte des Heaps der virtuellen Maschine, nicht über Rechnergrenzen hinweg portabel gestaltet ist.
Durch den notwendigen Aufwand der durch die Stub- und Skeletonkomponente zu codierenden bzw. zu
decodierenden Daten steigt bei komplexen Objektstrukturen (z.B. Bäumen) sowohl die CPU-Last
der Client- als auch der Servermaschine sowie die Netzwerklast.
Einzige Ausnahme von dieser Mimik bilden per RMI zugreifbare (entfernte) Objekte selbst. Sie werden nicht
serialisiert und übertragen, sondern transparent durch ihre Stub-Repräsentation ersetzt, die an ihrer
statt übertragen wird. Dies gilt insbesondere natürlich auch für Selbstreferenzen des Serverobjektes, die
dieses als Rückgabewert liefert.
Naturgemäß ergeben sich auch für die verteilte Freispeicherverwaltung (distributed garbage collection)
veränderte Rahmenbedinungen, wenngleich gemäß dem RMI-Designziel größtmöglicher Transparenz versucht wurde,
eine ähnliche Handhabung wie bereits für den lokalen Fall zu realiseren.
Das in RMI gewählte Vorgehen orientiert sich an dem in der Programmiersprache Modula-3
realisierten: Jede virtuelle Maschine führt eine Tabelle mit einem Boole'schen Eintrag für jedes
aufgrund der publizierten Schnittstellendefinition potentiell entfernt zugreifbare Objekt.
Jeder Eintrag ist vorgabegemäß mit dem Wert clean belegt. Wird eine
Referenz auf das Objekt erfragt, so wird dieses als dirty markiert. Erfolgt innerhalb einer gewissen Zeit
(lease Zeit) keine erneute Anfrage nach einer weiteren Referenz oder ein Zugriff auf das Objekt, so wird
die Markierung auf clean zurückgesetzt und das Objekt so zur Freigabe markiert.
Die Zeitspanne bis zur automatisierten Markierung als nicht mehr benötigtes Objekt kann durch die Java-Property
java.rmi.dgc.leaseValue kontrolliert werden. Vorgabegemäß ist sie auf zehn Minuten gesetzt.
Neben der u.U. speicherplatz- und laufzeitaufwendigen „Dauerinstanziierung“ eines entfernt zugreifbaren Objektes, wie sie das vorherige Beispiel einführt, existiert die Möglichkeit, Objekte bei Bedarf dynamisch erzeugen zu lassen.
Das nachfolgende Beispiel zeigt dies. Der Ablauf in Erstellung und Ausführung ähnelt dem zuvor für einfache RMI-Applikationen gezeigten, jedoch unter Nutzung einer zusätzlichen Ausführungskomponente.
ActivatableHelloInterface)ActivatableHelloServer)ActivatableSetup)ActivatableHelloClient)rmic)rmiregistry)rmid)Im Vergleich zum vorhergehenden Ablauf wurde in diesem Beispiel
die Registrierung des Servers in eine eigenständige Applikation ausgelagert, da ihr Ablauf im Konstruktor
des Serverobjektes bei wiederholter Instanziierung durch die RMI-Umgebung redundant ausgeührt würde.
Ferner entfällt der explizite Start des Serverobjektes, da diese Aufgabe nunmehr automatisiert durch das
Framework übernommen wird.
Die Komponente welcher die Kontrolle und Durchführung der Startvorgänge obliegt, der RMI-Daemon, muß dafür
einmalig zusätzlich durch den Anwender gestartet werden.
Die Schnittstelle ActivatableHelloInterface:
| Beispiel 97: Die Klasse ActivatableHelloInterface |
Download des Beispiels |
![]()
Seitens der Schnittstellenbeschreibung der exponierten Operationen ergeben sich durch den Übergang auf die servergesteuerte Instanziierung keine Änderungen.
Die Klasse ActivatableHelloServer:
| Beispiel 98: Die Klasse ActivatableHelloServer |
Download des Beispiels |
![]()
Seitens der Implementierung des für entfernte Aufrufe zur Verfügung gestellten Objekts ergeben
sich durch die geänderte Instanziierungsmimik keine gravierenden Änderungen.
Lediglich die geänderte Spezialisierung, statt UnicastRemoteObject wird jetzt von der Klasse
Remote abgeleitet, fällt zunächst ins
Auge. Diese Änderung ist notwendig, um dem Framework die Möglichkeit der Instanziierung zu eröffnen, die bei
einer völlig freien Formulierung --- insbesondere des Konstruktors --- nicht möglich wäre. Im Kern definiert
die Klasse Activateable, neben einer Reihe von Hilfsmethoden, vier verschiedene Konstruktoren
zur Anlage von Objekten. Mindestens einer davon ist zwingend durch die abgeleitete Klasse zu implementieren
um dem eine automatisierte Objekterzeugung zu erreichen.
Hinsichtlich der Problemlogik, im Beispiel der Methode sayHello ergeben sich keine Änderungen.
Die Klasse ActivatableHelloClient:
| Beispiel 99: Die Klasse ActivatableHelloClient |
Download des Beispiels |
![]()
Wie bereits beim Server gezeigt, ergeben auch Clientseitig durch die Veränderte Erzeugungssemantik keine Änderungen in der Ablauflogik, abgesehen von durch die geänderten Namen dieses Beispiels bedingte Modifikationen.
Die Klasse ActivatableSetup:
| Beispiel 100: Die Klasse ActivatableSetup |
Download des Beispiels |
![]()
Die nachhaltigsten Veränderungen spiegelt die neu eingeführte Klasse zur Registrierung des Objekts
für entfernten Zugriff wieder.
Sie parametrisiert und initialisiert zunächst den RMI-Daemon, der später im Bedarfsfalle die Erzeugung der
benötigten Objekte übernimmt. Daran Anschließend wird ein konform zur publizierten Schnittstelle
umgesetztes Objekt gemäß dem bisherigen Verfahren innerhalb des RMI-Verzeichnisdienstes
an einen frei gewählten Namen gebunden.
Der automatische Aktivierungsprozeß erfordert zur Laufzeit des RMI-Daemons den Zugriff auf ein lokales
oder erreichbares Dateisystem. Für alle Fälle des Zugriffs auf ein nichtlokales Dateisystem muß
daher eine geeignete Sicherheitseinstellung der Javaausführungsumgebung gewählt werden. Im Standardumfang
der API bereits enthalten ist die Klasse RMISecurityManager. Sie erlaubt es dynamisch geladenen Code innerhalb einer RMI-Umgebung
auszuführen.
Zusätzlich kann über die Java-Property java.security.policy eine sog. policy-Datei
referenziert werden, die nach Herkunft abgestufte Zugriffsrechte für signierte Inhalte definiert.
Für das wiedergegebene Beispiel wurde eine eine sehr lose Policy gewählt, die jeglichem Code den Zugriff
auf alle Java-Funktionalitäten gestattet. (Policy-File)
Mittels der Policyeigenschaften com.sun.rmi.rmid.ExecPermission und com.sun.rmi.rmid.ExecOptionPermission
läßt sich eine noch feinere Zugriffssteuerung erreichen, wobei jedoch diese vorgabegemäß immer
unabhängig von der Codeherkunft und einer evtl. existierenden Signatur zu definieren sind.
Die späteren Aktivierungsaufrufe werden innerhalb einer Aktivierungsgruppe gebündelt. Eine solche
wird mittels einer Beschreibung (als Ausprägung der Klasse ActivationGroupDesc) hinsichtlich ihrer eineindeutigen
Identität und ihrer Inialisierungsdaten beschrieben (im vorliegenden Beispiel ist sie mit null initialisiert).
Diese Aktivierungsgruppe wird mit den durch die Policy-Datei definierten Rechten ausgestattet erzeugt.
Die notwendige eineindeutige Identität wird durch das Aktivierungssystem mittels des Aufrufs der Methode
registerGroup
automatisch zur Verfügung gestellt. Hierbei gilt eine eindeutige Zuordnung zwischen Gruppenkennung (ActivationGrouID) und
verwaltender virtueller Maschine. Soll daher ein Objekt oder eine ganze Gruppe in einer separaten virtuellen
Maschine ablaufen, so genügt es, eine andere Gruppenkennung durch das System zu generieren und bei der
nachfolgend diskutierten Registrierung zu übergeben.
Anschließend wird durch das Beschreibungsobjekt mit dem Klassennamen des automatisch zu instanziierenden
Objektes (im Beispiel: ActivatableHelloServer) sowie der physischen Lokation der Klasse
und etwaigen Initalisierungsdaten erzeugt und der Aktivierungsgruppe zugeordnet.
Als letzter Schritt erfolgt die Registrierung der durch die Aktivierungsbeschreibung beschriebenen Klasse von
Objekten, um so ihre spätere Erzeugung zu gewährleisten. Dies geschieht durch Aufruf der statischen Methode
register der als Parameter die erzeugte Aktivierungsbeschreibung übergeben wird.
Der Aufruf dieser Methode liefert den Stub des registrierten Objekts. Aufgrund der Stellvertreterrolle des
Stubs (d.h. seiner Konformität zur Schnittstelle Remote) kann dieser zur Registrierung der Objekte
in der RMI-Registry verwendet werden.
Der Aufruf der Klasse ActivationSetup erfolgt durch Übergabe von gültigen Belegungen der notwendigen
Laufzeiteigenschaften an die virtuelle Javamaschine: java -Djava.security.policy=./policy -Djava.rmi.codebase=file:/home/mario/RMITest/activation/ ActivationSetup.
Objekte werden zwar durch den RMI-Daemon automatisiert aktiviert, sobald ein Zugriff auf sie erfolgt (lazy activation),
jedoch nicht mehr deaktiviert. Das bedeutet, daß sie bis zur Terminierung der virtuellen Maschine im Hauptspeicher verbleiben.
Abhilfe schafft hier der explizite Aufruf der Methode inactive der ein bereits bestehendes Objekt passiviert, jedoch nicht aus der Registrierung entfernt.
Ähnlich wie bereits für die RMI-Registry angemerkt, muß auch der RMI-Daemon auf derselben physischen
Maschine zur Ausführung gelangen, die das für entfernte Zugriffe bereitzustellende Objekt enthält.
Es ergibt sich daher generell folgendes Verteilungsschema:

Um die irreführenden Begriffe Client und Server zu vermeiden, sind die beiden Maschinen
neutral durch Maschine1 und Maschine2 bezeichnet (Die
Irreführung erklärt sich aus der mangelnden Trennschärfe der beiden Begriffe, sobald ein dienstanbieter
Knoten auch gleichzeitig Dienste anderer Knoten nutzt, er damit gleichzeitig Server (seines Anfrages) und
Client (bezüglich seiner Anfrage) ist).
Ein Object1, das auf ein entferntes Objectn+1 zugreift (invoke)
kann optional mittels der RMI Registry, welche auf demselben Rechner wie die virtuelle Maschine die das
Objectn+1 verwaltet ablaufen muß, die notwendige Objektreferenz ermitteln (lookup).
Sofern das zuzugreifende Objekt (noch) nicht existiert kann es über den Aktivierungsmechanismus gestartet werden.
Die notwendige Objekterzeugung (instantiate) nimmt hierbei der RMI-Daemon (RMID) vor.
Generell werden die durch Stubs und Skelettons verarbeiteten Objekte oder Primitivwerte lediglich serialsiert,
aber keine weiteren Maßnahmen zur Gewährleistung der Vertraulichkeit der übertragenen Daten ergriffen.
Durch die Integration des RMI-Mechanismus in die Java-API besteht die Möglichkeit innerhalb der Programmiersprache
Möglichkeiten zur Übertragungssicherung zu ergreifen.
Seitens RMIs ist es hierbei vorgesehen die bestehende (einfache) TCP-Socketverbindung gegen beliebige selbsterstellte
auszutauschen. Die Erzeugung der notwendigen Sockets muß mittels der Schnittstellen
RMIServerSocketFactory bzw.
RMIClientSocket abgewickelt werden.
Auf diesem Wege stellt bleibt die Typsicherheit der Laufzeitumgebung, auch bei abgeänderten Transportprotokollen
gewahrt.
Das nachfolgende Beispiel zeigt die Umsetzung einer einfachen gesicherten Verbindung mittels XOR-Bearbeitung
aller versandten Inhalte.
Aus Gründen der Übersichtlichkeit sind die inhaltlich unverändert aus dem ersten Beispiel dieses Kapitels
übernommenen Dateien Hello.java
sowie HelloClient.java nicht wiedergegeben.
Die Klasse HelloImpl:
| Beispiel 101: Die Klasse HelloImpl |
Download des Beispiels |
![]()
Die Klasse zeigt als einzige offensichtliche Veränderung die Ergänzung des Konstruktors des entfernt zugreifbaren Objekts um die Erzeugung der alternativ verwendeten XOR-Sockets; alle weiteren Aufwände die veränderte Kommunikation abzuwickeln sind für den Programmierer transparent und werden durch das RMI-Framework sowie die Implementierung der XOR-Sockets erbracht.
Die Bestandteile der XOR-Socketimplementierung finden sich hier:
| Web-Referenzen 12: Weiterführende Links |
![]()
Hinweis: Dieses Kapitel ist noch unvollständig
Ergebnisse eines Anwendungssystems werden typischerweise zur Laufzeit auf der Basis von Anwendungslogik und in Abhängigkeit der Eingaben berechnet. Dies gilt auch für Web-basierte Anwendungssysteme. Jedoch stellt das HTML-basierte Web konzeptionell zunächst ein statisches Medium, welches vorgefertigte Hypertextseiten auf über das HTTP-Protokoll übermittelte Anforderung ausliefert, dar.
Zur Versöhnung dieses Widerspruchs haben sich zwei Ansätze herausgebildet: Zum einen die vollständige
Verlagerung der Berechungslogik und Erbebnispräsentation in den anfragenden Client durch Übertragung eines
vollständigen binären Programms. Zum anderen der Aufruf von serverseitig vorgehaltenen Applikationen, die nicht
im Adresskontext des Webservers operieren.
Bekanntester Vertreter der ersten Kategorie sind die Java Applets, welche eine als Java Bytecode
bezeichnete portable Binärrepräsentation an den Client übertragen, die dieser durch eine interpretativ arbeitende
virtuelle Maschine ausführt. Die in der Praxis bedeutsamste Realisierung zum Zugriff auf extern vorliegende
Programme stellt das Common Gateway Interface (CGI) dar.
Jedoch ergeben sich bei beiden Lösungsalternativen spezifische Probleme. So wird zur vollständigen Verlagerung
der Ausführungslogik auf den Client, wie sie für Applets propagiert wird, die Möglichkeit zur Ausführung
fremden Codes erzwungen. Dies läßt sich zwar durch geeignete Sicherheitsmechanismen absichern, jedoch bleibt die
Notwendigkeit, den Code per Internet zu beziehen und lokal auszuführen.
Der CGI-Ansatz krankt an der mangelnden Ausführungsgeschwindigkeit, welche durch die notwendigen
Prozeßkontextwechsel drastisch sinkt. Gleichzeitig unterliegt die auf diesem Wege angebundene Kontrollogik
nicht der Verwaltungshoheit des Servers.
Java Servlets stellen konzeptionell eine konfluente Weiterentwicklung der beiden Ansätze dar, die
es sich zum Ziel gesetzt hat die angeführten Nachteile zu mildern.
Hierbei handelt es sich primär um Server-seitig ausgeführten Java-Code,
der über Internetprotokolle (zumeist HTTP) mit dem Benutzer interagiert.
Technisch gesehen stellen Servlets Module eines Web-Servers dar,
die dynamisch anstelle der Auslieferung statischer Inhalte (z.B. HTML-Seiten) ausgeführt werden.
Zur Ausführung dient eine als Servlet Container bezeichnete Softwarekomponente, welche
die durch die dort abgelegten Servlets bedienten Schnittstellen der Standard-API bedient.
Bis zur Freigabe der Java-2-Plattform war die Servlet-API Bestandteil des JDK.
Mittlerweile sind neben der Servlet-Spezifikation von SUN auch einige Implementierungen in
verbreiteten Web-Servern verfügbar. Daher wurde die gesamte Servlet-API aus
dem javax-Paket entfernt, und steht nunmehr nur noch als Bestandteil
diverser Web-Server-Produkte (u.a. J2EE-Servern) zur Verfügung.
Lebenszyklus eines Servlets:
Im Detail korrespondieren diese drei Phasen mit Methoden der Servlet-Schnittstelle:
init(ServletConfig)service(ServletRequest, ServletResponse)destroy()destroy() erfolgen keine Aufrufe an service()
mehr durch den Servlet Container.Ergänzend existieren noch die beiden Methoden
getServletConfig() zum Zugriff auf die bei der Initialisierung übergebenen Parameter,
und getServletInfo() zur Rückgabe einer beliebigen Zeichenkette
(zumeist für Copyrightinformation o.ä. benutzt).
Die Servlet API gliedert sich in drei Stufen. Die Schnittstelle Servlet
definiert alle notwendigen Verwaltungsoperationen, die innerhalb eines Servlets durch Methoden zu
implementieren sind. Gleichzeitig liefert die diese Operationen umsetzende abstrakte Klasse
GenericServlet eine erste einfache Basisimplementierung dieser Operationen. Die
Spezifikation empfiehlt konkrete protkollspezifische Servletimplementierungen immer als Spezialisierung
dieser Klasse zu realisieren. Für das populäre HTTP-Protokoll liefern die Standardimplementierungen
mit HttpServlet eine solche Implementierung mit.
Abbildung 1 stellt die Struktur der Basis API in der Übersicht zusammen.

Struktur eines Servlets:
Die Schnittstelle Servlet definiert alle Methoden, die ein Servlet zwingend implementieren muß.
Dies kann durch eigenen Code geschehen, oder durch Erben von einer der vorgegebenen Klassen wie
GenericServlet oder dem gebräuchlicheren HttpServlet.
Durch die Schnittstelle werden bereits Primitive für die beiden möglichen Kommunikationsrichtungen eingeführt: ServletRequest (Kommunikation vom Client zum Server) und ServletResponse (inverse Kommunikationsrichtung; Server an Client), als Parameter eines durch ein Servlet offerierten services.
Beide Primitiven sind wiederum als Schnittstellen definiert, die durch konkrete Implementierungen (wie HttpServletRequest bzw. HttpServletResponse) umgesetzt werden müssen.
Die Schnittstelle ServletRequest ermöglicht es dem Servlet auf Parameternamen, Protkolldetails und Rechnernamen der sendenden Maschine zuzugreifen.
Ferner stellt die Schnittstelle den ServerInputStream und den PrintReader zur Verfügung, über den Daten des Clients (beispielsweise per HTTP POST oder PUT) empfangen werden können.
Die Schnittstelle ServletResponse erlaubt es dem Servlet Verwaltungsinformation, wie MIME-Typ und Content-Länge, der Antwort zu setzen.
Darüberhinaus stellt es mit dem ServletOutputStream einen Kommunikationskanal für binäre Antwortdaten zur Verfügung. Unicode Text-artige Antworten können per PrintWriter übermittelt werden.
Die abstrakte Klasse HttpServlet stellt die notwendigen Methoden zur Bedienung von Client-Anforderungen bereit. Mindestens eine dieser Methoden ist zu überschreiben, um das gewünschte Verhalten des Servlets zu implementieren.
Die Implementierung des Beispiels 102 zeigt ein einfaches Servlet, welches nach einem Aufruf ein HTML-Dokument erzeugt und zurückliefert.
| Beispiel 102: Ein einfaches Servlet |
Download des Beispiels |
![]()
Im Beispiel wird die goGet-Methode überschrieben, d.h. das Servlet reagiert auf HTTP GET-Anfragen.
Als Antwort (ein wohlgeformtes HTML-Dokument) wird über den PrintWriter als Text (MIME-Typ text/html) versandt.
Der Servlet Container initialisiert und übergibt jedem Aufruf der Methode doGet ein Objekt des
Typs HttpServletRequest und eines des Typs HttpServletRespone (welches im vorhergehenden Beispiel
zur Übermittlung HTML-codierter Ergebnisse genutzt wurde.
Der Übergabeparameter des Typs HttpServletRequest ermöglicht den Zugriff auf die mit dem Aufruf des
Servlets versandten Parameter.
Beispiel 103 zeigt den Fall eines HTTP-basierten
Servlet, welches die Parameter des GET-Aufrufs eingebettet in die URL erhält. Ein möglicher Aufruf enthält
daher neben der Lokation des Dienstes auch die notwendigen Aufrufparameter: http://www.example.com/addService?a=1&b=2.
| Beispiel 103: Ein einfacher Dienst |
Download des Beispiels |
![]()
Neben den bisher genutzten GET-Anfragen stehen im Rahmen der Standard-API auch Methoden zur Behandlung der
übrigen HTTP-Methoden zur Verfügung. Beispiel 104 zeigt die Funktionalität
zum Zugriff auf Parameter im Rahmen eines DELETE-Aufrufs, auf HTTP-Headerdaten im Rahmen eines GET-Aufrufs
sowie die Extraktion von Nutzdaten eines POST-Aufrufs.
| Beispiel 104: Verschiedene Servletmethoden |
Download des Beispiels |
![]()
Die Aufrufe erfolgen im HTTP-üblichen Stil:
GET /HashMapApp HTTP/1.0
key:namePOST /HashMapApp HTTP/1.0
key:name&value:marioDELETE /HashMapApp?key=namePrinzipiell ist der Servletgedanke auch auf beliebige andere Protokolle und deren Operationen übertragbar. Jedoch wird
er in der Praxis zumeist für HTTP eingesetzt. Die API ist jedoch generell so gestaltet, daß anwenderdefiniert jederzeit
zusätzliche potokollspezifische Spezialisierungen der Klasse GenericServlet definiert werden können.
Stand Datenaustausch in der Betrachtung der Metasprache XML bisher nahezu ausschließlich im Zeichen datei- oder strombasierter Integration, so eröffnet das Einsatzgebiet der Web Services den Einsatz XML-basierter Sprachen zur Abwicklung Internet-basierter online Kommunikation zwischen Anwendungssystemen.
Dem Begriff Web Service war in jüngerer Zeit eine bemerkenswerte Karriere beschieden, so daß
es ihm gelang in der Praxis beachtliches Interesse auf sich zu ziehen. Allerdings fehlt bisher eine einheitliche
Definition dieses Terminus hinsichtlich Zielsetzung und technischer Inhalte. Vielmehr versuchten und versuchen
namhafte Herstelle durch eine Reihe verschiedener Definitionen,
die am Markt offen zueinander in Konkurrenz treten, bisherige Techniken mit dem Ansatz der Web Services zu verschmelzen.
Jedoch führt(e) diese Vorgehensweise weder zu einer einheitlichen Begriffsübereinkunft und daher in der Folge auch zu keiner
brauchbaren Abgrenzung gegenüber existierenden Techniken --- wie CORBA, RMI oder DCOM
--- im Umfeld.
Nachfolgend wird daher eine an die Ergebnisse der Web Service Architecture-Arbeitsgruppe
des World Wide Web Konsortiums angelehnte Definition zugrunde gelegt:
| Definition 12: Web Service |
Ein Web Service ist ein durch eine URI (gemäß RFC 2396)
identifiziertes Softwaresystem, dessen öffentliche Schnittstellen und Protokollbindungen durch XML definiert und beschrieben sind. Diese Definitionen können durch andere Softwaresysteme ermittelt und bezogen werden. Auf der Basis der publizierten Schnittstellendefinitionen können diese Systeme dann mit dem Web Service in der durch die Schnittstelle festgelegten Weise interagieren. Diese Interaktion geschieht durch den Austausch XML-basierter Nachrichten, die mittels Internetprotokollen übertragen werden. |
![]()
Der Begriff des Service ist hierbei durchaus in Anlehnung an den klassischen Dienstleistungsbegriff gemeint. Dieser beschreibt Handlungen, die im Auftrag eines Dritten vorgenommen werden, welche kein physisches Gut produzieren, sondern deren Charakter ausschließlich durch die Handlungserbringung selbst definiert ist.
Die Definition enthält ferner bereits Aussagen über die Komponenten einer Web Service basierten Architektur (einer sog. serviceorientierten Architektur (SOA)) und deren technischer Realisierung. Grundlegend Eigenschaften einer solchen Architektur ist neben der XML-Basiertheit die Verwendung von Universal Resource Identifkatoren zur eineindeutigen Benennung eines angebotenen Dienstes sowie die Nutzung der bestehenden Internetinfrastruktur zur Datenübertragung. Der Begriff Internetinfrastruktur soll hierbei nicht verengt auf die Techniken des WWW, d.h. HTTP auf Basis TCP/IP, verstanden werden, sondern durchaus im Sinne des der Internetprotokollhierarchie gebraucht werden.
Gleichzeitig postuliert die Definition drei grundlegende Elemente einer serviceorientierten Architektur:
Diese drei aufeinander aufsetzenden Dienstschichten deuten auch bereits drei typische Rollen innerhalb einer serviceorientierten Architektur an:
Ausgehend von den Grundrollen und ihren Interaktionsbeziehungen ergeben sich die zwei in Abbildung 23 Abläufe für die Abwicklung einer Web Service-basierten Kommunikation.

Die Abbildung hebt die optionalen Schritte zur Ermittlung der Schnittstellenbeschreibung blau hervor. Liegt diese
dem Aufrufwilligen bereits vor oder ist die Schnittstelle ihm bereits bekannt, so kann auf den Bezug der im Dienstverzeichnis
abgelegten Beschreibungsdaten verzichtet werden und der Dienstaufruf direkt erfolgen.
Die Schnittstellenbeschreibung nimmt damit keine herausragende Rolle innerhalb der Architekturerstellung ein, wie dies
beispielsweise für CORBA, RMI oder DCOM der Fall wäre (dort ist die Schnittstellenbeschreibung Teil des
Entwicklungszyklus und muß zum Übersetzungzeitpunkt des Aufrufclients zwingend vorliegen).
Aus der Kombination der Architekturelemente und der Interaktionsszenarien haben sich drei Standards am Markt etabliert, deren Implementierungen die dargestellten Grundaufgaben innerhalb einer serviceorientierten Architektur erfüllen:
Anmerkung: Ursprünglich wurde das Akronym SOAP zu Simple Object Access Protocol expandiert. Aufgrund der irreführenden Nähe zur objektorientierten Programmierung wurde jedoch im Verlauf des Standardisierungsprozesses beschlossen etablierte Akronym als Namen beizubehalten, jedoch von der weiteren Expansion abzusehen.
SOAP, welches als Version 1.0 im Herbst 1999 als Ergebnis der Kooperation zwischen den Firmen DevelopMentor,
IBM, Microsoft, Lotus und UserLand Software vorgestellt wurde markiert weniger den
Beginn der Idee der Web Services, als vielmehr einen weiteren evolutionären Entwicklungsschritt.
Die Uridee die zur Abwicklung synchroner entfernter Funktionsaufrufe (Remote Procedure Calls (RPC))
zu übermittelnden Über- und Rückgabeparameter durch ein XML-Vokabular auszudrücken findet sich bereits im
Protokoll XML-RPC verwirklicht.
Ausgehend von diesem Ansatz definiert SOAP in der Version 1.0 ein vollständiges Protokoll, welches neben der Übertragung von Nutzdaten auch die Darstellung von dekriptiver Verwaltungsinformation vorsieht. Wie bereits für XML-RPC ist auch bei SOAP v1.0 ausschließlich die Verwendung von HTTP als Transportprotokoll definiert.
Diese Beschränkung wird durch die Anfang 2001 freigegebene SOAP Version 1.1 aufgehoben, welche SOAP als vollständig von der zu tatsächlichen Übertragung gewählten Protokollschicht entkoppelt und damit als eigenständige Protokollabstraktion etabliert. Gleichzeitig führt diese Version die Möglichkeit asynchroner Aufrufe ein.
Um den SOAP-Ansatz einer breiten Interessentenschicht zugänglich werden zu lassen und auch die Sensibilisierung für eine
mögliche Standardisierung des Protokolls zu schaffen reichen die beteiligten Partner die Spezifikationsversion 1.1 unverändert
als W3C Note ein.
Die im Herbst 2000 begonne Standardisierungsarbeit durch die W3C XML Protocol Arbeitsgruppe übernahm den eingereichten Spezifikationsvorschlag der Version 1.1 weitestgehend und führte, aus Gründen der Interoperabiltität behutsame Korrekturen sowie umfangreiche Erweiterungen ein. Mit der Verabschiedung des endgültigen W3C-Standards ist im Laufe des Jahres 2003 zu rechnen.
Die Abbildung 24 stellt nochmals die einzelnen SOAP-Versionen, ihre Unterschiede und den Vorläufer XML-RPC in der chronologischen Übersicht zusammen.

Jede SOAP-Nachricht, unabhängig davon ob es sich um eine synchron oder asynchron übermittelte Anfrage oder Antwort handelt besteht generell aus zwei Teilen:
Body) zur Aufnahme der zu übermittelnden Nutzdaten.Header) zur Aufnahme von Metainformation.Das Beispiel 105 zeigt einen vollständigen SOAP-Aufruf.
Er besteht aus einem Umschlag (dargestellt durch das Element Envelope), der das beschreibende
Kopfelement altertcontrol sowie die im Body-Element zusammengefaßten Nutzdaten enthält.
Alle durch den Standard vorgegebenen Elemente und Attribute sind dem Namensraum http://www.w3.org/2003/05/soap-envelope
zugeordnet und alle Anwenderdefinierten den entsprechenden eigenen Namensräumen.
| Beispiel 105: Ein vollständiger SOAP-Aufruf |
|
![]()
Die Aufgabe der SOAP-Header ist es Verwaltungsinformation aufzunehmen, die nicht ausschließlich durch den
Empfänger des SOAP-Aufrufes zu verarbeiten ist und die nicht Teil der Nutzdaten ist.
Beispiele hierfür sind Daten über das Routingverhalten, gesetzte Sperren oder Transaktionen aber auch Zugriffsdaten wie
Nutzername und Passwort (diese natürlich verschlüsselt!).
Die Verarbeitung eines Kopfelements ist vorgabegemäß optional, außer das zusätzliche gesetzte Attribut mustUnderstand
weißt den Wert 1 oder true (die beiden durch XML Schema zugelassenen lexikalischen Repräsentationen
für logisch wahr) auf. In diesem Falle muß ein SOAP-Knoten das Kopfelement verarbeiten. Kann die
Verarbeitung nicht vorgenommen werden, so muß an den Sender der SOAP-Nachricht eine Fehlermeldung übermittelt werden.
Ein SOAP-Knoten ist hierbei jeder Rechner entlang des Nachrichtenpfades zwischen Sender und Empfänger, der
das SOAP-Protokoll verarbeiten kann.
Soll die Verarbeitung der SOAP-Kopfelemente auf einen bestimmten Rechner (beispielsweise einen zwischenspeichernden
Proxy-Knoten) beschränkt werden, so kann durch das im Standard vorhergesehene Attribut role eine
eineindeutige Adressierung eines durch URI identifizierten (Zwischen-)Knotens erreicht werden.
Das Beispiel 106 zeigt die Nutzung des role- und des
mustUnderstand-Attributs.
| Beispiel 106: Nutzung der SOAP-Kopfelemente |
|
![]()
Das Beispiel zeigt die Nutzung zweier Kopfelemente (Extension1 und Extension2) in
„eigenen“, d.h. nicht den im Standard vorgesehenen, Namensräumen.
Für beide Kopfelemente ist das Attribut mustUnderstand mit true belegt, was sie als zwingend zu
prozessieren ausweist.
Zusätzlich ist für Extension2 das Attribut role auf http://www.example.com/xyz
gesetzt. Diese Belegung charakterisiert die durch mustUnderstand formulierte verpflichtende Verarbeitung
näher. Im vorliegenden Falle muß sie ausschließlich durch den mit der URI http://www.example.com/xyz bezeichnenden
Zwischenknoten erfolgen, für alle anderen Knoten des Nachrichtenpfades --- einschließlich des endgültigen Empfängers --- kann
dieses Kopfelement ignoriert werden. Der dieses Kopfelement verarbeitende SOAP-Knoten darf es nach erfolgreicher
Prozessierung aus der SOAP-Nachricht entfernen.
Bei der für das zweite Kopfelement (Extension2) gewählten Rolle (http://www.w3.org/2003/05/soap-envelope/role/next)
handelt es sich um eine durch die SOAP-Spezifikation vordefinierte URI, welche alle Knoten entlang des Nachrichtenpfades
einschließlich dem endgültigen Empfänger selbst bezeichnet. In diesem Fall darf das Kopfelement, selbst nach erfolgreicher
Verarbeitung durch einen Knoten nicht entfernt werden, da weitere Verarbeitungsschritte durch andere Knoten folgen können.
(Sofern es sich nicht um den endgültigen Empfänger handelt, müssen sogar weitere Verarbeitungsschritte folgen.)
Neben der dargestellten Sonderbelegung des Rollenattributes definiert der SOAP-Standard des W3C mit http://www.w3.org/2003/05/soap-envelope/role/ultimateReceiver
eine Attributbelegung, die Kopfelemente kennzeichnet die ausschließlich durch den endgültigen Empfänger einer Nachricht
verarbeitet werden dürfen und durch http://www.w3.org/2003/05/soap-envelope/role/none Kopfelemente, die durch
einen SOAP-Knoten nicht verarbeitet werden dürfen.
Durch die Kopfelemente können Einzelknoten entlang des Vermittlungspfades einer SOAP-Nachricht pauschal oder gezielt zu einer anwenderdefinierten Verarbeitung angeregt werden. Die aktiven Zwischenknoten übernehmen hierbei nicht mehr nur reine vermittelnde Aufgaben auf den tieferliegenden (Transport-)Protokollschichten, sondern werden zu aktiven Elementen der SOAP-Nachrichtenkette. Aufgrund ihrer Stellung im Nachrichtenpfad zwischen Sender und endgültigem Empfänger werden sie auch mit dem Begriff SOAP Intermediäre belegt.
Die Übertragung der zwischen Dienstnutzer und Dienst ausgetauschten Daten (d.h. Aufruf- und Rückgabeparameter oder
Einwegbotschaft) erfolgt durch das Body-Element der SOAP-Nachricht.
Beispiel 107 zeigt den erzeugten SOAP-Datenstrom zum Aufruf eines Dienstes
der die beiden int-Parameter a und b addiert und das Ergebnis zurückliefert.
| Beispiel 107: Nutzung des SOAP-Rumpfelements |
|
![]()
Innerhalb des Body-Elements werden die benannten Parameter durch jeweils ein Element, das den Namen
des Parameters trägt, dargestellt. Jedes Parameterelement enthält die lexikalische Repräsentation des zu übertragenden
Wertes. Der aufgerufene Dienst (im Beispiel: add) fungiert als gemeinsames Elternelement der einzelnen
Parameterelemente.
Zur Unterscheidung der verschiedenen Vokabularelemente des SOAP-Aufrufes müssen alle anwenderdefinierten Teile
des Body-Elements einem eigenen, vom SOAP-Vorgabenamensraum abweichenden, Namensraum zugeordnet sein.
Dies geschieht vor dem Hintergrund sowohl der gewünschten Abgrenzung von den durch den Standard vorgegebenen Elementen und
Attributen, als auch mit der Zielsetzung zur Validierung der SOAP-Aufrufe eine XML-Schemainstanz einsetzen zu können.
Hierzu sind die abweichenden Namensräume zwingend erforderlich, um mithilfe des any-Elements die Validierung
der durch den SOAP-Standard strukturell nicht festlegbaren Body-Kindelemente zu ermöglichen.
Die Struktur dieser Kindelemente orientiert sich ausschließlich an der XML-Darstellung der für einen Service notwendigen
Parameter und kann daher im allgemeinen Falle nicht durch den Standard vorgegeben werden. Aus diesem Grunde legt die
SOAP-Spezifikation lediglich Encodierungsregeln zur Transformation hauptspeicherresidenter Objekte und Strukturen in eine
XML-Darstellung fest.
Das Beispiel verwendet diese vordefinierten Encodierungsregeln, welche die Abbildung allgemeiner Objektgraphen in
XML-Strukturen gestatten. Neben dieser, an der Belegung des Attributs encodingStyle mit http://www.w3.org/2003/05/soap-encoding
erkennbaren, Serialisierungsform können durch den Anwender beliebige eigene Regeln zur Gewinnung der XML-Darstellung festgelegt werden.
Einzig das im Standard definierte SOAP-Encoding muß jedoch zwingend von allen Implementierungen unterstützt werden.
In ähnlicher Darstellungsform der Anfrage findet sich auch die Übermittlung der durch den aufgerufenen Dienst berechneten Resultate codiert:
| Beispiel 108: Nutzung des SOAP-Rumpfelements |
|
![]()
Beispiel 108 zeigt die rückübermittelte Antwort des Addier-Dienstes.
Auch sie folgt den selben Struktur- und Erstellungsprinzipien. Daher weist auch Antwortnachricht die Trennung
in (optionale und in diesem Beispiel nicht genutzte) Kopfelemente und nutzdatentragende Rumpfelemente als Kindelemente
des Body-Elements auf.
Die Erstellung der XML-Darstellung erfolgt, wie bereits für den Aufruf, gemäß festgelegter bzw. anwenderdefiniert
festlegbarer Richtlinien einer Encodierungsdarstellung. Auch in diesem Beispiel wurde die Standardencodierung
gewählt, weshalb das encodingStyle-Attribut abermals mit dem Wert
http://www.w3.org/2003/05/soap-encoding versehen ist.
Zur Abgrenzung von den durch den W3C-Standard vordefinierten Elementen muß auch zur Darstellung der Antwort
eines Dienstaufrufs jedes Kindelement des Body-Knotens einen vom SOAP-Standard abweichenden
Namensraum besitzen.
Die Organisation der Darstellung des Dienstergebnisses als XML-Dokument ist dem Diensterbringer überlassen. Im Beispiel
wird ein Element result übertragen.
Quellcode des Web Service
Quellcode eines Web Serviceaufrufes
Die nachfolgende Fallstudie betrachteten einen einfachen Web Service zur Realisierung der mathematischen
Operationen auf dem Körper der komplexen Zahlen.
Die Diskussion wird an der frei verfügbaren SOAP-Implementierung Axis geführt,
welche im Rahmen des Apache-Projekts gepflegt wird. Axis stellt eine vollständig in Java
realisierte Bibliothek zur Umsetzung von Web Services die als Java-Klassen angeboten werden zur Verfügung.
Zur Ausführung wird eine beliebige Servlet-Umgebung benötigt. Für das Beispiel wurde die ebenfalls
kostenfrei verfügbare Jakarta-Tomcat eingesetzt, welche als Ausführungsumgebung der Web Services dient.
Implementierung des Web Service:
| Beispiel 109: Beispielwebdienst |
|
![]()
Beispiel 109 zeigt die Implementierung der Klasse Complex
deren Methoden als Web Service angeboten werden.
Augenscheinlich unterschiedet sich die Implementierung als Web Service nicht von der, die für die statische lokale
Bereitstellung leistenden.
Bei der Umsetzung ist jedoch darauf zu achten, auf this-Verweise in Methodenrümpfen zu verzichten, da
kein Objektkontext durch das SOAP-Protokoll mitversandt wird. Als pragmatisches Hilfsmittel zur Einhaltung dieser
Einschränkung bietet es sich an die als Dienst bereitzustellenden Methoden mit dem Schlüsselwort static
zu versehen.
Zusätzlich ist auf die Definition eines parameterlosen Vorgabekonstruktors zu achten, da dieser serverseitig zur
durch das Framework zur Objekterzeugung herangezogen wird.
Die serverseitige Bereitstellung des Dienstes kann im Rahmen des Axis-Frameworks auf zwei Arten geschehen.
Zum einen durch Bereitstellung des Quellcodes aus Beispiel 109 in einem dafür gesondert vorgesehen Serververzeichnis (typischerweise ../tomcat/webapps/axis).
Zusätzlich ist die Datei mit der Extension jws (statt dem üblichen java) zu versehen. Zum
Aufrufzeitpunkt wird der Quellcode durch das Axis-Framework für den Aufrufer transparent übersetzt und
zur Ausführung gebracht.
Andererseits sieht das Framework die Möglichkeit der Ablage von vorübersetztem Java-Code vor. Dieser in der
Axis-Terminologie als Web Service Deployment bezeichnete Vorgang gestattet dem Anwender
weiterrechenden Einfluß auf Umstände der Dienstbereitstellung als die zuvor gezeigte Vorgehensweise.
Notwendige Voraussetzung des Deploymentvorganges ist die Bereitstellung einer separaten Konfigurationsdatei, dem
sog. Deployment-Deskriptor unter zwingend vorgegebenen dem Dateinamen deploy.wsdd.
Beispiel 110 zeigt eine solche
Konfigurationsdatei für den Beispieldienst.
| Beispiel 110: Deploymentdeskriptor des Beispieldienstes |
|
![]()
Innerhalb der Konfigurationsdatei werden Aussagen über das Interaktionsmuster, welches der Kommunikation mit dem
Dienst zugrunde liegt. Im Beispiel wird durch die Belegung des Attributs style mit dem Wert
RPC synchrone Kommunikation im Stile entfernter Methodenaufrufe gewählt.
Zusätzlich kann ein vom Namen des Compilats abweichender Dienstname frei festgelegt werden (im Beispiel ComplexCalc
als Belegung des Attributs name des service-Elements).
Innerhalb der Kindelemente des Elements service wird die dienstimplementierende Klasse identifiziert
(parameter-Element dessen name-Attribut den Wert className trägt, das zugehörige
value-Attribut desselben Elements enthält dann den vollqualifizierten Klassennamen) sowie die per SOAP
zugreifbaren Methoden mit separierenden Leerzeichen gemäß XML-Konvention
aufgelistet (im Beispiel add mult modulus div pow).
Hierdurch eröffnet die Konfiguration des Webdienstes durch den Deploymentdeskriptor bereits einen Eingriffspunkt, der bei
der reinen serverseitigen Ablage des Quellcodes, mit automatischer Freigabe aller öffentlich zugänglichen Methoden,
nicht bestand.
Ferner können vermöge des Elements beanMapping anwenderdefinierte strukturierte Datentypen, die
als Java-Bean-konforme Klasse umgesetzt sind definiert werden. Im Beispiel ist dies die Klasse zur Implementierung
der komplexen Zahl.
Die Installation und Konfiguration (Deployment) des Web Service geschieht durch Aufruf des Administrationswerkeuges
java org.apache.axis.client.AdminClient deploy.wsdd.
Zusätzlich ist die Dienstklasse im Verzeichnis .../tomcat/webapps/axis/WEB-INF/classes abzulegen.
Implementierung des Web Service Aufrufers:
| Beispiel 111: Aufruf des Beispielwebdiensts |
|
![]()
Beispiel 111 zeigt die Implementierung eines Aufrufs des
Beispielwebdienstes.
Zentrales Objekt des Aufrufs eines Web Service ist die Klasse Call. Sie kapselt die gesamten
zur Kommunikation notwendigen Daten und übernimmt den synchronen Aufruf des entfernten Dienstes. Zur Verwaltung von
Verbindungsdaten, die für verschieden Einzelaufrufe desselben Dienstes gleichermaßen Verwendung finden können diese
zusätzlich durch einen Service repräsentiert werden. Im Beispiel wird hierauf jedoch aus
Übersichtlichkeitsgründen verzichtet und alle alle Einstellungen direkt für das Call-Objekt vorgenommen.
Zu diesen Einstellungen zählt die dargestellte Angabe des Service Endpunktes, derjenigen Adresse, die konform zum
gewählten Übertragungsprotkoll (im Beispiel ist dies HTTP) die physische Übergabestelle des SOAP-Aufrufs an den
Web Service identifiziert.
Daher ist bei Änderung der Dienstbereitstellung, etwa durch Verlagerung auf einen anderen Server oder auch die sich
aus dem oben gezeigten geänderten Deployment ergebende Endpunktadresse, lediglich der Parameter der Methode
setTargetEndpointAddress geeignet anzupassen.
Zusätzlich zur Angabe der aufzurufenden Operation innerhalb des angesprochenen Dienstes, durch die Methode
setOperationName erfolgt durch addParameter die Definition der Übergabeparameter des
Dienstes.
Hierbei muß jeder Übergabeparameter in Name, Typ und Übergabeart spezifiziert werden. Im Beispiel sind dies
die beiden Parameter c1 und n, die als Eingabe (d.h. nur zum lesenden Zugriff) der Methode
pow dienen.
Diese Methode implementiert die Potenzierung komplexer Zahlen durch fortwährende Multiplikation. Ihre Signatur
erfordert daher die Übergabe der komplexen Basis sowie des ganzzahligen Exponenten.
Zur Übertragung der speicherresidenten Wertdarstellung ordnet das Axis-Framework den
Java-Primtivdatentypen
und einigen ausgewählten als Klasse realisierten Datentypen eindeutige Abbildungen in die in XML-Schema definierten
Datentypen zu.
Die Reihenfolge der Aufrufe der addParameter-Methode muß der
Auftrittsreihenfolge in der Signatur des aufzurufenden Dienstes entsprechen, um die Kompatibilität zur Programmiersprachen,
die ausschließlich über Stellungsparameter verfügen zu wahren.
Tabelle 27 stellt die durch das Axis-Framework
Typäquivalenzen zusammen:
| Tabelle 27: Abbildung der Java-Datentypen auf XML-Schema | ||||||||||||||||||||||||||||||
|
![]()
Bei der zu übergebenden komplexen Zahl handelt es sich um eine anwenderdefinierte Klasse, die einen neuen
Java-Typ etabliert für den (naturgemäß) keine Entsprechung in XML-Schema zur Verfügung steht.
Aus diesem Grund muß auf Seiten des Aufrufers und des aufgerufenen Dienstes eine eigene Abbildungsvorschrift
für die Erzeugung der SOAP-Darstellung bereitgestellt werden.
Durch die Axis-Serviceausführungsumgebung kann automatisiert eine solche Abbildung erzeugt werden, sofern
der anwenderdefinierte Typ (d.h. die implementierende Klasse) gemäß der Java-Beans-Programmierkonvention umgesetzt ist.
Diese ist eingehalten, sobald für jedes datenhaltende Attribut eine get- und set-Methode umgesetzt wird. Hintergrund
dieses Vorgehens ist die Möglichkeit der Abfrage aller objektinternen Datenfelder durch Nutzung der Java-Reflection-API.
Die hierfür notwendige Zuordnung zwischen neuem Java- und XML-Typ geschieht im durch Beispiel 110 dargestellten Deploymentdeskriptor ab Zeile sieben. Dort gibt das Attribut qname den Namen des
XML-Typs und languageSpecificType den Namen der implementierenden Java-Klasse (Complex) an.
Entsprechend vollzieht der Dienstaufrufer die Typabbildung im Code nach. Hierzu muß ihm der gewählte Name des neuen
XML-Typen bekannt sein (im Beispiel: Complex im Namensraum urn:Complex). Durch den Aufruf
der Methode registerTypeMapping gibt er dem Framework die Implementierungen der beiden Abbildungsrichtungen
(Java-Hauptspeicherobjekte in SOAP bzw. SOAP zu Hauptspeicherobjekten) bekannt. Das Beispiel verwendet hierzu die im
Axis-Framework mitgelieferten Klassen BeanSerializerFactory und BeanDeserializerFactory
welche das Gewünschte auf Basis einer als Java-Bean codierten Klasse leisten.
Die Festlegung der tatsächlichen Übergabewerte erfolgt im Beispiel durch Erzeugung eines Arrays zur Aufnahme von
Object-typisierten Elementen in die die zuvor hinsichtlich ihres Typs definierten Aktualparameter
eingefügt werden.
Aufgrund der Einschränkung der Programmiersprache Java (bis zur Version 1.4),
die Ausprägungen von Primitivtypen nicht als Objekte behandeln kann, erfolgt im Beispiel die Kapselung des int-Wertes
für n durch ein Objekt der Klasse Integer.
Für die Definition des Typs des erwarteten Rückgabewertes gelten dieselben Gesetztmäßigkeiten hinsichtlich
Bekanntmachung und Zugriffsabwicklung. Die Definition des erwarteten Rückgabetyps erfolgt durch Aufruf der
Methode setReturnType.
Der synchrone Aufruf des entfernten Dienstes wird dann durch die Methode invoke des erzeugten und
entsprechend parametrisierten Call-Objektes vollzogen.
Dieser Aufruf ist blockierend und läßt den Aufrufer bis zum Eintreffen des berechneten Ergebnisses warten.
Die Rückgabe wird, trotz der Definition des spezielleren Rückgabetyps Complex generell als
Object-Ausprägung geliefert um eine strikt typprüfbare Signatur der Methode invoke
zu erhalten. Daher muß das durch den Web Service gelieferte Resultat geeignet, d.h. konform zur durch
setReturnType getroffenen Festlegung, typgewandelt werden.
Beispiel 112 zeigt den SOAP-Datenverkehr beim Aufruf des Dienstes zur Berechnung der Potenz einer komplexen Zahl. Aufgrund des derzeitigen Entwicklungsstandes des Axis-Frameworks weicht der Leitungsmittschnitt von der zu Eingang dieses Kapitels vorgestellten SOAP-Struktur des W3C-Standards ab. Gegenwärtig (d.h. zum Zeitpunkt der Verfügbarkeit der Version 1.1) unterstützt das Framework nur eine Untermenge des neuen Standards und codiert die XML-Nachrichten noch nach dem Stand der Vorgängerspezifikation.
| Beispiel 112: SOAP-Nachricht zum Aufruf des Beispieldienstes |
|
![]()
Im Code des Beispiels gut zu sehen ist die Darstellung der beiden Übergabeparameter c1 und
n für die Basis der Potenzierung und den ganzzahligen Exponenten. Für n wird die
in Tabelle 112 Abbildung in den äquivalenten Typen int
aus XML-Schema durchgeführt. Zusätzlich überträgt die durch Axis gewählte Codierung die Typisierung
explizit mit (Attribut xsi:type="xsd:int") wodurch die Typabbildung offenbar wird.
Für den nicht direkt nach XML-Schema transformierbaren strukturierten (Java-)Datentypen Complex wird
durch den Serialisierungsmechanismus ein eigenes mit multiRef bezeichnetes und durch das
Attribut id identifiziertes Element erzeugt. Dieses Vorgehen entspricht der durch die
SOAP-Spezifikation vorgesehenen Serialisierungs allgemeiner Graphen, welche die speicherresidenten
Datenobjekte als Knoten interpretiert und hierfür wiederverwendbare (der Name des Elements deutet dies an)
Elemente erzeugt. Die tatsächliche Wiederverwendung innerhalb des SOAP-Stromes findet durch Mehrfachnennung
des im id-Attribut festgelegten identifizierenden Wertes im href-Attribut eines
Verweiselementes statt.
Im Beispiel wird die Berechnungsbasis als ein solches multiRef-Element ausgedrückt, welches die
Wertbelegungen der durch get-Methoden zugänglichen Javafelder (im und re) enthält.
Das den Übergabeparameter c1 repräsentierende XML-Element enthält daher lediglich im
href-Attribut einen Verweis auf die multiRef-Struktur.
Beispiel 113 zeigt den für die Übermittlung des Dienstergebnisses
übertragenen SOAP-Datenverkehr.
Auch er weicht, aufgrund der Konformität zur älteren SOAP-Spezifikationsversion, geringfügig vom aktuellen
Standard ab.
| Beispiel 113: SOAP-Nachricht zur Übermittlung des Berechnungsergebnisses des Beispieldienstes |
|
![]()
Wie bereits beim Aufruf realisiert wird die XML-Darstellung des strukturierten Datentyps Complex, der hier
als Rückgabetyp dient, durch Nutzung der allgemeinen Graphenserialisierung erzeugt.
Die Grundidee der Web Services fordert nicht zwingend die Darstellung der Dienstschnittstellen für Dritte, wie dies
beispielsweise Verteilungsarchitekturen wie CORBA und DCOM zwingend als Teil des Entwicklungszyklus vorgeben. Dennoch
erweist es sich auch für Web Services sinnvoll die Schnittstellenbeschreibungen in einem maschinenlesbaren Format
bereitzustellen um Werkzeugen die automatisierte Verarbeitung zu ermöglichen. Hierunter fallen beispielsweise
Entwicklungsumgebungen, die aus Schnittstellenbeschreibungen erste Rohgerüste für die Abwicklung der Dienstaufrufe
generieren können. Zusätzlich stellen formalisiert dokumentierte Schnittstellen einen wichtigen Bestandteil der
Dokumentation eines Softwaresystems dar.
Zur Schnittstellendokumentation von Web Services etabliert sich gegenwärtig der Standard der
Web Service Description Language, der durch eine Arbeitsgruppe des World Wide Web Konsortiums vorangetrieben wird.
Eine WSDL-Beschreibung selbst ist eine XML-Datei, WSDL mithin als XML-Schema-basiertes XML-Vokabular realisiert und zerfällt in sechs Teile:
Die Angaben zur Struktur der anwenderdefinierten Typen ist optional und muß nur im Falle der Existenz solcher Typen erfolgen.
Das Beispiel 114 zeigt die vollständige WSDL-Dienstbeschreibung des aus der Fallstudie bekannten Dienstes:
| Beispiel 114: WSDL-Beschreibung des Beispieldienstes |
|
![]()
Das Beispiel spiegelt im Service-Element die bereits durch den Deploymentdeskriptor getroffenen Festlegungen
wieder und macht sie so dem (potentiellen) Dienstnutzer zugänglich. So enthält das Attribut name mit dem
Wert ComplexService den gewählten Namen des Dienstes. Zusätzlich der als Kindelement
realisierte address-Eintrag unter location die Adresse des SOAP-Endpunktes wieder welche
SOAP-Botschaften zum Dienstaufruf entgegennimmt.
Da derselbe Dienst durch verschiedene Endpunkte zur Verfügung gestellt werden kann, ist das mehrfache
Auftreten von address-Element zugelassen. Aus Gründen der Eindeutigkeit und Zuordnung des Endpunktes
zum jeweils unterstützten Transportprotokoll ist jedes address-Element durch ein port-Element
umschlossen welches auf das definierte Protokoll verweist.
Jedes Operation-Element definiert die zum Aufruf zu übermittelnden Parameter hinsichtlich Reihenfolge und
referenziert die eine Interaktion konstituierenden Interaktionsschritte.
Im Beispiel legt die Operation pow (die Benennung wird durch das name-Attribut festgelegt)
fest, daß die beiden Parameter c1 und n benötigt werden. Zusätzlich erfolgt durch das
Element input eine Referenz auf die Eingabenachricht bzw. output auf die Ausgabenachricht
die zur Initiierung der Operation bzw. nach deren Ende versandt werden.
Innerhalb des Message-Elements werden die Übergabe Parameter inhaltlich hinsichtlich Typ und Name
ausdefiniert.
Für die Nachricht powRequest (Aufruf der Methode pow) werden daher c1 vom
Typ eigendefinierten Typ Complex sowie n vom Standardtyp int genannt.
Durch das WSDL-Element PortType erfolgt die Aggregation der zuvor definierten Operationen, deren
Nachrichten, an den in der Service-Definition genannten Endpunkt.
Die technischen Details wie gewähltes Encodierungsschema und genutzter Namensraum werden im Rahmen des
Binding-Elements für jeden Nichtstandardtypen --- im Beispiel ist dies Complex ---
definiert.
Die zur Erzeugung der über die Netzwerkleitung zu transportierenden XML-Darstellung dieser Nichtstandardtypen wird durch ein XML-Schemafragment beschrieben, welches als Kindelement des WSDL-Elements Types abgelegt ist.
Zwar bietet WSDL eine wertvolle Möglichkeit zur Beschreibung der technischen Schnittstellencharakteristika eines
Web Service, jedoch bleiben andere Fragestellungen --- etwa die nach der Natur und menschenlesbaren Beschreibung eines
Dienstes oder seinen Nutzungs- und Abrechnungsbedingungen --- durch diesen Standard vollkommen offen. Überdies enthält
das offizielle Spezifikationsdokument keinerlei Aussagen über einen präferierten oder auch nur sinnvollen
Bereitstellungsort der WSDL-Beschreibungen.
Einen Ansatz zur Antwort auf diese Fragestellungen versucht der im Rahmen des OASIS-Standardisierungsprozeß vorangetriebene
Verzeichnisdienst Universal Service Description, Discovery and Integration zu liefern.
Dieses, selbst als SOAP-basierter Web-Dienst angebotene, Verzeichnisdienst stellt eine Verwaltungsstruktur zur Ablage von WSDL-Beschreibungen und anderer dienstbezogener deskriptiver Metadaten bereit die durch eine definierte Schnittstelle abgefragt werden kann.
Die Grundprimitive des UDDI-Dienstes sind:
Ziel der Business Entity-Struktur ist es telephonbuchartig beschreibende Metadaten zum Dienstanbieter, wie Firmenname und Erreichbarkeitsdaten in einer alphabetisch sortierten Struktur anzubieten.
Jedem Business Entity-Eintrag können mehrere Business Services zugeordnet sein, welche die angebotenen Web Services repräsentieren.
Jedes tModel (Abkürzung für technical model) kann eine WSDL-Beschreibung oder beliebige durch
den Anwender festlegbare dienstbezogene deskriptive Inhalte aufnehmen.
Insbesondere kann ein tModel auch Kategorisierungen eines Dienstes, etwa die Zuordnung zu einer Dienstfamilie,
die Herstellung eines bestimmten Typ-Kontexts wie Erbringungsort des Dienstes, aufnehmen.
Alle tModels eines Dienstes werden mit diesem durch BindingTemplate-Elemente verbunden.
Die Interaktion mit einem UDDI-Verzeichnisdienst kann SOAP-basiert oder durch manuelle Erfassung der
abzulegenden Daten über eine Webseite erfolgen.
Ziel dieser Interaktion ist zumeist einer der global angebotenen UDDI-Verzeichnisdienste, die gegenwärtig
innerhalb eines Tages für die vollständige Inhaltsreplizierung sorgen.
Aufgrund immernoch offener Sicherheitsfragestellungen und der als ungelöst anzusehenden Abrechnungsproblematik liegen jedoch in den aktuell zugänglichen UDDI-Diensten kaum kommerzielle Dienstangebote vor, sondern überwiegend Testeinträge.
| Web-Referenzen 13: Weiterführende Links |
|
![]()
5
PräsentationsaspekteBeim Einsatz von Servlets ist oftmals das Verhältnis zwischen berechneten Anteilen und statisch produzierten
Ausgaben deutlich zu Gunsten der statischen Anteile verschoben. Gleichzeitig ist jedoch die Ausgabe statischen
HTML- oder XML-Codes vergleichsweise mühsam und schreibaufwendig, wie Beispiel
102 zeigt.
Zur Abhilfe dies vermeidbaren Aufwende und damit zur Unterstützung von Applikationstypen in denen die dynamisch
festzulegenden Anteile einer Ausgabe deutlich gegenüber den statischen zurückstehen sieht Sammlung
der J2EE-Applikationstypen die Java Server Pages (JSP) vor.
Konzeptionell stellt eine Server Page eine --- gegenüber klassischem HTML/XML nahezu unveränderte ---
Ausgabeseite dar, in die Anweisungen eingestreut werden können, welche zur Auslieferungszeit an den Client
durch ihr Berechnungsergebnis ersetzt werden.
Technisch ist der Ansatz auf Basis der existierenden Servlet-API realisiert und wird serverseitig auch transparent
in ein solches übersetzt. Als einzige Einschränkung gegenüber der Mächtigkeit des Servletansatzes ist jedoch
die Beschränkung auf die Verarbeitung von HTTP-POST-Anfragen zu sehen.
Beispiel 115 zeigt die Reformulierung der Servlet-basierten Umsetzung aus Beispiel 102 als JSP:
| Beispiel 115: Einfache JSP |
Download des Beispiels |
![]()
Augenfälligste Änderung gegenüber der Fassung als Servlet ist die direkte Darstellung der HTML-Ausgabeelemente.
Die aktiven Inhalte werden durch Elemente, die mit dem Zeichen „%=“ beginnen und mit
„%“ enden eingeschlossen. Dazwischen befindet sich übersetzbarer Java-Quellcode.
Etwaige benötige Bibliotheken werden im Java-üblichen import-Stil angegeben und zu Beginn der JSP-Seite eingeführt.
Zu Beginn einer JSP-Seite können im Rahmen der page-Deklaration verschiedene seitenglobale Vereinbarungen
getroffen werden:
languageextendsimportsessionbuffernone ist dies PrintWriter.autoFlushisThreadSafetrue auf, dann werden durch die Ausführungsumgebungen mehrere
Anfragen zur selben Zeit an die JSP (bzw. das entstehende Servlet) übergeben.infoerrorPageisErrorPageDie nähere Analyse des Quellecodes von Beispiel 115 sowie die Semantik
der vorgestellten Attribute offenbart zwei unterschiedliche Codierungsformen für JSPs.
Zunächst die durch <@
eingeleiteten vordefinierten Direktiven, welche im Rahmen des Serveltübersetzungsprozesses in Java-Code transformiert
werden. Diese Codeabbildung wird durch eine sog. Tag Library, einer Sammlung von Javacodefragementen und
-transformationsvorschriften zur dynamischen Erzeugung der Ausgabe, gesteuert.
Zum zweiten gestattet der JSP-Mechanismus die direkte Darstellung von Java-Quellcode, der zur Laufzeit direkt in ausführbaren
Code umgesetzt wird im Rahmen der sog. Scriptlets. Diese durch <% eingeführten Codeanteile
werden unverädert in das entstehende Servlet einkopiert.
Zusätzlich stellt das Beispiel, durch <= eingeleitete, Ausdrücke (Expressions) dar, deren Resultatwert durch die Laufzeitumgebung
in die an den Client übermittelte Seite eingefügt wird.
Im Beispiel nicht dargestellt sind Variablen- oder Konstantendeklarationen, welche auf die Einleitungssequenz <%! folgen.
Zur Strukturierung des Entwurfs und zur Wiederverwendung bereits einmal eingesetzter Codesequenzen für JSPs
existiert mit dem Mechanismus der Tag Libraries die Möglichkeit anwenderdefiniert den Sprachumfang der Server Pages zu
erweitern.
Einige häufig gebrauchte Aktionen sind bereits in der im Standardumfang enthaltenen Bibliothek versammelt:
useBeansetPropertyuseBean verwendet um
Bean-Eigenschaften festzulegen.getPropertyparamincludeforwardpluginBeispiel 116 zeigt mit der include-Direktive die vordefinierte
JSP-Aktion zur serverseitigen Inklusion existierender Dateien.
| Beispiel 116: Importmechanismus für Server Pages |
Download des Beispiels |
![]()
Die Erzeugung eigener Tag Libraries geschieht durch Erstellung einer Java-Klasse, welche die Schnittstelle
javax.servlet.jsp.tagext.Tag implementiert. Zumeist wird jedoch die Klasse TagSupport
spezialisiert, die einige zusätzliche Methoden definiert, welche die Erstellung vereinfachen.
Beispiel 117 zeigt die Umsetzung des anwenderdefinierten Tags hello
und Beispiel 118 seine Anwendung.
| Beispiel 117: Erstellung einer Tag Library |
Download des Beispiels |
![]()
Das Beispiel definiert Methoden für die beiden durch die Schnittstelle vorgegebenen Operationen doStartTag
und doEndTag, die bei der Verarbeitung der entsprechenden Tag-Anteile aufgerufen werden. Der Rückgabewert
der Methoden legt fest, daß die Inhalte des anwenderdefinierten Elements in der JSP-Seite in den Ausgabestrom übernommen werden
(EVAL_BODY_INCLUDE) bzw. das mit der Verarbeitung der Seite fortgefahren werden soll (EVAL_PAGE).
| Beispiel 118: Nutzung eines anwenderdefinierten Tags |
Download des Beispiels |
![]()
Abschließende Bemerkung:
Der JSP-Mechanismus eignet sich sehr gut zur schnellen Erstellung leistungsfähiger Anwendungen einer gewissen Komplexität
jedoch wirkt sich die physische Kopplung des Kontrollflusses an die erzeugte Ausgabe durch die Ablage in derselben Datei
negativ auf die Skalierbarkeit hinsichtlich der betrachteten Problemgröße aus. Durch die mangelnde zentralisierte
Verwaltbarkeit lassen sich komplexe Anwendungen oft nur noch schwer überschauen und testen.
Zusätzlich wirkt sich die erst zum Aufrufzeitpunkt serverseitig vorgenommene Übersetzung in ein Servlet nicht nur negativ
auf die Laufzeit aus, sondern erschwert zusätzlich die Fehlersuche, da Syntaxfehler erst beim Aufruf entdeckt werden
können.
Die prominenteste Verwendung der XPath-Pfadausdrücke und eine der in jüngerer Zeit am weitesten beachteten XML-Vokabulare dürfte XSLT -- die Sprache der XSL Transformations -- sein. Sie wurde im Verlauf der Standardisierung der Stylesheetsprache XSL von dieser abgetrennt und seither durch eine eigene W3C-Arbeitsgruppe vorangetrieben.
In einem Satz zusammengefaßt stellt sie eine Turing-vollständige funktionale Programmiersprache zur Transformation wohlgeformter XML-Dokumente in beliebige Unicode-Streams -- und damit im speziellen wiederum in XML-Dokumente -- dar.
Der Begriff Transformationen bezeichnet hierbei die Selektion einzelner Bestandteile des Quelldokuments, deren Umordnung sowie die Ableitung neuer Inhalte aus den bereits bestehenden.
Derzeit aktuell ist die Recommendation zur Version 1.0 von Herbst 1999. Intern arbeitet das W3C bereits an der Nachfolgerversion XSLT v2.0, welche auch die absehbaren Entwicklungen des Umfeldes, wie XPath v2.0 oder XML-Schema, berücksichtigen wird.
Jedes XSLT-Stylesheet ist ein gültiges XML-Dokument, in dem alle Elemente der Sprache XSLT im Namensraum http://www.w3.org/1999/XSL/Transform plaziert sind.
Üblicherweise wird der Namensraum an das Präfix xsl gebunden, welches allen XSLT-Sprachelementen explizit vorangestellt wird.
Das Wuzelelement eines XSLT-Dokuments bildet der Knoten stylesheet. Alternativ kann auch transform angegeben werden. Zusätzlich verfügt jedes Stylesheet über ein Versionsattribut zur Bezeichnung der verwendeten XSLT-Version.
Das Beispiel zeigt ein minimales Stylesheet
| Beispiel 119: Ein minimales Stylesheet |
Download des Beispiels |
![]()
Angewendet auf das Beispieldokument der Projektverwaltung liefert es folgende Ausgabe:
(1)<?xml version="1.0" encoding="utf-8"?>
(2)Hans Hinterhuber
(3)Franz Xaver Obermüller
(4)IT-Kompetenz verschiedene Betriebssysteme und professionelle Programmierung verschiedener Programmiersprachen
(5)Entwickler von 1988-1990 Projektleiterfunktion von 1990-93 im X42-Projekt in Abteilung AB&amp;C
(6)Fritz Meier
Dies mag zunächst verwundern, definiert doch das Beispiel-Stylesheet keinerlei Transformationsregeln oder Ausgabefunktionen.
Das Ergebnis des minimal-Beispiels wird durch die eingebauten Vorgaberegeln erzeugt. Diese geben, sofern nicht anders angegeben alle Character Information Items unverändert aus.
Durch Überschreiben dieser Vorgaben und die Definition eigener Regeln lassen sich komplexe Transformationen auf dem Eingabedokument verwirklichen.

Die Graphik zeigt den Aufbau einer Transformationsschablone. Ihre beiden Hauptbestandteile sind der Lokalisierungspfad und das Ersetzungsmuster.
Der Lokalisierungspfad (in der Spezifikation als pattern bezeichnet) liefert eine Knotenmenge. Als Syntax wird eine eingeschränkte Variante der Lokatorsprache XPath verwendet.
Augenfälligster Unterschied zur bisherigen Notation ist die Optionalität der descendant-Achse (zumeist zu // verkürzt) zur hierarchiebenenunabhängigen Lokalisierung eines Knotens.
Im Rumpf des Musters legt das Ersetzungsmuster diejenige Zeichenfolge fest, die statt jedem Element der lokalisierten Knotenmenge ausgegeben werden soll.
Das nachfolgende Transformationssheet liefert angewandt auf das Projektverwaltungsbeispiel dreimal die Ausgabe Person gefunden!; für jedes Auftreten des Knotens Person in der Eingabe.
| Beispiel 120: Eine einfache Transformation |
Download des Beispiels Download der Ergebnisdatei |
![]()
Innerhalb des Ersetzungsmusters können im Allgemeinen beliebige Textsequenzen angegeben werden. Insbesondere ist die Verwendung wohlgeformter XML-Fragmente zugelassen.
Textsequenzen werden hierbei durch direktes Anschreiben, oder umschlossen durch das Element xsl:text definiert.
Anmerkung: Die Anforderungen an die Wohlgeformtheit sind hierbei auf die korrekte Terminierung der Elemente (damit einhergehend ihre korrekte Schachtelung), sowie die Quotierung der Attribute beschränkt.
Im folgenden Beispiel wird jedes Element des Typs Person durch ein leeres Mitarbeiter-Element ersetzt.
Das Beispiel erklärt auch die übliche Anwendungspraxis, alle XSLT-Elemente durch Namensraumpräfix zu qualifizieren, statt der -- weniger schreibaufwendigen -- Überschreibung des Vorgabenamensraumes. Würde der Vorgabenamensraum mit der Namensraum-URI der XSL-Transformations belegt, so befände sich auch jedes XML-Element und -Attribut innerhalb des Ersetzungsmusters in diesem Namensraum. Als Konsequenz würde der XSLT-Prozessor die Transformation wegen des Auftretens ungültiger (d.h. nicht in der XSLT-Sprache enthaltener) Elemente ablehnen. Bei Redefinition des Vorgabenamensraumes müßte daher für alle Elemente, die nicht Bestandteil von XSLT sind, eine explizite Namensraumdefinition im Element erfolgen, wodurch die Lesbarkeit stark herabgesetzt würde.
| Beispiel 121: Erzeugung einer XML-Ausgabe |
Download des Beispiels Download der Ergebnisdatei |
![]()
Erwartungsgemäß liefert das Beispiel dreifach das leere Element Mitarbeiter anstelle der Personen-Elemente der Eingabe.
Die bisher genutzte Form der Ersetzung ist jedoch für die praktische Anwendung in nur äußerst wenigen Fällen geeignet, da sie keine Übernahme von Daten der Eingabedatei in die Ausgabe erlaubt.
Dieses Manko wird durch das XSLT-Sprachelement value-of behoben.
Das Element value-of übernimmt als Teil des Ersetzungsmusters frei selektierbare Text-artige Informationsknoten aus dem Quelldokument. Die Lokalisierung der zu übernehmenden Knoten erfolgt durch XPath-Syntax innerhalb des select-Attributs.
Im folgenden Beispiel wird der Inhalt der Personen-Knoten in den neuen Knotentyp Mitarbeiter übernommen.
| Beispiel 122: Übernahme bestehender Information aus dem Quelldokument |
Download des Beispiels Download der Ergebnisdatei |
![]()
Das Resultat liefert jedoch nicht das Quelldokument, unter Umbenennung der Personen-Knoten in Mitarbeiter, sondern die dargestellte Textsequenz.
(1)<?xml version="1.0" encoding="utf-8"?>
(2)<Mitarbeiter>Hans Hinterhuber</Mitarbeiter>
(3)<Mitarbeiter>Franz Xaver Obermüller IT-Kompetenzverschiedene Betriebssysteme und professionelle
(4)Programmierung verschiedener Programmiersprachen Entwickler von 1988-1990 Projektleiterfunktion
(5)von 1990-93 im X42-Projekt in Abteilung AB&amp;C</Mitarbeiter>
(6)<Mitarbeiter>Fritz Meier</Mitarbeiter>
Die Lösung liegt in der Definition des value-of-Elements. Es konvertiert alle durch den im select-Attribut bezeichneten XPath lokalisierten Knoten in ihre Textrepräsentation. Im vorliegenden Beispiel ist dies der Inhalt der Knoten des Typs Person, der durch den Elementinhalt gebildet wird. Der Elementinhalt wird hierbei durch alle Kindknoten und deren Attribute gebildet.
Zur unveränderten Übernahme eines vollständigen Elements einschließlich der Auszeichnungssymbole wird das XSLT-Element copy-of angeboten.
Das nachfolgende Beispiel modifiziert das vorhergend diskutierte Stylesheet dergestalt, daß für alle Personen-Knoten zunächst ein öffnender Mitarbeiter-Tag gesetzt wird. Im Rumpf des so begonnenen Elements werden durch das copy-of-Element alle Kindknoten der aktuellen Knotenmenge unverändert kopiert.
Als zusätzliche Veränderung gegenüber dem vorigen Beispiel fällt die Nutzung der child-Achse im select-Attribut des copy-of-Elements auf. Dies ist notwendig, da durch den Lokalisierungspfad der Schablone alle Personen-Knoten zu einer Ergebnisknotenmenge zusammengefaßt werden. Die Anwendung der self-Achse innerhalb des copy-of-Elements würde daher auch die Personen-Knoten selbst übernehmen.
Zusammenfassend läßt sich die Funktionalität des Beispiels mit Umbenennung aller Elemente des Types Person in Mitarbeiter wiedergeben.
| Beispiel 123: Kopieren vollständiger Elementknoten |
Download des Beispiels Download der Ergebnisdatei |
![]()
Die vorgestellte Transformationsvorschrift ist hinreichend flexibel für Knoten des Typs Person auf beliebiger Hierarchiestufe des Eingabedokuments. Jedoch versagt sie bereits beim Versuch einen weiteren Transformationsschritt einzubauen, der auf einem der unverändert kopierten Kindelemente von Person operiert.
Das folgende Stylesheet stellt einen flexibleren Ansatz zur Umbenennung von einzelnen Knoten vor.
Gegenüber der vorhergehenden Fassung ist der Umfang um zwei weitere template-Elemente erweitert. Eines, das für alle Qualifikationsprofil-Knoten angewendet wird und eines für alle anderen Knoten. Der dort eingesetzte Lokalisierungspfad liefert als Ergebnismenge die Vereinigung aller Attributknoten (attribute::*) mit allen Knoten außer dem Wurzelknoten (node()-Funktion). Im Rumpf des Elements wird das copy-Element zur Kopie jedes Elements verwendet. Anders als das bisher herangezogene copy-of-Element übernimmt diese Variante ausschließlich das aktuelle Element in das Ergebnisdokument und läßt eventuell vorhandene Kindelemente unberücksichtigt.
Das template-Element mit dem Lokalisierungspfad Qualifikationsprofil verfügt über kein Ersetzungsmuster. Es bewirkt damit die Unterdrückung des Teilbaumes unterhalb aller Knoten des Typs Qualifikationsprofil.
Die korrekte Anwendung der verschiedenen Schablonen wird durch den ausführenden XSLT-Prozessor gewährleistet, er ermittelt anhand der Lokalisierungspfade das best-passendste Template und bringt es zur Ausführung. Wenn, wie im vorliegenden Beispiel, mehrere Pfadausdrücke einen Knoten des Eingabedokuments lokalisieren, so wird das am weitesten spezifizierte Muster ausgewählt. Im untenstehenden Beispiel gilt dies für alle Elemente des Typs Person. Jeder dieser Knoten ist sowohl durch den XPath-Ausdruck der ersten Schablone als auch durch den allgemeineren Ausdruck node() zugänglich. Der explizite Pfad Person des ersten Lokalisierungsmusters ist jedoch gegenüber der Ergebnismenge der node-Funktion (deutlich) spezifischer.
Da jeder Knoten, außer denen des Typs Person und Qualifikationsprofil, unverändert in den Ausgabestrom übernommen werden soll, wird im Beispiel wieder ein copy-Element eingesetzt. Im Unterschied zum bisher verwendeten copy-of jedoch mit der Einschränkung, daß copy nur den aktuellen Knoten kopiert und eventuell existierende Kindknoten unberücksichtigt läßt. Dieser Vorgang wird auch als shallow copy bezeichnet.
apply-templates-ElementeStandardmäßig durchläuft ein XSLT-Prozessor den aus dem Eingabedokument erzeugten Baum ausgehend vom Wurzelknoten in Preorder Reihenfolge. Während des Traversierungsvorganges werden die zum jeweiligen Knoten „passenden“ Schablonen ausgewertet. „Passend“ deutet hierbei auf das Enthaltensein des besuchten Knotens in der Ergebnismenge eines XPath-Ausdrucks innerhalb eines match-Attributes hin.
Jedoch ist auch die anwenderdefinierte Beeinflussung der vorgegebenen Abarbeitungsreihenfolge möglich. Hierzu enthält das Beispiel zwei apply-templates-Elemente. Diese lösen einen Rekursionsschritt aus, dergestalt, daß an jeder Stelle, an der sich ein apply-templates-Aufruf findet, der Prozessor versucht, weitere passende Schablonen anhand der angegebenen Lokalisierungspfade zu ermitteln. Diese können an der gegebenen Stelle ausgewertet werden. Der Vorgang entspricht damit der Substitution in funktionalen Programmiersprachen.
Im vorliegenden Fall wird nach Ausgabe des öffnenden Tags Mitarbeiter -- nachdem ein Personen-Knoten im Eingabedokument ermittelt wurde -- nach weiteren Knoten im Eingabedokument gesucht, zu denen Lokalisierungspfade in der XSLT-Transformationsvorschrift existieren. Dies ist für alle Attribute und Kindknoten von Person der Fall, da sie durch den Lokalisierungspfad attribute::*|node() zugänglich sind. So wird innerhalb des neu erzeugten Elements Mitarbeiter des Ausgabestroms das Ersetzungsmuster ausgeführt, das die Elemente und Attribute mit ihren Inhalten unverändert übernimmt.
Als Besonderheit nutzt das apply-templates-Element im „allgemeinen“ (dritten) template das Attribut select. Es erlaubt die anwenderdefinierte Steuerung der Menge, innerhalb der nach weiteren passenden Lokalisierungspfaden gesucht werden soll. Standardmäßig ist diese Menge mit allen dem aktuellen Element nachfolgenden (following-Achse) Elementknoten gefüllt. Im vorliegenden Beispiel wird sie durch den XPath des Attributwertes um alle Attributknoten erweitert.
| Beispiel 124: Flexible Umbenennung und Löschung von Elementen |
Download des Beispiels Download der Ergebnisdatei |
![]()
| Übung 3: Verfolgung der Aufrufreihenfolge |
Lassen Sie sich mit von einem XSLT-Prozessor die Aufrufreihenfolge der einzelnen Templates ausgeben. Beispielsweise mit dem Prozessor Xalan aus dem Apache-Projekt. |
![]()
Neben den Lokationspfad-gesteuerten Schablonen kann der Anwender auch benannte Schablonen, ohne match-Attribut, definieren. Diese werden während der Abarbeitung des Eingabebaumes nicht berücksichtigt, sondern müssen manuell durch call-template aufgerufen werden.
Konzeptionell entsprechen sie Funktionsaufrufen herkömmlicher Programmiersprachen.
(In Spezifikation nachschlagen).
Die Definition erfolgt analog den bisher genutzten Schablonen, mit der Ausnahme, daß statt dem match-Attribut ein eindeutiger Name (Attribute name) angegeben wird.
Als neuer Freiheitsgrad beim nun notwendigen manuellen Aufruf tritt die Möglichkeit der Parameterübergabe hinzu. Als Parameter können beliebige Dokumentbestandteile als Knotenmenge, Ergebnisse von Funktionsausdrücken oder Konstanten übergeben werden.
Eine Parameterrückgabe ist nicht möglich, sie wird durch den Anteil der Schablone an der Ausgabe realisiert.
Die Aufrufsyntax lautet:
(1)<xsl:call-template name="QName">
(2) <!-- Content: xsl:with-param* -->
(3)</xsl:call-template>
(4)<xsl:with-param name="QName" select="eingeschränkter XPath-Ausdruck">
(5) <!-- Content: template -->
(6)</xsl:with-param>
Anmerkung: Wie in allen funktionalen Sprachen kommt den Funktionen dieses Typs besondere Bedeutung, als Ausgangspunkt rekursiver Aufrufe, zu.
Das einführende Beispiel dieses Kapitels griff bereits auf die in den XSLT-Prozessor „eingebauten“ Standard-Transformationsvorschriften (built-in templates) zurück.
So lautet die Definition, welche für alle Text- und Attributknoten der Eingabe den Inhalt in die Ausgabe kopiert:
(1)<xsl:template match="text()|@*">
(2) <xsl:value-of select="."/>
(3)</xsl:template>
Ferner existiert ein template zur rekursiven Abarbeitung des Eingabebaumes, welches immer dann Anwendung findet, wenn sich keine spezialisiertere Transformationsvorschrift findet.
(1)<xsl:template match="*|/">
(2) <xsl:apply-templates/>
(3)</xsl:template>
Ergänzt wird diese Zusammenstellung durch eine Schablone zur Eliminierung von Namensraum- und Kommentarknoten.
Ähnlich zu herkömmlichen Programmiersprachen bietet auch XSLT Sprachmittel zur Selektion und bedingten Verarbeitung, abhängig von den Eingabedaten.
So erlaubt das if-Element die Bearbeitung der umschlossenen Elemente nur, wenn die im test-Attribut formulierte Boole'sche Bedingung wahr ist.
(In Spezifikation nachschlagen)
Die Syntax lautet:
<xsl:if test="Boole'scher Ausdruck"> <!-- Content: template --> </xsl:if>
Das Beispiel zeigt die Nutzung des if-Elements. Verfügt ein Knoten des Typs Person über mehr als einen Kindknoten des Typs Vorname so wird der Inhalt des if-Elements abgearbeitet, der durch das XSLT-Element message während des Transformationsvorganges eine Bildschirmausgabe erzeugt.
Diese gibt zunächst den Inhalt des Nachnamen Knotens gefolgt von einem statischen Text aus.
Angewandt auf das Beispieldokument liefert es auf Kommandozeile die Ausgabe: Obermüller hat mehr als einen Vornamen!. Der Inhalt des Eingabedokuments wird unverändert kopiert.
| Beispiel 125: Bedingte Verarbeitung durch Verwendung des if-Elements |
Download des Beispiels Download der Ergebnisdatei |
![]()
In Erweiterung der simplen Selektion bildet choose die Möglichkeiten einer Mehrfachselektion, oder einer simplen if-then-else-Struktur ab.
(In Spezifikation nachschlagen)
Die Syntax lautet:
(1)<xsl:choose>
(2) <!-- Content: (xsl:when+, xsl:otherwise?) -->
(3)</xsl:choose>
(4)<xsl:when test="Boole'scher Ausdruck">
(5) <!-- Content: template -->
(6)</xsl:when>
(7)<xsl:otherwise>
(8) <!-- Content: template -->
(9)</xsl:otherwise>
Das Beispiel zeigt die Transformation des Beispieldokuments in eine XHTML-Ausgabe.
Hierbei wird zunächst der XHTML-Dokumentrahmen bei Auftreten des Dokumentknotens (Suchmuster /) erzeugt. Nach dem öffnenden XHTML-Rumpfelement body werden innerhalb des Quelldokuments wahlfrei weitere, auf eines der angegebenen Suchmuster passende, Knoten gesucht (apply-templates-Aufruf).
Bei Auftreten des Knotens ProjektVerwaltung wird -- nach einigen Überschriftszeilen -- der Kopf einer XHTML-Tabelle, bestehend aus den Elementen table und der Kopfzeile (eingeschlossen durch tr), erzeugt. Den Rumpf der Tabelle schreibt ein anderes Template. Dieses wird jedoch nicht direkt aufgerufen, sondern der Prozeß der Ermittlung neuer „passender“ Knoten neu initiiert; jedoch diesmal, durch das select-Attribut des apply-templates-Elements, nur auf Knoten des Typs Person beschränkt.
Die Ersetzungsregel für Person speichert zunächst den Inhalt des Attributs PersID in einer Variable. Anschließend werden die Tabellenelemente der in der Ersetzungsregel für ProjektVerwaltung geöffneten Tabelle geschrieben. Hierzu werden nacheinander die Ersetzungsmuster für Knoten des Typs Vorname bzw. Nachname, die Kindknoten des aktuellen Knotens sind (die PersID des aktuellen Personen-Knotens findet sich in der zuvor belegten Variable), aktiviert.
Ein zweites Tabellenelement enthält einen XHTML-Hyperlink zu den durch den Mitarbeiter bearbeiteten Projekten. Als Sprungziel wird hierbei der Inhalt des Attributs mitarbeitInProjekt eingetragen.
Das Ersetzungsmuster Vorname übernimmt durch value-of die in einen Zeichenkettenwert gewandelten Inhalte des Elements. Zusätzlich existiert ein zweites Ersetzungsmuster für Knoten des Typs Vorname, das jedoch durch ein Prädikat nur auf das zweite und alle folgenden Elemente dieses Typs angewendet wird. Es gibt vor der Übernahme des Elementinhaltes ein Leerzeichen aus.
Das Element Nachname bettet den Elementinhalt in eine benannte Sprungreferenz ein. Zur Erzeugung der dokumentweiten eindeutigen Benennung wird die Funktion generate-id herangezogen, die für jedes Element des Information Sets des Eingabedokuments einen eindeutigen Bezeichner liefert.
Nach Abschluß der Tabellengenerierung im durch den Lokalisierungspfad ProjektVerwaltung gekennzeichneten Template werden durch den Aufruf des benannten Ersetzungsmusters wasteSpace 25 Leerzeilen, jeweils gefüllt mit der Zeichenkette „...“, erzeugt. Als Besonderheit ist in diesem Muster sehr deutlich die Nutzung der Rekursion zur Modellierung einer Schleife zu sehen.
Zum Abschluß wird nochmals eine Tabelle, nun mit den Mitarbeitern und ihren Projekten, erzeugt.
| Beispiel 126: Erzeugung eines XHTML-Reports |
Download des Beispiels Download der Ergebnisdatei |
![]()
Die nachfolgende XSLT-Transformation ermittelt zu jedem beliebigen Element- und Attributknoten (Muster: * bzw. @*) die zugehörige Namensraum-URI (Funktion namespace-uri) und gibt sie gemeinsam mit dem Namen des Knotens (Funktion name) in einer XML-formatierten Ausgabe aus.
Zur Neuselektion aller weiteren Element- und Attributknoten wird apply-templates mit dem Musterausdruck @*|node() ausgeführt, um in die Prüfung nach weiteren passenden Knoten (node()) auch explizit alle beliebigen Attribute (@*) einzubeziehen. Standardmäßig ermittelt apply-templates weitere passende Knoten nur innerhalb der Elemente eines Dokuments.
| Beispiel 127: Ausgabe Namensräume jedes Elements und Attributs eines beliebigen XML-Dokuments |
Download des Beispiels |
![]()
| Web-Referenzen 14: Weiterführende Links |
![]()
| Übung 4: Textuelle Aufbereitung der Baumstruktur eines XML-Dokuments |
Schreiben Sie eine XSLT-Transformation, die es erlaubt die Elementstruktur beliebiger wohlgeformter XML-Dokumente in Form eines „ASCII-Baums“ (siehe Beispiel) am Bildschirm auszugeben. Beispiel: Eingabe: |
![]()
6
Sicherheitsaspekte Definitionsverzeichnise-Business
Gültigkeit hinsichtlich eines Schemas
Lokalisierungsschritt
Namensräume
Namensraumidentifikation
Namensraumvererbung
Web Service
Wohlgeformtes XML-Dokument
XML Dokument
XML Information Set
XML-Prozessor
XML-Sprache
SchlagwortverzeichnisB2B
B2C
B2E
Business-to-Business
Business-to-Customer
Business-to-Employee
e-Business
e-Commerce
entfernte Methodenaufruf
e-tailing
Internettechniken
Java Database
Connectivity
Java Message Service
JDBC
JDBC-Treiber
lazy activation
message-oriented Middleware
ODBC
Open
Database Connectivity
Remote Method Invocation
Skeleton
SQL/CLI
SQL Call Level
Interface
Stub
Typ 1
Treiber
Typ 2 Treiber
Typ 3 Treiber
Typ 4 Treiber
AbbildungsverzeichnisDimensionen des e-Business
Architektur moderner e-Business Applikationen
JDBC-Treibertypen
Zentrale JDBC-Klassen der Java-API
JDBC-Geschwindigkeitsvergleich
Aufrufstruktur einer zustandslosen EJB
Grundlegende Struktur der JDO-API
Erzeugung und Anreicherung des Bytecodes
Mögliche Status JDO-verwalteter Objekte
Vergleich zwischen den diskutierten Persistenztechniken
Physische Architektur Nachrichten-orientierter Middleware
Logische Architekturkomponenten einer Nachrichten-orientierter Middleware
Verteilungsstruktur einer RMI-Applikation
Struktur der Servlet-API
Verzeichnis der BeispieleEin erstes XML-Dokument
Element mit deklariertem Namensraum
Verschiedene Kommentarstrukturen
Verschiedene Processing Instructions
Beispiel eines Dokuments mit Namensräumen
Ein nicht wohl-geformtes XML-Dokument
Ein Rechnungsdokument
Eine alternative Rechnungsstruktur
Gültige URIs
Dokument mit W3C-konformen Namensräumen
Ein XHTML-Dokument mit MathML- und SVG-Inhalten
Rechnungsdokument mit überschriebenem Vorgabenamensraum
Ein XHTML-Dokument mit MathML- und SVG-Inhalten, unter Verwendung überschriebener Vorgabenamensräume
Namensraumpräfixe 1
Namensraumpräfixe 2
Namensräume im realen Einsatz
Präzedenzregel
Aufheben von Namensraumdeklarationen
Namensräume für Attribute
Definition einer Schemareferenz
Einige Elementdefinitionen
Nutzung benannter komplexer Typen
Einschränkende Typableitung
Erweiternde Typableitung
Ableitung eines komplexen Typen von einem Simplen
Einschränkende Spezialisierung eines simplen Typen
Bildung eines Aggregationstypen
Einige Attributdefinitionen
Vollständiges XML-Schema der Projektverwaltung
Gültiges Projektverwaltungsdokument
XPath-Ausdruck zur Lokalisierung aller Vornamen
Platzhalter in Lokalisierungsschritten
Hierarchieunabhänigige Knoten-Lokalisierung
Selektion unter Anwendung eines Prädikats
Schrittweise Berechnung einer Selektion unter Verwendung mehrerer Prädikate
Erweiterte Projektverwaltung
Unique-Einschränkung
Zusammengesetzter Schlüssel innerhalb eines unique-Elements
Schlüsselbasierte Referenzierung
Ermittlung von Fehlerdetails
Standard-API-konforme Ermittlung von Fehlerdetails
Aufbau einer Datenbankverbindung
Ermittlung von Informationen über Treiber und Treibermanager
Ablage von Verbindungsinformation in einem JNDI-Verzeichnis
Verbindungsaufbau unter Nutzung von JNDI
Verbindungsaufbau unter Nutzung von Connection Pooling
Erstellung einer neuen Tabelle
Modifikation der Tabellendefinition
Einfügen von Werten
Einfügen von Werten mittels eines Batches
Aktualisieren von Tabellendefinitionen und Werten
Aktualisieren von Tabellendefinitionen und Werten
Auslesen von Daten und Metadaten
Auslesen von Daten in invertierter Reihenfolge
Auslesen von Daten in wahlfreier Reihenfolge
Auslesen und Einfügen von Daten
Modifizieren von Daten
Löschen von Daten
Test auf geänderte Daten
Zugriff auf ein mengenwertiges Attribut
Verarbeitung unstrukturierter Binärdaten
Transaktionsverarbeitung
Transaktionsverarbeitung mit Sicherungspunkten
JDBC-artige Verarbeitung von XML-Dateien
Home-Schnittstelle einer EJB
Remote-Schnittstelle einer EJB
Realisierung einer Session Bean
Zugriff auf eine Session Bean
Home-Schnittstelle einer Entity Bean
Remote-Schnittstelle einer Entity Bean
Eine Entity Bean
Client der auf eine Entity Bean zugreift
Deployment Deskriptor der Entity Bean
Konfiguration einer JDO-Implementierung
Erzeugung eines persistenten Objektspeichers
Zu persistierende Javaklasse
Parametrisierung der Objektpersistenz
Parametrisierung der Objektpersistenz und Definition eines Primärschlüssels
Speicherung von Objekten mit JDO
Transaktionen mit JDO
Schreiboperation ohne Transaktionsschutz
Traversierung des Objektbestandes
Anfrage auf den persistenten Objektbestand mittels OQL
Löschen eines Objektes aus dem persistenten Objektbestand
Konfiguration der JDO-Implementierung TJDO
Parametrisierung der Objektpersistenz
Versand einer Nachricht
Empfang einer Nachricht
Versand einer Nachricht
Empfang einer Nachricht
Empfang einer Nachricht durch eine Message-driven Bean
Die Schnittstelle HelloInterface
Die Klasse HelloServer
Die Klasse HelloClient
Die Klasse ActivatableHelloInterface
Die Klasse ActivatableHelloServer
Die Klasse ActivatableHelloClient
Die Klasse ActivatableSetup
Die Klasse HelloImpl
Ein einfaches Servlet
Ein einfacher Dienst
Verschiedene Servletmethoden
Ein vollständiger SOAP-Aufruf
Nutzung der SOAP-Kopfelemente
Nutzung des SOAP-Rumpfelements
Nutzung des SOAP-Rumpfelements
Beispielwebdienst
Deploymentdeskriptor des Beispieldienstes
Aufruf des Beispielwebdiensts
SOAP-Nachricht zum Aufruf des Beispieldienstes
SOAP-Nachricht zur Übermittlung des Berechnungsergebnisses des Beispieldienstes
WSDL-Beschreibung des Beispieldienstes
Einfache JSP
Importmechanismus für Server Pages
Erstellung einer Tag Library
Nutzung eines anwenderdefinierten Tags
Ein minimales Stylesheet
Eine einfache Transformation
Erzeugung einer XML-Ausgabe
Übernahme bestehender Information aus dem Quelldokument
Kopieren vollständiger Elementknoten
Flexible Umbenennung und Löschung von Elementen
Bedingte Verarbeitung durch Verwendung des if-Elements
Erzeugung eines XHTML-Reports
Ausgabe Namensräume jedes Elements und Attributs eines beliebigen XML-Dokuments
![]()
Service provided by Mario Jeckle
Generated: 2004-06-11T07:12:20+01:00![]() Feedback
Feedback ![]() SiteMap
SiteMap![]() This page's original location: http://www.jeckle.de/vorlesung/eBusinessEng/script.html
This page's original location: http://www.jeckle.de/vorlesung/eBusinessEng/script.html![]() RDF description for this page
RDF description for this page















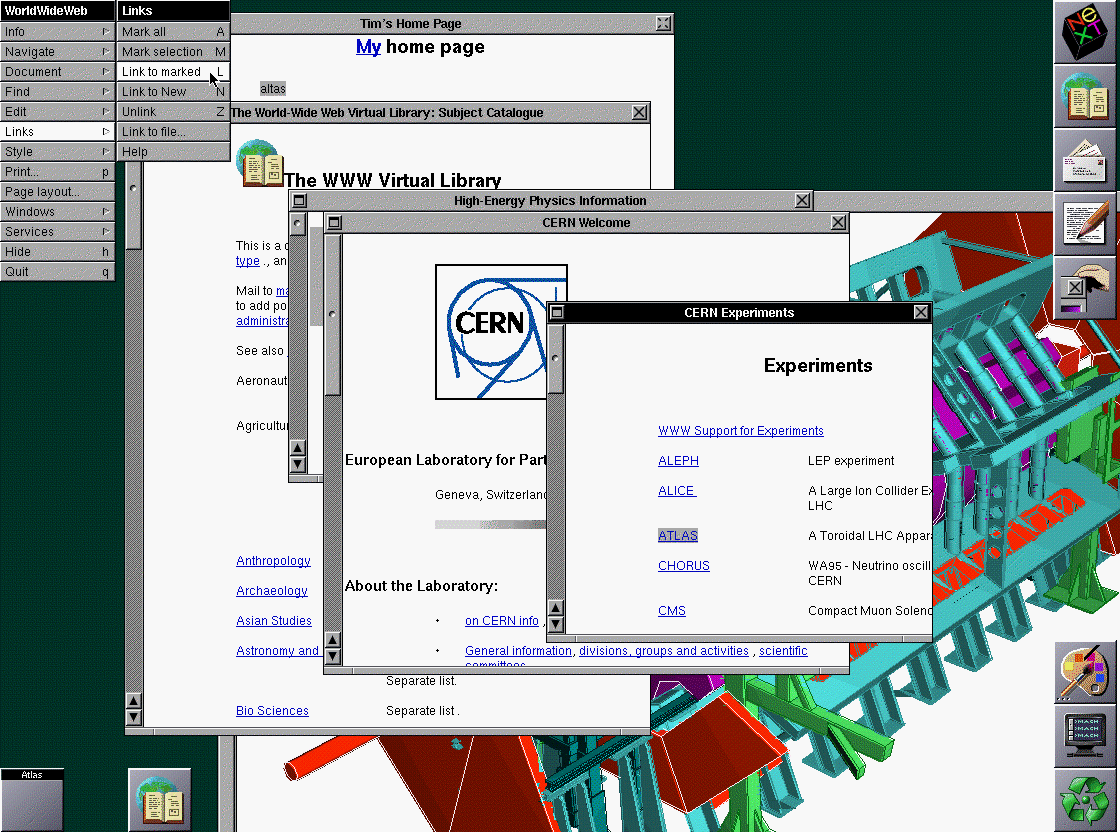{kind=link}